

이전 Accessibility-Based Clustering for Efficient Learning of Locomotion Skills 논문을 리뷰하면서 로봇의 static pose들을 가지고 K-Acc Clustering하는 과정 이후에 Clustering Analysis에서 Inter-cluster accessibility를 Visulization을 하는 부분이 있었습니다.
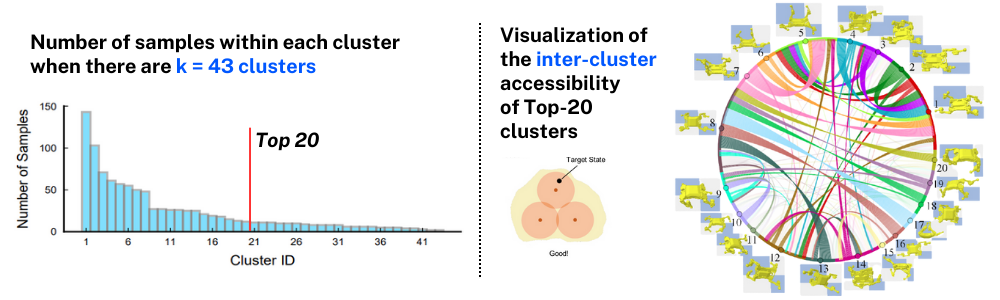
오른쪽에 보이는 그래프가 Chord Graph인데 각 Top-20 cluster에 속한 sample pose들을 하나의 node로 표현하고 각 sample pose들이 다른 pose로 transition되는 시간을 기반으로 계산된 accessiblity 값이 높은 부분은 진한 edge로 accessibility가, 낮은 부분은 옅은 edge로 시각화하여 포즈들 간의 관계성을 보여줍니다. 따라서 이런 시각화를 통해 cluster 간의 inter-cluster accessibility를 파악할 수 있는 것 입니다.(자세한 내용은 이전 논문 리뷰 포스팅을 참고 바랍니다.) 이번 포스팅은 바로 이 Chord graph를 Holoviews라는 파이썬 패키지를 이용해서 시각화 하는 방법에 대해 다룰 것 입니다.
CChord Diagram란 어떤 그래프이고 언제 사용하는 것이 효과적일까요? Chord Diagram은 여러 개체(node) 간의 흐름이나 연결과 같음 상호 관계를 시각적으로 나타내는 다이어그램 입니다. 각 데이터(개체)는 원 형태로 원주에 따라 원형 배치되며 데이터 포인트 간의 관계는 일반적으로 데이터를 연결하는 호(arc/edge)로 그려집니다. 각 호가 개체간의 흐름과 연결을 표현하는 것이고 따라서 방향성이 존재하기 때문에 각 노드에 대한 출발(source)과 도착(target) 정보가 있어야 다이어그램을 그릴 수 있습니다. 그래서 chord diagram으로 시각화 하기 좋은 정보는 이동성/변화/흐름와 같은 데이터셋이라고 볼 수 있습니다. 따라서 Chord Diagram은 이주 연구, 경제적 흐름, 그리고 유전체 연구 등에서 인기가 있는 시각화 방법이며 탐색되지 않은 관계를 강조하여 필터 버블(filter bubbles) 문제를 해결하는 데 도움을 줍니다. 한가지 예시로는 아래와 같이 대륙별 사람들의 이동성을 보여주는 도표를 볼 수 있습니다.
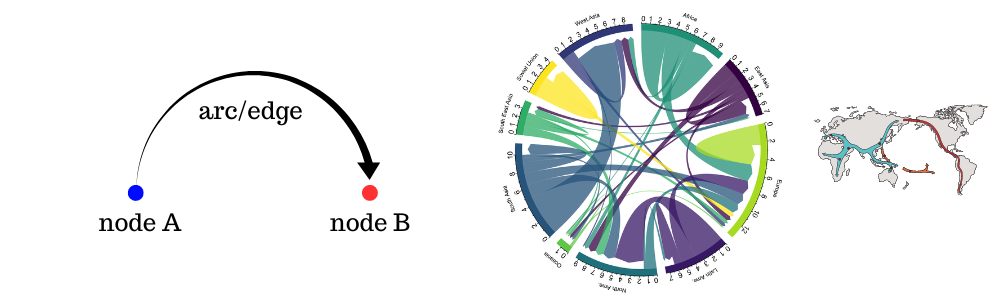
Chord diagram을 그리기 위해서 Holoviews라는 파이썬 시각화 패키지를 이용할 것 입니다. 본격적으로 Chord diagram을 그려보기 전에 우선 Holoviews가 무엇인지 간단히 알아보겠습니다.
Stop plotting your data - annotate your data and let it visualize itself
위와 같은 캐치프레이즈로 만들어진 오픈소스 라이브러리로 데이터 분석과 시각화를 원활하고 간단하게 수행할 수 있도록 해주는 패키지 입니다. Holoviews를 사용하면 몇 줄의 코드로 다양한 유형의 그래프를 생성할 수 있는데, 예를 들어 선 그래프, 산점도, 막대 그래프, 히트맵 등을 손쉽게 만들 수 있습니다. 또한 Holoviews는 다른 시각화 라이브러리인 Matplotlib, Bokeh, Plotly와 함께 사용할 수 있어 더 많은 기능과 유연성을 제공합니다. Holoviews는 다양한 데이터 타입을 지원하며, NumPy 배열, Pandas 데이터프레임, xarray 데이터셋 등과 같은 다양한 형식의 데이터를 처리할 수 있습니다. 또한, 상호작용적인 그래프를 생성할 수 있어 사용자가 그래프를 탐색하고 조작할 수 있는 기능도 제공합니다. 이러한 holoviews 패키지를 이용하기 위해서는 아래와 같이 command를 실행하면 해당 파이썬 패키지가 설치됩니다.
pip install holoviewsHoloviews 패키지를 사용한 이유
Chord graph를 그리기 위한 파이썬 패키지는 Holoviews외에도 다양합니다. 또한 원논문에서 사용한 chord grpah를 그리기 위해 활용한 패키지도 holoviews가 아닙니다. 그럼에도 이번 포스팅에서 holoviews를 이용해서 chord graph를 그리는 법을 소개하는 이유는, 원저자가 사용했던 패키지(공개된 코드나 논문에 명시되어 있지는 않지만 저자에게 직접 여쭤봤었을 때 plotapi로 확인할 수 있었음)는 무료에서 유료화로 전환되어 사용하기 어려워졌고, 다른 파이썬 패키지들은 holoviews보다 사용하기 어렵거나 다른 시각화 라이브러리들과 호환성이 좋지 않기 때문입니다. 하지만 Holoviews의 단점으로 논문의 chord graph를 완벽하게 재현하기 힘든 부분이 있습니다. 앞서 진한/옅은 edge의 표현이 accessiblity의 값에 따라 edge의 transparency(alpha)값을 조절하는 option을 holoviews에서 제공되지 않습니다. 따라서 이후 실습에서 edge_alpha값을 조절하는 부분을 제외한 모든 시각화 절차에 대해서 설명할 예정입니다.
Holoviews에서 제공하는 비행기 항공편 예제로 Chord Graph에 대해서 본격적으로 살펴보겠습니다. 비행기의 이동경로는 출발지와 도착지가 있기 때문에 Chord graph로 그리기에 적절한 데이터셋이라고 할 수 있습니다. 우선 예제 데이터를 bokeh에서 다운로드를 합니다.
필요한 Holoviews의 모듈들을 설치하고 다운받은 bokeh 예제 데이터들 중에서 비행기 항공편을 보여주는 routes와 공항에 대한 정보를 보여주는 airports를 불러옵니다.

routes Dataframe 정보를 살펴보면 출발지에 대한 정보를 담고 있는 SourceID 열과 도착지에 대한 정보를 담고 있는 DestinationID 열을 확인할 수 있습니다.
| Airline | AirlineID | Source | SourceID | Destination | DestinationID | Codeshare | Stops | Equipment | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2O | 146 | ADQ | 3531 | KLN | 7162 | NaN | 0 | BNI |
| 1 | 2O | 146 | KLN | 7162 | KYK | 7161 | NaN | 0 | BNI |
| 2 | 3E | 10739 | BRL | 5726 | ORD | 3830 | NaN | 0 | CNC |
| 3 | 3E | 10739 | BRL | 5726 | STL | 3678 | NaN | 0 | CNC |
airports Dataframe 정보를 살펴보면 각 공항의 아이디 정보를 담고 있는 AirportID 열과 각 공항이 존재하는 도시이름을 알려주는 City 열을 확인할 수 있습니다.
| AirportID | Name | City | Country | IATA | ICAO | Latitude | Longitude | Altitude | Timezone | DST | TZ | Type | source | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3411 | Barter Island LRRS Airport | Barter Island | United States | BTI | PABA | 70.134003 | -143.582001 | 2 | -9 | A | America/Anchorage | airport | OurAirports |
| 1 | 3413 | Cape Lisburne LRRS Airport | Cape Lisburne | United States | LUR | PALU | 68.875099 | -166.110001 | 16 | -9 | A | America/Anchorage | airport | OurAirports |
| 2 | 3414 | Point Lay LRRS Airport | Point Lay | United States | PIZ | PPIZ | 69.732903 | -163.005005 | 22 | -9 | A | America/Anchorage | airport | OurAirports |
각 공항에 편성되어 있는 경로수를 groupby함수를 통해 집계를 하고, airports의 DataFrame에서 AirportID와 City열을 추출하여 holoview의 Dataset 객체로 nodes개체를 생성합니다.
루트 정보로 만든 route_counts 데이터셋은 edge(link)로, 공항 정보로 만든 nodes 데이터셋은 node로 hv.Chord 객체의 인풋으로 넣어주게 됩니다. 2번째 argument로는 source와 target이 edge 데이터셋에서 각각 어떤 열을 참조해야 하는지를 명시하고 edge의 수는 Stops열을 참조하도록 3번째 argument에 명시해줍니다. 이때 source와 target은 nodes 데이터셋과 매칭되는 ID이어야 한다는 점을 주의해야 합니다.
모든 공항을 시각화하려면 앞서 airports데이터 프레임 정보에서 나와있는 1435개의 공항 정보들을 시각화하게 되는데 이는 시각화해도 의미있는 인사이트를 얻기 힘들기 때문에 가장 편성된 루트가 많은 20개의 busiest airport를 선정하여 나타내도록 하겠습니다.
chord 그래프의 옵션을 추가하여 색깔맵, 공항 이름 등을 표시하고 각 노드와 엣지의 색도 해당하는 공항을 잘 보여줄 수 있도록 색을 선정하여 시각화하면 아래와 같이 그려집니다.
지금까지 Holoviews를 이용하여 Chord diagram을 그려보는 것을 예제를 통해 파악할 수 있었습니다. 지금부터는 연구실에서 사용하고 있는 AiDIN-VIII이라는 사족보행로봇 플랫폼을 가지고 논문에서 나와있었던 Accessibility를 계산하고 centroid poses들에 대해서 chord diagram을 그려보는 과정을 따라가보겠습니다.
샘플링한 Static poses들을 2000개를 poses.pickle 데이터로 저장해놨습니다. 각 pose-to-pose를 PD tracking을 하며 걸리는 시간을 측정하게 되는데 pose-to-pose로 transition되는 시간은 1초가될 수 있도록 joint trajectory를 만들어주고 PD제어를 하면서 0.0025초 마다 destination pose로 도달했는지(시뮬레이터의 dt)를 체크합니다. 이때 무한정 시간을 잴 수는 없기 때문에 10초로 시간을 제한하여 최대 10초까지만 걸리는 시간을 기록하게 됩니다.

이 정보가 총 2000개 샘플 포즈에 대해서 1:1로 모두 구해야 하기때문에 병렬계산을 해서 저장하여 총 75개의 npy데이터로 나누어 계산하였고 이를 2000 by 2000 매트릭스로 만들어서 AccessTimeTable을 시각화하면 아래와 같이 그려집니다.
array([[ 0. , 1.245, 10. , ..., 1.145, 10. , 10. ],
[10. , 0. , 1.555, ..., 0.955, 1.31 , 10. ],
[10. , 3.09 , 0. , ..., 10. , 10. , 10. ],
...,
[10. , 0.965, 2.035, ..., 0. , 10. , 10. ],
[ 1.345, 1.015, 10. , ..., 1.145, 0. , 10. ],
[10. , 10. , 1.4 , ..., 10. , 10. , 0. ]])
10초 이하로 측정되었던 time data와 10초 이상으로 측정된 time data의 수를 살펴보면 아래와 같습니다.
이러한 timeMat를 Accessiblity 공식에 맞게 다시 계산하게 됩니다. 이때 10초 이상이 되는 데이터는 1e-8으로 만들어서 가장 낮은 accessiblity 점수를 얻도록 처리합니다.
히스토그램으로 Accessibility를 시각화하면 다음과 같습니다.

무한대 시간이 걸렸던 부분을 제외하고 히스토그램을 그려보면 아래와 같습니다.
계산한 Accessibility 값을 기준으로 K-Acc 알고리즘으로 centroid pose와 적절한 centroid 수를 결정하게 됩니다. 논문에서 소개된 K-Acc 알고리즘은 원저자가 공개한 코드를 그대로 사용하여 AiDIN-VIII 데이터에 적용했습니다.
K_access 클래스를 가지고 최적의 클래스 수를 선정하기 위해 fit을 클래스 수를 늘려가며 수행합니다. 그랬을 때 155개의 centroid cluster를 가졌을 때 가장 index 점수가 높아 최적의 클래스 수를 선정할 수 있었습니다.
scores = []
n_cls = range(1,201) # 클래스의 수 1 ~ 200까지 조사
for num_class in n_cls:
k = K_access(acc_matrix, num_class)
k.fit()
scores.append(k.evaluate())
fig,ax = plt.subplots(figsize=(10, 10*9/16))
max_ind = np.argmax(scores)
print(max_ind+1, scores[max_ind]) # 최적의 클래스 수, 그때의 인데스 점수
plt.plot(n_cls, scores, marker='o', markersize=1)
plt.plot([max_ind+1],[scores[max_ind]],marker='o',c='r',markersize=2)
plt.xlabel('Number of Clusters')
plt.ylabel('Index Value')
plt.xlim([0,170])
plt.show()155 14.17499592680445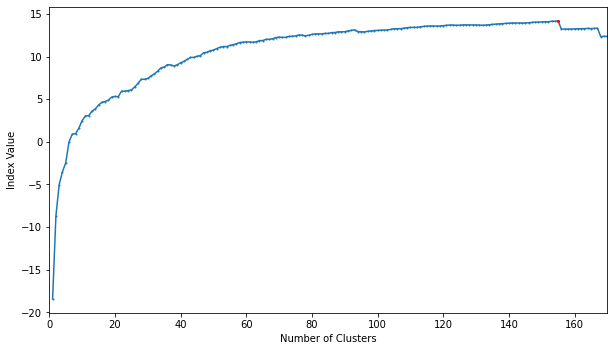
선정된 클래스 수를 가지고 다시한번 클러스터링 작업을 거져 각 centroid pose인 cores에 대한 정보와 inter_access, intra_access 점수를 가져올 수 있습니다.
array([1213, 1043, 1150, 1555, 112, 100, 1032, 121, 140, 1097, 1116,
1554, 1377, 1623, 33, 41, 250, 29, 1272, 1926, 1401, 22,
1888, 809, 1262, 165, 1513, 108, 1248, 333, 1008, 330, 1081,
157, 419, 1227, 1231, 1244, 564, 392, 543, 18, 1785, 227,
1288, 1644, 1715, 398, 1527, 1017, 169, 1056, 139, 323, 1848,
1121, 1067, 225, 476, 450, 898, 8, 1492, 1223, 467, 1844,
1608, 1803, 1839, 1913, 1015, 96, 1020, 627, 1526, 691, 268,
1899, 1521, 1787, 3, 1597, 210, 643, 502, 1358, 209, 798,
1887, 1216, 332, 972, 1122, 404, 343, 1423, 363, 173, 1544,
5, 1817, 960, 72, 1832, 853, 446, 479, 395, 650, 313,
1587, 677, 239, 1089, 464, 891, 1029, 1491, 1477, 761, 860,
1352, 1564, 938, 645, 1254, 50, 1149, 453, 1791, 777, 1990,
1737, 47, 1220, 1537, 315, 1180, 162, 1277, 1568, 910, 528,
523, 1361, 709, 1718, 1045, 618, 86, 1889, 1250, 455, 814,
172])각 클러스터마다 포함하고 있는 샘플들의 수는 어떻게 분포하고 있을까요? 히스토그램으로 시각화를 해보았습니다. 각 샘플들의 수는 이후에 chord diagram의 노드가 될 것 입니다.
# figure 설정
plt.rcParams['lines.linewidth']=0.7
plt.rcParams['xtick.direction']='in'
plt.rcParams['ytick.direction']='in'
plt.rcParams['xtick.major.width']=0.4
plt.rcParams['ytick.major.width']=0.4
plt.rcParams['xtick.major.size']=2
plt.rcParams['ytick.major.size']=2
fig,ax = plt.subplots(figsize=(20, 5))
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax_ = plt.hist(np.array(clusters)-0.5,
range = [0.5, np.max(clusters)+0.5],
bins = np.max(clusters),
edgecolor='dimgray',
color='deepskyblue',
rwidth=1,
alpha=0.5)
ax = plt.xticks(range(1,1+np.max(clusters),5))
plt.xlabel('Cluster ID',fontsize=15)
plt.ylabel('Number of Samples',fontsize=15)
plt.show()
알고리즘을 통해 선정된 centroid pose들에 대한 정보를 한번 확인해보겠습니다. 각 pose에 대한 정보는 아래와 같은 형식으로 정리해서 가장 많은 샘플 수를 포함하고 있는 top-3 centroid pose를 확인해보겠습니다.
[
([0,0,height], [ 12 joints], [roll, pitch, 0] ),
]
이제 본격적으로 pose 데이터를 가지고 chord graph를 그려보겠습니다. pickle 데이터로 저장되어 있는 pose 데이터들 중 2000개의 데이터를 가지고 dataframe 객체로 만들어줍니다. 마지막으로 clustering 과정에서 구한 각 포즈 데이터가 속해있는 cluster의 ID를 데이터프레임의 열을 추가하여 정보를 추가해줍니다.
| store_height | store_roll_pitch | store_joints | store_links | cluster | |
|---|---|---|---|---|---|
| 0 | 0.300289 | (2.150537560664197, -0.004430010187345012) | [-0.5810368941034365, -1.206576076316329, -0.0... | [(-0.17671623826026917, -0.23643925786018372, ... | 22 |
| 1 | 0.067273 | (-0.00028379763432160346, 2.8617441250464685e-05) | [0.15361879275773346, -2.083050326944349, -1.1... | [(0.14308467507362366, -0.12229745090007782, 0... | 77 |
| 2 | 0.091594 | (-0.21762631665841028, -1.16469456094937e-05) | [0.1518267329947646, -1.165616939584498, -0.07... | [(-0.08804446458816528, -0.04484516754746437, ... | 129 |
항공편 예제에서도 살펴보았듯이 모든 cluster를 시각화하는 것은 의미가 없기 때문에 Top20 cluster에 속해있는 데이터들만 처리하기 위해서 데이터를 전처리하는 과정이 필요합니다. 우선 각 pose 데이터가 source(출발노드) 가 될수도 있고 target(도착노드) 이 될 수도 있기 때문에 data_id라는 변수를 통해 기준 데이터(pose A) 와 페어 데이터(pose B) 를 튜플로 묶어준 리스트를 생성합니다.
각 기준 데이터와 페어 데이터에 대해서 각 데이터가 속해있는 클러스터 아이디를 확장해서 저장해줍니다. 데이터들을 확인하기 위해 index 998:1004범위에 있는 값들을 확인합니다.
# 기준 데이터(pose A)
id_list = [x[0] for x in data_id]
print(id_list[998:1004])
# 페어 데이터(pose B)
pairs = [x[1] for x in data_id]
print(pairs[998:1004])
# 기준 데이터의 클러스터 아이디를 확장
clusters_expand = [clusters[x//2000] for x in range(2000*2000)]
print(clusters_expand[998:1004])
# 페어 데이터의 클러스터 아이디를 확장
pair_cluster = clusters * 2000
print(pair_cluster[998:1004])
assert len(id_list)==len(clusters_expand) == len(pairs) == len(values) == len(pair_cluster) # values는 acc 값[1, 1, 1, 1, 1, 1]
[999, 1000, 1001, 1002, 1003, 1004]
[22, 22, 22, 22, 22, 22]
[1, 103, 21, 40, 59, 61]다음으로 chord 그래프를 위한 데이터 프레임 객체 df_chord를 만들고 칼럼을 재정렬해줍니다.
| id | cluster | pair | pair_cluster | acc | |
|---|---|---|---|---|---|
| 998 | 1 | 22 | 999 | 1 | 1.000000e-08 |
| 999 | 1 | 22 | 1000 | 103 | 1.000000e-08 |
| 1000 | 1 | 22 | 1001 | 21 | 1.000000e-08 |
| 1001 | 1 | 22 | 1002 | 40 | 1.000000e-08 |
| 1002 | 1 | 22 | 1003 | 59 | 1.000000e-08 |
| 1003 | 1 | 22 | 1004 | 61 | 8.589883e-01 |
기준 데이터의 클러스터 기준으로 상위 20개의 클러스터에 속해 있는 데이터들만 남기기는 과정을 진행합니다. 클러스터의 아이디는 크기순 정렬이기 때문에 1~20까지의 클러스터 아이디만 남기면 상위 20개의 클러스터에 속한 포즈 데이터들만 남게 됩니다.
페어 데이터의 클러스터 기준으로도 상위 20개의 클러스터에 속해 있는 데이터들만 남기는 과정을 똑같이 진행합니다.
| id | cluster | pair | pair_cluster | acc | |
|---|---|---|---|---|---|
| 8004 | 5 | 12 | 5 | 12 | 1.000000e+00 |
| 8006 | 5 | 12 | 7 | 18 | 1.000000e-08 |
| 8007 | 5 | 12 | 8 | 8 | 1.000000e-08 |
| 8011 | 5 | 12 | 12 | 13 | 1.000000e-08 |
| 8025 | 5 | 12 | 26 | 12 | 9.080099e-01 |
holoviews 패키지를 불러와서 chord graph를 그리기 위한 준비를 합니다. holoviews는 시각화 라이브러리 백엔드를 선택할 수 있는데 interaction이 가능한 bokeh 백엔드를 선택했습니다.
항공편 예제에서도 groupby를 이용해서 edge 수를 집계했듯이 pose 데이터셋에 대해서도 acc수를 cluster와 pair_cluster를 기준으로 집계해서 edge 정보를 정리해줍니다.
| cluster | pair_cluster | acc | |
|---|---|---|---|
| 0 | 1 | 1 | 1764 |
| 1 | 1 | 2 | 1764 |
| 2 | 1 | 3 | 1596 |
| 3 | 1 | 4 | 1302 |
| 4 | 1 | 5 | 1218 |
| ... | ... | ... | ... |
| 395 | 20 | 16 | 675 |
| 396 | 20 | 17 | 650 |
| 397 | 20 | 18 | 650 |
| 398 | 20 | 19 | 650 |
| 399 | 20 | 20 | 625 |
400 rows × 3 columns
다음으로 공항정보를 저장했듯이 pose데이터가 속해있는 cluster의 아이디를 각 centroid pose(cp_N) 이름으로 매칭해서 저장해줍니다. 각 노드(pose 데이터)가 속해있는 cluster_id를 기준으로 edge 데이터셋에서 cluster와 매칭되는 것을 알 수 있습니다.
마찬가지로 옵션을 추가하여 chord diagram을 좀 더 보기 좋게 만들어서 export 해보겠습니다.
이렇게 해서 완성한 K-Acc Chord Diagram을 각 centroid pose와 함께 시각화를 하면 아래 그림과 같이 됩니다!
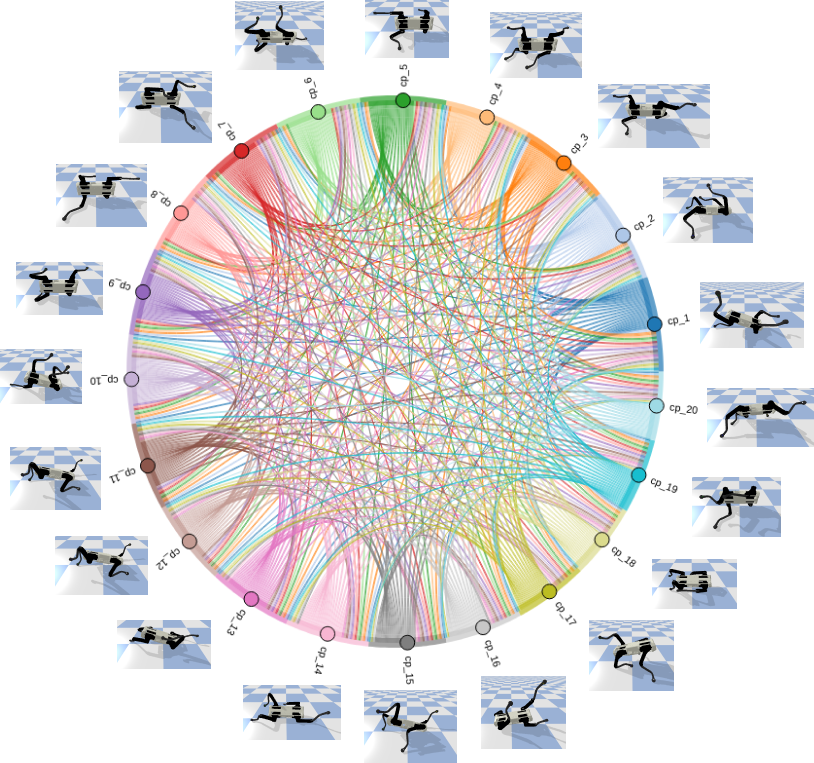
Conclusion
그동안 데이터 시각화를 위한 코딩작업을 자주하지 않아서 논문에 있는 그림을 하나 따라하기까지 정말 오랜시간이 걸렸던 것 같습니다. 적절한 패키지를 서칭하는 것부터 시작해서 해당 패키지를 어떻게 사용해야 원하는 그림을 뽑을 수 있는지까지 한 과정마다 많은 고민과 연습이 필요했지만 마지막에 원하는 시각화 자료를 뽑을 수 있어서 뿌듯했던 것 같습니다. 데이터 시각화 과정이 연구를 하는 입장에서는 가장 마지막에 설득과 확인의 과정에 필요한 자료라서 소홀히 하기 쉬운데 논문의 결과를 더 빛낼 수 있는 중요한 과정이라는 것을 이번 기회에 또 한번 느낄 수 있었던 것 같습니다. 생소한 그래프 형식과 적용이 만만치는 않았지만 정말 의미있던 과정이었고 Chord diagram이 필요한 그 누군가에게 도움이 되었기를 바라며 이번 포스팅을 마치겠습니다.
Reference



