📃NerveNet 리뷰
Abstract
We address the problem of learning
structured policiesforcontinuouscontrol. In traditional reinforcement learning, policies of agents are learned by multi-layer perceptrons (MLPs) which take the concatenation of all observations from the environment as input for predicting actions. In this work, we proposeNerveNettoexplicitly model the structure of an agent, which naturally takes the form ofa graph. Specifically, serving as the agent’spolicy network, NerveNetfirst propagates information over the structure of the agentand thenpredict actions for different parts of the agent. In the experiments, we first show that our NerveNet is comparable to state-of-the-art methods on standard MuJoCo environments. We further propose our customized reinforcement learning environments for benchmarking two types of structuretransfer learning tasks, i.e., size and disability transfer, as well asmulti-task learning. We demonstrate that policies learned by NerveNet are significantly more transferable and generalizable than policies learned by other models and are able to transfer even in azero-shot setting.
보통 강화학습에서 agent들의 policy는 multi-layer perceptrons (MLPs)으로 네트워크를 만들기 때문에 agent가 environment에서 받은 observation들을 단순히 쌓아서(concatenation) policy network에 입력으로 들어가게 된다. 하지만 손의 속도 정보와 발의 속도 정보가 같은 속도 범주이지만 위치가 다르기 때문에 구분이 있을 수 있듯이 agent의 이런 구조적인 특성을 반영해서 policy를 만든다면 observation 정보들간의 구분을 할 수 있을 것이다. 이런 agent의 구조적 관계성을 나타내기 위해서 MLP대신 그래프를 활용하게 되었고 NerveNet을 고안하게 되었다. NerveNet은 그래프 구조로 되어 있는 policy network에서 각 노드들의 정보들이 전파(propagation)되며 agent의 부분들을 나타내는 노드마다 action을 prediction 하게 된다. MuJoCo 환경에서 MLP 기반의 벤치마크들과 비등한 학습결과를 보여주었으며, transfer learning task로 agent의 크기(size)와 agent의 일부 파트가 작동하지 않는(disability) variation을 주었을 때도 잘 학습되었으며 multi-task learning으로 walker 그룹의 다양한 환경에서의 학습 결과들도 좋았다. 이런 결과들을 통해 NerveNet이 transferable할 뿐만 아니라 zero-shot setting도 가능함을 보여주었다.
transferable- A task를 학습한 네트워크(weights)를 활용하여 B task 학습에도 적용하여 scratch에서 B task를 학습하는 것보다 더 빠르고 효율적인 학습을 가능하게 할 수 있다는 의미. A task 학습에서 습득한 논리체계를 B task에도 적용할 수 있음으로 볼 수 있다.zero-shot- Meta learning에서 사용되는 용어로 A task에 대해서 학습된 네트워크가 fine tuning이 없이 바로 unseen new task B에 대해서 좋은 성능을 내는 것을 의미.
Introduction
많은 강화학습 문제들에서 agent들은 여러개의 독립적인 controller들로 구성되어 있다. 예를들어 로봇의 제어에서 강화학습이 많이 적용되고 있는데, 로봇은 여러개의 링크(link)들과 조인트(joint)들로 이루어져 있고 움직임이 일어나는 joint들을 각 개별적인 controller로 볼 수 있다. 이때 link는 로봇의 물리적인 형태를 구성하는 뼈대처럼 생각하면 되고 joint는 로봇의 모션을 결정하는 관절로 생각할 수 있다.(보통 회전이 가능한 revolute joint를 사용한다.) 로봇은 link-joint-link- ... -joint-link와 같이 link와 joint가 체인처럼 연결되어서 구성되는데, 각 link와 joint의 움직임은 자신의 상태에만 의존하는 것이 아니라 연결된 주변 link와 joint들에게서도 영향을 받을 수 밖에 없다. 로봇을 움직이도록 제어를 한다는 것은 바로 모션을 만드는 joint의 움직임을 결정하는 것이다. 따라서 robot agent는 강화학습에서의 action을 joint을 제어하는 것으로 생각할 수 있고 action으로 로봇의 joint의 각도를 바꿔가며 로봇을 움직이게 된다.
보통 강화학습에서 agent의 policy는 MLP로 구성한다. MLP기반의 policy는 가장 단순한 네트워크 구조로 input으로 agent가 얻는 observation 정보를 concatenation해서 넣어주게 된다. 다시 로봇 agent의 예시로 돌아가서 생각해보면, agent가 observation으로 사용하는 정보로는 각 joint의 회전각도, 회전 각속도, 위치 정보등 다양한 종류의 정보들이 있고 이 다양한 정보들은 각 joint로부터 얻게 되므로 각 joint에서 얻을 수 있는 정보 x joint의 수 가 보통 observation의 차원 수가 된다. 로봇의 joint가 많아질 수록 차원이 배로 커지게 되고 이런 여러 정보들을 단순히 concatenate해서 policy 네트워크에 넣어주는 것은 더 많은 training time을 요구하게 되고 더 많은 환경과 agent 간의 interaction 과정이 필요하게 된다. 따라서 본 논문에서는 agent가 가지고 있는 (link와 joint로 이루어진) 구조적인 특성을 이용해서 policy를 그래프로 만들어 observation을 넣어주고 학습을 하는 것을 제안하게 된다.
로봇이나 동물들의 신체적인 구조를 보면 그래프 구조와 유사하다. 위에서 설명한 link와 joint의 체인과 같은 연결성은 Graph Neural Network를 적용하기에 좋다. 그래서 NerveNet에서 정보들의 propagation은 이런 그래프 구조를 기반으로 일어나게 되고 agent의 body정보를 여러 다른 파트들을 그래프의 node와 edge로 정의하면서 움직임이 일어나는 body node들의 action을 결정하게 된다.
NerveNet
우선 강화학습의 Notation을 정리해보면, 본 논문에서는 locomotion control problem들을 목표로 잡았기 때문에 infinite-horizon discounted Markov decision process (MDP) 로 설정했다. 보통 continuous한 제어 문제에서는 시간 할인율을 고려한 무한 시간 스텝을 가지고 MDP를 구성하게 된다(실제로는 max step을 설정하긴하나 매우 큰 수로 잡는다).
state 혹은 observation space로 S , action space로 A, stochastic policy \pi_{\theta}\left(a^{\tau} \mid s^{\tau}\right) 는 파라미터 \theta를 가지고 현재 상태 s를 기반으로 a를 만들게 된다. 이렇게 나온 agent의 a와 s를 가지고 환경에서는 reward r\left(s^{\tau}, a^{\tau}\right) 를 주게 되고 agent는 이렇게 받는 reward를 최대화하는 방법을 학습하게 된다.
이러한 MDP 구성은 기본적인 강화학습의 Notation에서 크게 벗어나지 않는다.
Graph Construction
본 논문에서는 사용한 MuJoCo의 agent들은 이미 구조적으로 tree 구조를 가지고 있다. NerveNet의 핵심 아이디어인 그래프를 구성하기 위해 body와 joint, root라는 3가지 종류의 노드를 설정했다. body 노드는 로봇공학에서 말하는 link 기준의 좌표시스템을 나타내는 노드이고, joint 노드는 모션의 자유도(freedom of motion)을 나타내며 2개의 body 노드들을 연결해주는 노드이다.
아래는 Ant 환경의 예시인데, 한 가지 그림에서 헷갈리지 말아야 할 점은 그림에서는 마치 body와 root 노드만 노드로 만든것 처럼 보이지만 root와 body, body와 body를 연결하는 엣지들도 실제로는 joint 노드들이다.(we omit the joint nodes and use edges to represent the physical connections of joint nodes.)root라는 노드는 agent의 추가적인 정보들을 담을 부분으로 사용하기 위해 추가한 노드 종류로, 예를 들어 agent가 도달해야 하는 target position에 대한 정보 등이 담겨있다.

NerveNet as Policy
크게 3가지 파트로 NerveNet을 살펴볼 것인데 우선 (0) Notation을 보고 난뒤, (1) Input model (2) Propagation model (3) Output model 순으로 살펴볼 예정이다.
0. Notation
그래프에서의 노테이션은 다음과 같이 G 라는 그래프는 노드 집합 V와 엣지 집합 E로 구성된다.
G=(V, E)
Nervenet policy를 구성하는 그래프는 Directed graph(유향 그래프)이기 때문에 각 노드에서의 in과 out이 따로 명시되게 된다.
- 노드 u를 중심으로 노드 u로 들어오는 이웃 노드이면 \mathcal{N}_{in}(u)
- 노드 u를 중심으로 노드 u에서 나가는 이웃 노드이면 \mathcal{N}_{out}(u)
그래프의 모든 노드 u는 타입을 가지게 되고 이를 p_{u} \in\{1,2, \ldots, P\} (associated note type)로 나타내며 여기에서는 위에 설명한 것과 같이 body, joint, root 3가지 타입이 있다.
노드들 뿐만 아니라 엣지들도 타입을 정할 수 있는데 c_{(u, v)} \in\{1,2, \ldots, C\} (associate each edge)로 표기하여 노드쌍 (u, v) 사이의 엣지 타입을 정의할 수 있다.(하나의 엣지에 대해서 여러 엣지 타입을 정의할 수 있지만 여기에서는 심플 이즈 더 베스트 철학으로 하나의 엣지는 하나의 타입만 가지도록 했다)
이렇게 노드별, 엣지별 타입을 나눔으로써,
노드 타입은 노드들간의 다른 중요도를 파악하는데 도움이 되고엣지 타입은 노드들간의 서로다른 관계들을 나타내고 이 관계의 종류에 따라 정보를 다르게 propagation 하게 된다.
이제 시간 노테이션에 대한 부분을 살펴보자. NerveNet에는 시간(time step)의 개념이 2가지 존재한다.
- 기존 강화학습에서 환경과 agent 사이의 interaction time step을 나타내는 \tau
- NerveNet의 내부 graph policy에서의 propagation step을 나타내는 t
다시 풀어서 생각해보면, 강화학습의 시간 개념 \tau 스텝에서 환경으로부터 observation을 받고, 받은 observation을 기반으로 t 스텝동안 NerveNet의 내부의 그래프의 propagation이 일어난다.
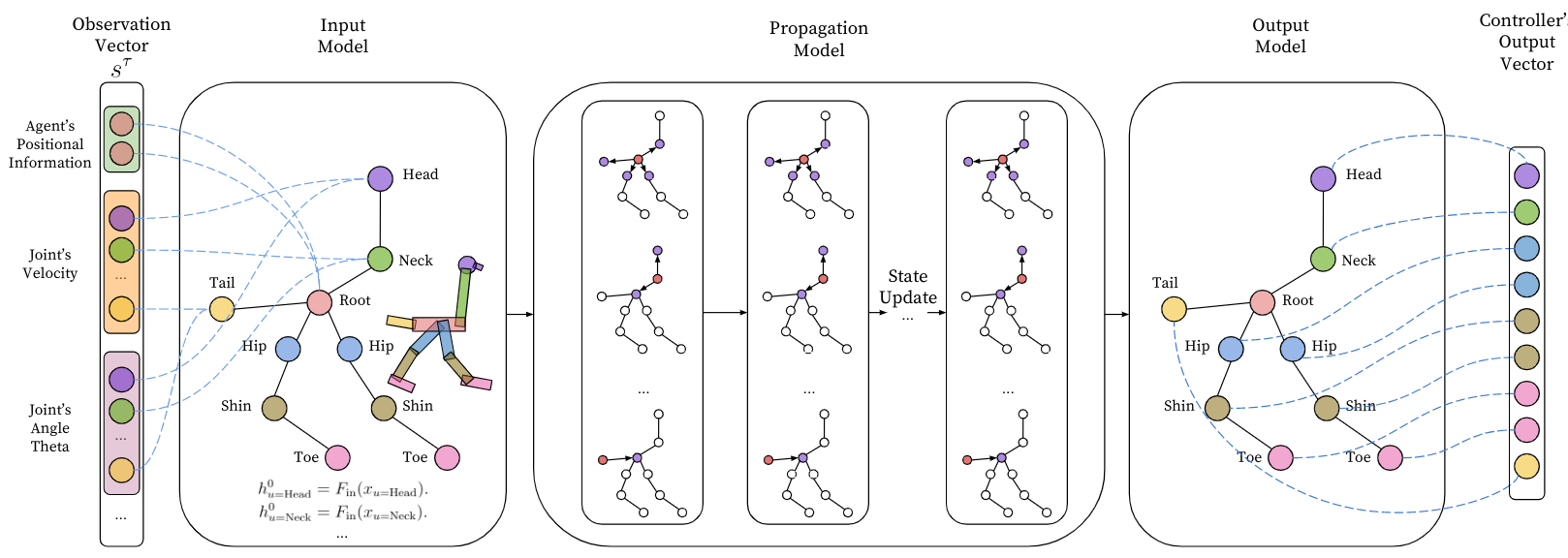
1. Input model
위에서 말했듯이 환경과 상호작용으로 observation s^{\tau} \in \mathcal{S}을 받게 된다(time step \tau). 이 s^{\tau}는 concatenation된 각 노드의 observation이라고 볼 수 있다. 이제 강화학습 interaction 수준의 \tau 스텝은 잠시 멈춰두고 그래프 내부의 타임 스텝인 t 수준에서 생각해보자. observation은 node u에 해당하는 x_{u}로 표현할 수 있고 x_{u}는 input network F_{\mathrm{in}}(MLP)를 거쳐서 고정된 크기의 state vector인 h_{u}^{0}가 된다. h_{u}^{0}의 노테이션을 풀어서 해석하면 노드 u의 propagation step 0 에서의 state vector인 것이다. 이때 observation vector x_{u}가 노드마다 크기가 다를 경우 zero padding으로 맞춰서 input network에 넣어주게 된다.
h_{u}^{0}=F_{\text {in }}\left(x_{u}\right)
2. Propagation model
NerveNet의 propagation 과정 노드들 간에 주고 받는 정보를 message라고 하게 되고 이는 노드들 간에 주고 받는 상호작용이라고 생각할 수 있다. Propagation model은 3가지 단계로 나누어서 볼 수 있다.
- Message Computation
전달할 메세지를 계산한다.
propagation step인 t에, 모든 노드들 u에서 state vector h_{u}^{t}를 정의할 수 있다.
노드 u로 모아지는(in-coming) 모든 엣지들을 가지고 메시지를 구하게 되는데, 이때 M은 MLP이고 M의 아래첨자 c_{(u, v)} 노테이션에서 알 수 있듯이 같은 종류의 엣지에 대해서는 같은 message function M을 쓴다.
m_{(u, v)}^{t}=M_{c_{(u, v)}}\left(h_{u}^{t}\right)
예를 들어 아래 그림은
CentipedeEight의 모습인데, 왼쪽은 실제 agent의 모습을 나타내고 있으며 오른쪽은 agent를 그래프로 나타냈을 때의 모습이다. 여기에서 2번째 torso에서 첫번째 세번째 torso에서 보낼 때 같은 메세지 펑션 M_{1} 을 사용하고, LeftHip과 RightHip으로 보내는 메세지 펑션 M_{2}를 사용하게 되는 것이다.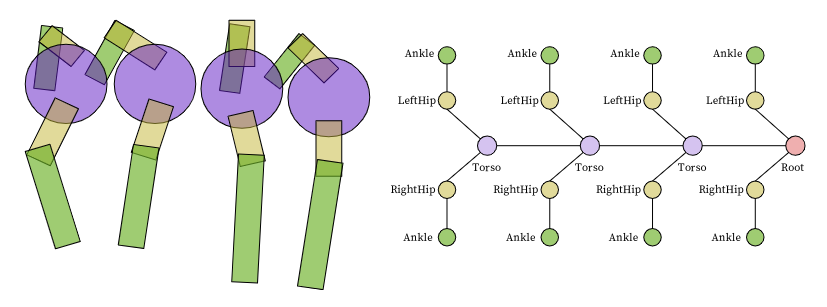
- Message Aggregation
앞 단계에서 모든 노드들에 대해서 메세지 계산이 끝난 후에 in-coming 이웃 노드들로부터 온(계산된) 메세지를 모으게 된다. 이때 summation, average, max-pooling 등 다양한 aggregation 함수를 사용할 수 있다.
\bar{m}_{u}^{t}=A\left(\left\{h_{v}^{t} \mid v \in \mathcal{N}_{i n}(u)\right\}\right)
- States Update
이제 모은 메세지를 기반으로 state vector를 업데이트 하면 된다!
h_{u}^{t+1}=U_{p_{u}}\left(h_{u}^{t}, \bar{m}_{u}^{t}\right)
여기서 업데이트 함수 U 는 a gated recurrent unit (GRU), a long short term memory (LSTM) unit 또는 MLP가 될 수 있다.
Update function의 아래첨자 p_{u}에서 볼 수 있다시피 같은 노드 타입이면 같은 update function U를 쓰게 된다. 이렇게 업데이트된 state vector는 타임 스텝 t가 하나 올라간 t+1 이 된 h_{u}^{t+1}가 된다.
이렇게 내부 propagation 과정 3단계(Message Computation, Message Aggregation, States Update)가 T 스텝동안 일어나게 되고 각 노드의 최종 state vector는 h_{u}^{T} 가 된다.
3. Output model
전형적인 RL의 MLP 폴리시에서는 네트워크에서 각 action의 gaussian distribution의 mean을 뽑아내게 된다. std는 trainable한 벡터이다. NerveNet에서도 std는 비슷하게 다루지만 각 노드에 마다 action prediction을 만들게 된다.
actuator와 연결되어 있는 노드들의 집합을 O라고 하자. 이 집합에 있는 노드들의 최종 state vector h_{u \in \mathcal{O}}^{T}는 MLP인 Ouput model O_{q_{u}}에 인풋으로 들어가게 되고 아웃풋으로 각 actuator의 action distribution인 gaussian distribution의 mean \mu을 출력하게 된다. 여기에서 새로운 노테이션 q_{u}를 볼 수 있는데 q_{u}는 아웃풋 타입, 즉 아웃풋을 내놓는 노드 u의 타입으로 아웃풋 펑션의 아래첨자에 q_{u}에 따라 아웃풋 노드의 타입이 같으면 Output function을 공유할 수 있다. 다시말해 아웃풋 노드 타입에 따라 컨트롤러를 공유할 수도 있는 것이다. 위의 Centipedes의 예시로 보면, 같은 LeftHip 끼리는 컨트롤러를 공유할 수 있다는 것이다.
\mu_{u \in \mathcal{O}}=O_{q_{u}}\left(h_{u}^{T}\right)
논문에서 실제로 실험을 해봤을 때 다른 타입의 컨트롤러들을 하나로 통합했더라도(O function을 다 같은 MLP로 사용) 퍼포먼스가 그렇게 해쳐지지 않음을 확인할 수 있었다고 한다.
여기까지해서 그래프 노테이션을 빌려 그래프 기반 가우시안 stochastic policy를 나타내면 아래의 수식과 같다.
\pi_{\theta}\left(a^{\tau} \mid s^{\tau}\right)=\prod_{u \in \mathcal{O}} \pi_{\theta, u}\left(a_{u}^{\tau} \mid s^{\tau}\right)=\prod_{u \in \mathcal{O}} \frac{1}{\sqrt{2 \pi \sigma_{u}^{2}}} e^{\left(a_{u}^{\tau}-\mu_{u}\right)^{2} /\left(2 \sigma_{u}^{2}\right)}
여기까지 NerveNet의 각 단계를 Walker-Ostrich 환경에서 예시로 한눈에 보기 쉽게 정리한 그림은 아래와 같다.
Learning Algorithm
이전 파트에서 NerveNet의 내부에서 propagation 스텝 t 단위에서 각 단계들을 자세히 살펴보았다면 이제 강화학습 타임 스텝 \tau 단위에서 학습의 목적함수와 알고리즘을 살펴보자. 목적함수는 전형적인 RL과 다른 점이 없이 policy의 파라미터 \theta를 가지고 Return 값을 maximization하는 것으로 한다.
J(\theta)=\mathbb{E}{\pi}\left[\sum{\tau=0}^{\infty} \gamma^{\tau} r\left(s^{\tau}, a^{\tau}\right)\right]
강화학습 알고리즘으로는 PPO과 GAE를 사용했으며 해당 알고리즘들의 내용은 각각 알고리즘들의 원래 수식과 내용들과 상이한 점이 없으므로 각 논문으 참고하면 되기 때문에 이번 논문 리뷰에서는 생략한다.
PPO와 GAE 알고리즘을 참고하여 위의 목적함수 J를 정리하면 NerveNet의 목적함수는 다음과 같다.
\begin{aligned} \tilde{J}(\theta)=& J(\theta)-\beta L_{K L}(\theta)-\alpha L_{V}(\theta) \\ =& \mathbb{E}_{\pi_{\theta}}\left[\sum_{\tau=0}^{\infty} \min \left(\hat{A}^{\tau} r^{\tau}(\theta), \hat{A}^{\tau} \operatorname{clip}\left(r^{\tau}(\theta), 1-\epsilon, 1+\epsilon\right)\right)\right] \\ &-\beta \mathbb{E}_{\pi_{\theta}}\left[\sum_{\tau=0}^{\infty} \operatorname{KL}\left[\pi_{\theta}\left(: \mid s^{\tau}\right) \mid \pi_{\theta_{o l d}}\left(: \mid s^{\tau}\right)\right]\right]-\alpha \mathbb{E}_{\pi_{\theta}}\left[\sum_{\tau=0}^{\infty}\left(V_{\theta}\left(s^{\tau}\right)-V\left(s^{\tau}\right)^{\operatorname{target}}\right)^{2}\right] \end{aligned}
위의 수식에서 볼 수 있는 value network V를 어떻게 디자인할 것인지가 이번 논문의 다른 포인트로 볼 수 있다. 논문의 기본 아이디어는 policy network를 그래프로 표현하는 것이고, value network는 어떻게 할지 여러 선택지들이 남아있다. 그래서 본 논문에서는 value network의 디자인을 두고 크게 3가지 NerveNet의 변형 알고리즘들을 실험해보았다.
NerveNet-MLP : policy network를 1개의 GNN으로 구성하고
value network는 MLP로구성NerveNet-2 : policy network를 1개의 GNN으로 구성하고
value network는 또 다른 GNN으로구성(총 GNN 2개 - without sharing the parameters of the two GNNs)NerveNet-1 :
policy network와 value network 모두 1개의 GNN으로구성(총 GNN 1개)
Experiments
먼저 MuJoCo 시뮬레이터에서 NerveNet의 효과를 확인하고 일부 커스텀한 환경들에서 NerveNet의 transferable과 multi-task learning 능력을 확인한다.
1. Comparison on standard benchmarks of MuJoCo
- 비교군으로
MLP,TreeNet(모든 노드들이 연결 되어 있는 그래프, depth 1)을 사용 - 총 8개의 환경에서 실험 -
Reacher, InvertedPendulum, InvertedDoublePendulum, Swimmer, HalfCheetah, Hopper, Walker2d, Ant - 충분히 학습하는 스텝을 주기 위해서 1 million을 max로 둠
- 하이퍼 파라미터의 경우 그리드 서치로 찾았으며(Appendix 참고) 각 알고리즘의 퍼포먼스를 측정할 때 3번의 run을 랜덤 시드를 바꿔가며 실행시킨 후 평균을 구해서 기록
- 대부분의 환경에서 MLP가 잘됐고 NerveNet도 이와 비등한 퍼포먼스를 냈다.
(3가지 케이스에 대한 learning curve, 다른 케이스들에서는 대체로 NerveNet과 MLP가 비슷했다.)
HalfCheetah |
InvertedDoublePendulum |
Swimmer |
|---|---|---|
| MLP와 NerveNet이 비슷하고 TreeNet이 많이 안좋았음 | MLP가 좀더 좋은 결과를 냄 | NerveNet이 MLP보다 좋은 성능을 냄 |
- 대부분 환경들에서
TreeNet이NerveNet보다 좋지 않았고 이를 통해서 물리적인 그래프 구조를 가져가는 것이 얼마나 중요한지 알 수 있다.
2. Structure transfer learning
- MuJoCo의 환경 하나를 커스텀해서
size와disability의 변화가 있을 때 transferable 함을 검증size transfer- 작은 사이즈의 그래프를 가진 agent를 학습 시킨 후 더 큰 사이즈의 그래프를 가진 agent로 transferable 한지disability transfer- 모든 파트들이 정상작동하는 agent로 학습한 후 일부 파트들이 작동하지 않는 상황의 agent로 transferable 한지
- 2개 종류의 환경을 커스텀하여 실험 -
centipede와snakecentipede - 지네와 같이 생긴 agent로 torso body들이 여러개 체인처럼 연결 되어 있고 torso를 중심으로 양쪽에 다리가 1쌍으로 붙어 있다. 하나의 다리는 thigh와 shin으로 구성되어 있고 hinge actuator로 구현되어 있다. 커스텀은 다리의 갯수를 다양하게 해서 여러 커스텀 환경들을 만들었는데, 가장 짧은 agent로는
CentipedeFour부터 가장 긴 agent로는CentipedeFourty로 다리가 40개까지(20쌍) 있는 환경을 만들수 있었다. disability로 일부 파트가 작동하지 않는 환경은Cp(Cripple)로 따로 표기했다. 이 환경에서 y-direction으로 빨리 앞으로 가는게 목표다.snake -
swimmer환경을 기반으로 커스텀했으며 가장 빨리 진행방향으로 움직이는 게 목표다.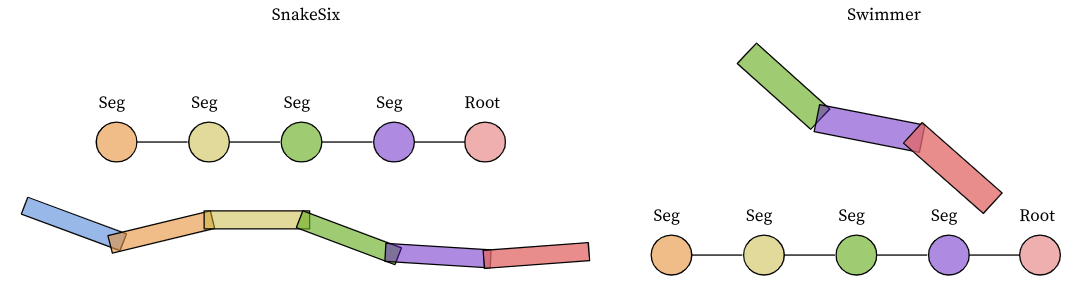
비교군
NerveNet: small agent가 학습한 모델을 바로 large agent에 적용할 수 있었다. agent의 구조가 반복적이기 때문에 반복되는 부분을 더 늘리기만 하면 되기 때문이다.MLP Pre-trained (MLPP): agent의 크기가 커짐에 따라 input size가 달라지므로 가장 straightforward하게 첫번째 hidden layer를 그대로 output layer로 사용하고 input layer의 사이즈만 키워서 추가하고 이 input layer는 랜덤 초기화를 해준다.MLP Activation Assigning (MLPAA): small agent의 weight들을 바로 large agent의 모델에 넣어주고 weight들의 남는 부분들을 0으로 초기화 해준다.TreeNet: MLPAA처럼 스케일을 키워서 0으로 초기화 해준다.Random: action space에서 uniformly하게 샘플링을 하는 policy이다.
Result
Centipede
1-1. Pretraining
- 6-다리 모델과 4-다리 모델로
NerveNet,MLP,TreeNet에서의 퍼포먼스를 비교했다. 여기서 3개의 모델은 앞서 benchmark 비교 실험에서 사용한 비교군들과 동일하다.
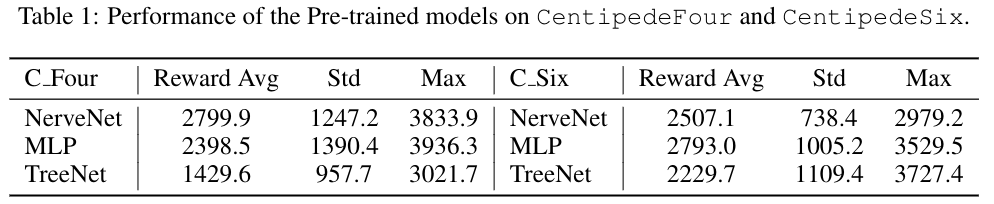
- 4-다리 모델에서는 NerveNet이 가장 Reward가 높고, 6-다리 모델에서는 MLP가 가장 Reward가 높음을 알 수 있다. TreeNet은 두 환경 모두에서 가장 낮다.
- 6-다리 모델과 4-다리 모델로 pretraining을 진행한 후 transferable을 실험했다.
1-2. Zero-shot
- fine tuning 없이 퍼포먼스를 측정했다.
- 퍼포먼스를 쉽게 비교할 수 있도록
average reward와average running-length를 normalization해서 색으로 아래와 같이 표현했다.(green-good, red-bad)
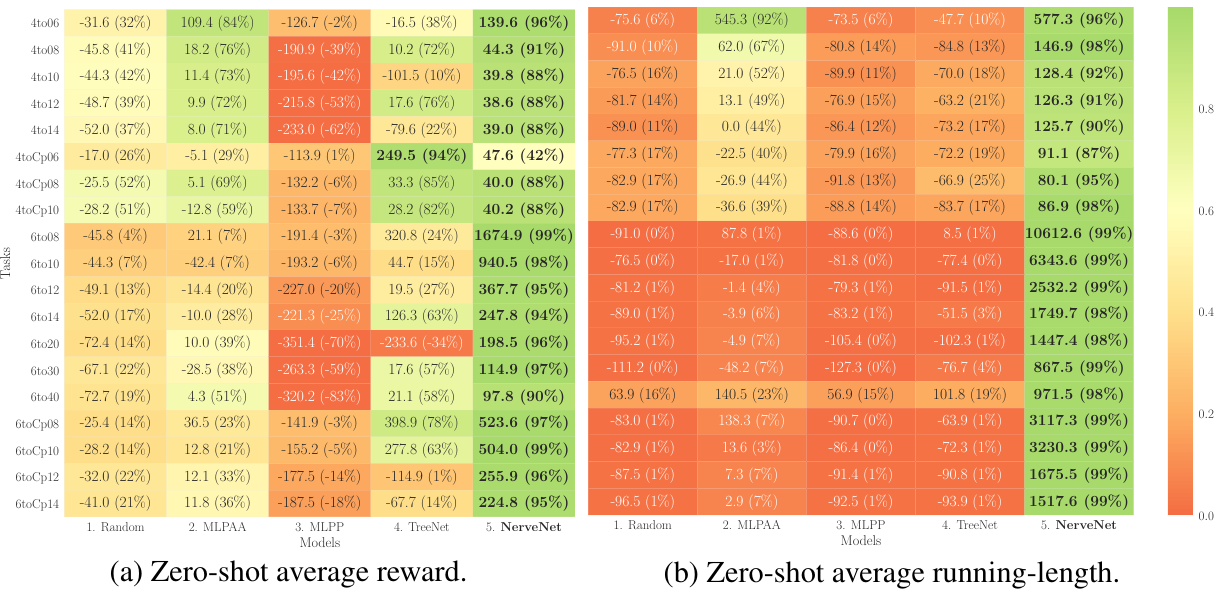
- 눈으로 확실히 확인할 수 있듯이 NerveNet의 퍼포먼스가 다른 비교군에 비해 월등히 transferable함을 알 수 있었다.
- 또한 learning curve에서 볼 수 있듯이 NerveNet+Pretrain 이 다른 Pretrain 비교군들에 비해 훨씬 높은 reward 시작점에서 시작하고 더 적은 timestep으로 solved 점수에 도달하는 것을 보아 그래프의 구조적 이점을 확실히 활용하고 있음을 알 수 있다.

- NerveNet의 agent들은 다른 비교군 agent들에서 보이지 않는
walk-cycle을 가지고 있음을 확인할 수 있었는데, 이는 보행 로봇들은 걸음새에서 반복적인 움직임을 하게 되어 있기 때문에 자연스럽게 cycle을 가지게 되는 것을 agent가 학습했음을 알 수 있다. (반면 MLP는 8-다리 모델에서 모든 다리를 움직이지 않는 모습을 보이기도 했다.)
- 6-다리 모델과 4-다리 모델로
Snake
- snake환경에서도 NerveNet이 다른 비교군들에 비해 뛰어난 reward 점수를 보여주며 transferable 함을 아래의 도표에서처럼 보여주었다.
- 350점 정도가
snakeThree에서 solved된 상태라고 볼 수 있는데 NerveNet의 시작 점수들이 대부분 300점대에서 시작한 것으로 보아 이는 상당한 zero-shot 역량이 있음을 알 수 있다. - 다른 비교군들은 overfitting이 심해서 Random보다 안좋은 결과를 보여주는 점도 흥미롭다.

- zero-shot 뿐만 아니라 fine tuning을 하는 learning curve에서도 NerveNet은 Pretrain의 이점을 다른 비교군들에 비해 잘 활용하고 있음을 볼 수 있었다.
NerveNet+Pretrain의 시작 reward가 높으며, 특정 size transfer 실험에서는 scratch NerveNet이 넘지 못한 MLP 점수를NerveNet+Pretrain이 따라잡았다.

3. Multi-task learning
NerveNet은 네트워크에 structure prior를 포함한 것이기 때문에 multi-task learning에 유리할 수 있다. 따라서 이를 실험하기 위해 Walker multi-task learning을 진행했다.
- 2d-walker 환경들 5개 -
Walker-HalfHumanoid,Walker-Hopper,Walker-Horse,Walker-Ostrich, Walker-Wolf - 1개의 통합된 network로 학습
비교군
NerveNet: agent들의 형태가 달라 weight들이 다를 수 밖에 없기 때문에 propagation과정에서의 weight matrices와 output만 공유했다.MLP Sharing: hidden layer들 간의 weight matrices 를 공유MLP Aggregation: 차원이 다른 observation들을 aggregation과정을 통해 첫번째 hidden layer의 크기로 다 맞춰주어서 input으로 넣어줌TreeNet: TreeNet도 weight를 공유를 할 수 있지만 agent의 구조적인 정보는 알 수 없다. 단순히 root node를 중심으로 모든 노드의 정보다 aggregation 되기 때문이다.MLPs: 각 agent마다 따로 MLP policy를 만들어서 학습(single-task)
Result - multi-task learning 실험이기 때문에 한 두개 러닝 그래프만 볼 수 없고 5개의 러닝 그래프를 같이 봐야 한다. - Single-task policy를 제외하고 모든 환경에서 NerveNet의 퍼포먼스가 좋음을 알 수 있다.
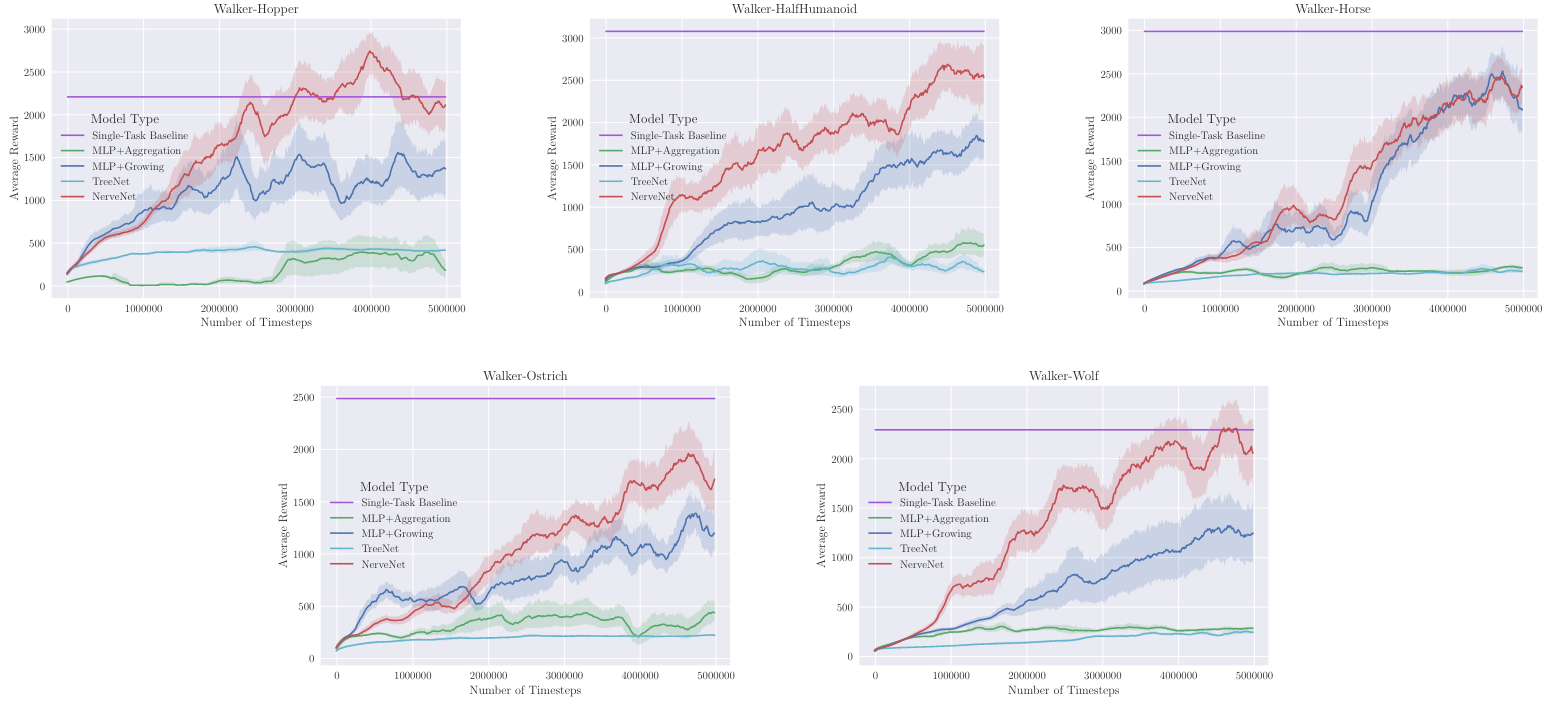
- 테이블에서 Ratio가 single-task policy에 비해 multi-task policy의 성능을 percentage로 나타낸 수치인데, MLP의 퍼포먼스가 single-task에서 multi-task로 넘어갔을 때 42%나 퍼포먼스가 줄어드는 것을 확인할 수 있다. (Average-58.6%) 반면에 NerveNet은 성능이 전혀 떨어지지 않는 결과를 보여주었다.

4. Robustness of learnt policies
강화학습 제어에서 robustness는 중요한 지표인데 질량이나 힘과 같은 물리적인 값들의 오차 범위가 어느정도까지 policy가 허용하고 잘 작동하는지를 확인해야 한다.
- 5개의 Walker 그룹의 환경에서 실험
- pretrained agent를 가지고 agent의 질량과 joint의 strength을 변경한 뒤 퍼포먼스 측정
- 대부분의 환경과 variation에서 NerveNet의 robustness가 MLP보다 좋음을 알 수 있다.

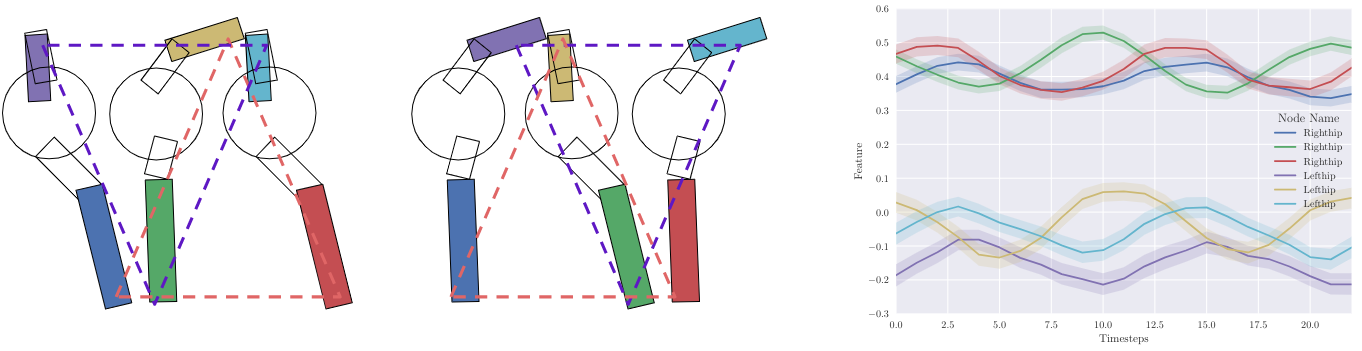
5. Interpreting the learned representations
실제 폴리시들이 어떤 representation들을 학습했는지 알아보기 위해 CentipedeEight 환경에서 학습된 agent의 final state vector를 가지고 2D, 1D PCA를 진행했다.
각 다리쌍들(Left Hip-Right Hip)들은 agent의 전체 몸체에서 각기 다른 위치에 있음에도 불구하고 invariant representation을 배울 수 있었음을 PCA를 통해서 알 수 있었다.

또한 앞서 Centipede transfer learning 실험 결과에서도 잠깐 언급했던 walk-cycle이 주기성이 뚜렷하게 보였다.
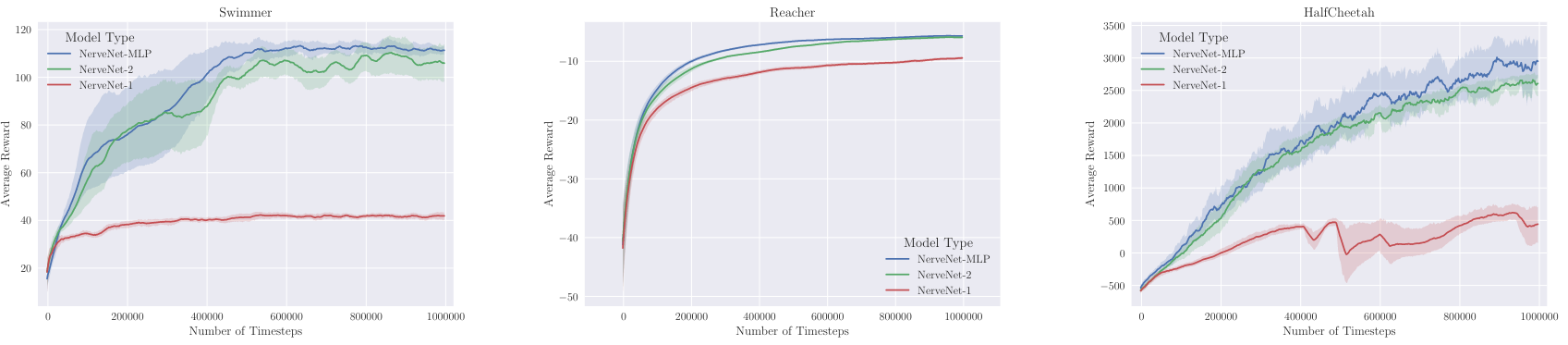
6. Comparison of model variants
Value Network를 어떻게 할 것인지에 따라 NerveNet의 여러 변형이 있을 수 있는데 Swimmer, Reacher, HalfCheetah에서 비교해본 결과, Value Network는 MLP로 한 NerveNet-MLP의 퍼포먼스가 가장 좋았고 NerveNet-1의 퍼포먼스가 2등으로 NerveNet-MLP 와 비슷했다. 이에 대한 잠재적인 이유로 value network와 policy network가 weight를 공유하는 것이 PPO 알고리즘에서의 trust-region based optimitaion에서의 weight \alpha를 더 sensitive하게 만들기 때문이라고 추론할 수 있다.
Conclusion
- NerveNet이라는 그래프 구조를 활용한 policy를 가지고 RL agent의 body structure를 활용할 수 있는 알고리즘을 제안
- 각 body와 joint의 observation을 받아 GNN을 통해 non-linear message들을 계산하고 propagation하는 모델링
- propagation은 엣지로 표현된 joint간의 물리적으로 연결성을 가지고 본래 있는 의존성을 기반으로 이루어짐
- 실험적으로 NerveNet이 MoJoCo 시뮬레이터 기반 여러 환경들에서 MLP 기반 SOTA 알고리즘들과 견줄만한 퍼포먼스를 보여줌o state-of-the-art methods on standard MuJoCo environments.
- 몇가지 환경을 커스텀해서 size와 disability transfer를 검증했으며 zero-shot setting에서도 transferable함을 보임
Review
논문 리뷰후의 주관적인 장단점을 정리하면 다음과 같다.
- Pros 👍
- 로봇의 구조적인 특징을 기반으로 효율적인 feature embedding이었음을 보여줌
- 다양한 robot configuration에서도 잘 작동함
- 모델의 확장성을 설명할 수 있는 Transfer learning과 Multi-task learning이 인상적이었고 큰 장점이라고 생각
- Cons 👎
- 시뮬레이션에서만 실험했다는 점이 아쉬움
- 생각보다 기본적인 gnn모델이라서 edge에 대한 큰 디자인 요소가 들어가지 않은 것 같음
- 다양한 RL 알고리즘들과의 시너지를 보기에는 솔직히 논문의 양이 너무 방대해질 것 같긴하지만 이에 대한 비교가 있었으면 좋았을 것 같음
Reference
- Original Project Homepage: http://www.cs.toronto.edu/~tingwuwang/nervenet.html
- Code
- Official: https://github.com/WilsonWangTHU/NerveNet
- Not official: https://github.com/HannesStark/gnn-reinforcement-learning