📃Robust Recovery Controller 리뷰

이번 포스트는 4족보행 로봇이 전복되었을 때 다시 정상적으로 보행하기 위해 자세를 회복하는 모션 제어(이하 Recovery 혹은 Reset task라고 지칭)을 강화학습 방법으로 해결하고자한 Robust Recovery Controller for a Quadrupedal Robot using Deep Reinforcement Learning라는 논문에 대한 리뷰입니다.

Abstract
The ability to recover from a fall is an essential feature for a legged robot to navigate in challenging environments robustly. Until today, there has been very little progress on this topic. Current solutions mostly build upon (heuristically) predefined trajectories, resulting in unnatural behaviors and requiring considerable effort in engineering system-specific components. In this paper, we present an approach based on
model-freeDeep Reinforcement Learning (RL) to control recovery maneuvers of quadrupedal robots using a hierarchical behavior-based controller. The controller consists offour neural network policiesincludingthree behaviorsandone behavior selectorto coordinate them. Each of them is trained individually in simulation and deployed directly on a real system. We experimentally validate our approach on the quadrupedal robotANYmal, which is a dog-sized quadrupedal system with 12 degrees of freedom. With our method, ANYmal manifests dynamic and reactive recovery behaviors to recover from an arbitrary fall configuration withinless than 5 seconds. We tested the recovery maneuver more than 100 times, and the success rate washigher than 97 %.
요약
- Model-free 강화학습 알고리즘을 이용
- 총 4개의 Neural Network를 활용한 Policy들을 설계함 (실제로 전체 control system에 쓰인 NN은 6개- Height Estimator, Actuator Network 추가)
- ETH에서 개발한 4족보행 로봇인 ANYmal 플랫폼을 사용
- 5초 이내의 전복회복을 약 97 퍼센트의 성공률로 수행
Problem Statement
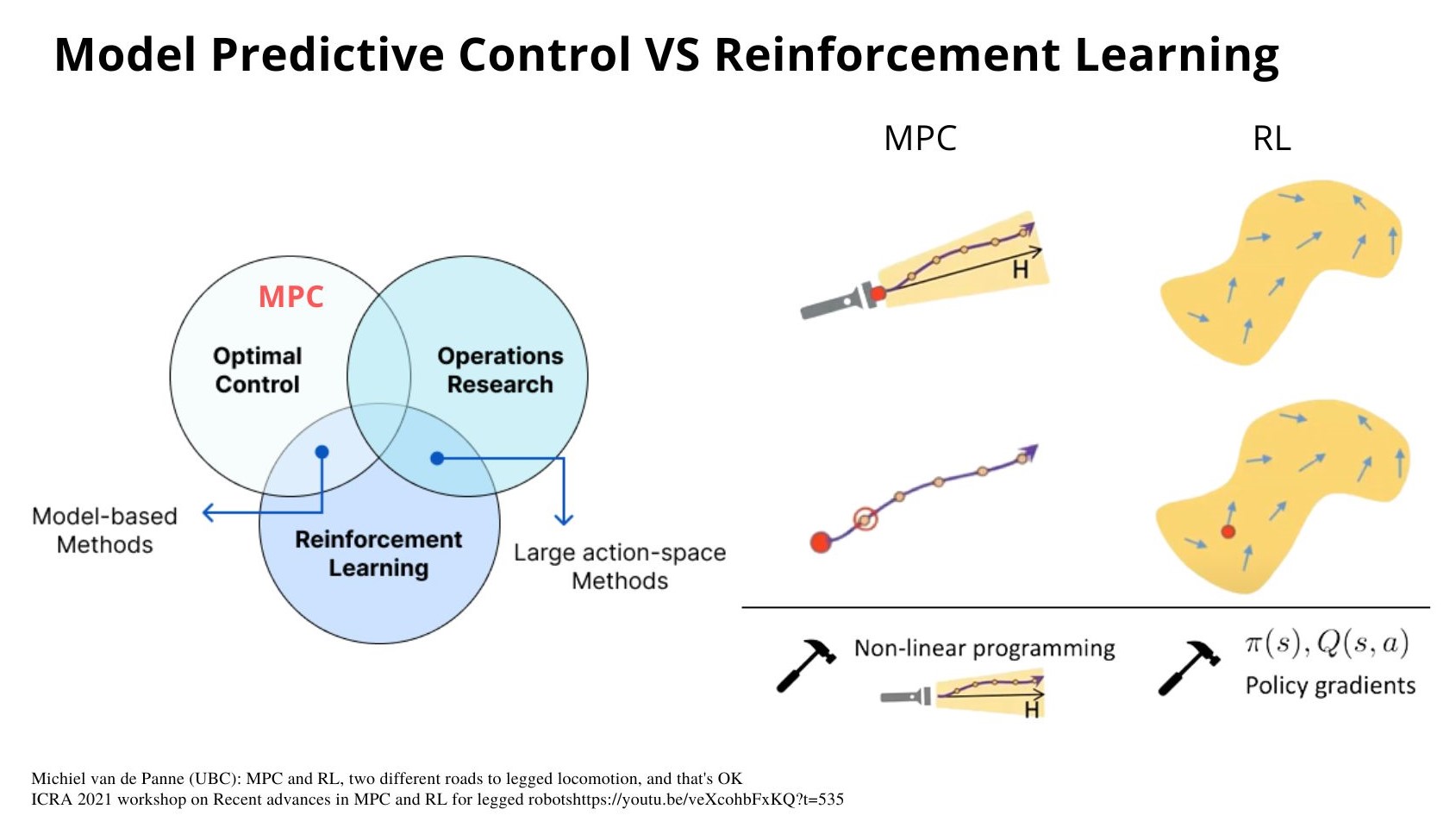
MPC vs RL
제어(Control) 분야에서 현재 크게 양대 방법론으로 MPC(Model Predictive Control)과 RL(Reinforcement Learning) 방법론이 주목을 받고 있습니다. 이분법적으로 두 방법이 확연하게 나누어지거나 우열이 가려지는 것이 아니기 때문에 두 방법론 간의 공통점, 차이점등을 살펴보며 시작해보려고 합니다.
아래 그림의 Optimal Control(최적제어), Operations Research(경영과학), Reinforcement Learning(강화학습)을 각각 하나의 집합으로 표시하고 각 관계를 살펴보면 기존의 제어 방식의 발전 흐름을 이어온 MPC는 Optimal Control에 포함되어 있다고 볼 수 있습니다. Operations Research은 좀 더 넓은 범위의 의사 결정 모델들을 연구하는 분야로 주로 산업공학에서 배우는 부분이며 의사결정에 도움을 받기위해 수학적 모델, 통계학, 알고리즘들을 이용하는 연구분야 입니다. 따라서 Optimal Control, Operations Research와 오늘의 주제 방법론인 Reinforcement Learning과의 관계를 살펴보자면 수학적 모델링을 기반으로 한 Model-based Methods가 Optimal Control과 Reinforcement Learning의 교집합 부분으로 볼 수 있고 최근 강화학습 연구들도 Model-based RL으로 연구들이 많이 이루어지고 있습니다. Operations Research와 Reinforcement Learning의 교집합으로는 Large action-space Method로 볼 수 있는데, 기존의 아타리 게임과 같이 간단한 방향 조작키와 같은 action의 선택지가 적은 경우에 비해 의사결정을 내려야하는 상황이 복잡할 수록 즉, 문제가 더 어렵고 복잡할 수록 action의 선택지가 많아지기 때문에 action space가 더 커지는 방향으로 연구가 많이 이루어지고 있다고 볼 수 있습니다.
그럼 좀 더 자세히 MPC과 RL을 비교해보면, MPC는 그림과 같이 마치 어둠속에서 손전등을 키고 빛을 따라 하나의 길을 보듯이, 하나의 최적의 trajectory를 찾아 그 trajectory의 1 step을 실행시킵니다. 수학적으로 모델링한 최적식의 해를 구해서 계산과 실행을 반복하며 제어를 하는 것 입니다. 반면 RL은 search space를 MDP(Markov Decision Process)를 이용하여 정의하고 학습을 하며 시점 t에서의 최적의 action을 할 수 있도록 합니다. 두가지 방법 모두 Advanced 시킬 부분이 많이 남아있고 MPC는 non-linear 방향으로 나아가고 있으며 RL은 value-based나 policy-based 기반의 방법들과 함께 최근에는 인공신경망의 gradient기법을 이용하여 발전해나가고 있습니다. MPC와 RL의 비교는 최근 ICRA와 같은 로봇 제어 관련 학회들에서는 관심이 많은 주제이며 Michiel van de Panne (UBC) 교수님의 발표에서 좀 더 자세히 확인하실 수 있습니다.
Locomotion VS Recovery
이런 강화학습 방법론으로 4족보행의 Recovery Task를 풀기 위해서는 Recovery task에 대한 특성을 좀 더 살펴볼 필요가 있습니다. 기본적으로 족형(Legged) 로봇들은 안정적인 보행(Locomotion)을 기반으로 여러가지 task를 하는데에 초점이 맞춰져 있습니다. 예를 들면 보행로봇의 위에 Manipulator를 달아서 원하는 위치로 보행을 한 뒤 Manipulator로 컵을 집는 일과 같은 task를 수행하는 것입니다. 하지만 4족보행 로봇을 사용하기 위해 전제된 안정적인 보행이 실제로 로봇이 운용되는 환경에서는 여러가지 예측할 수 없는 변수들로 인해 만족될 수 없는 조건일 수 있으며 따라서 로봇이 넘어질 수 밖에 없다면 다시 보행을 할 수 있는 정상적인 상태로 돌아오기 위한 능력도 갖추고 있어야 합니다. 바로 이를 위한 로봇의 기능을 Recovery라고 할 수 있고 Recovery를 Locomotion task와 비교하여 특징 몇가지를 살펴보겠습니다.
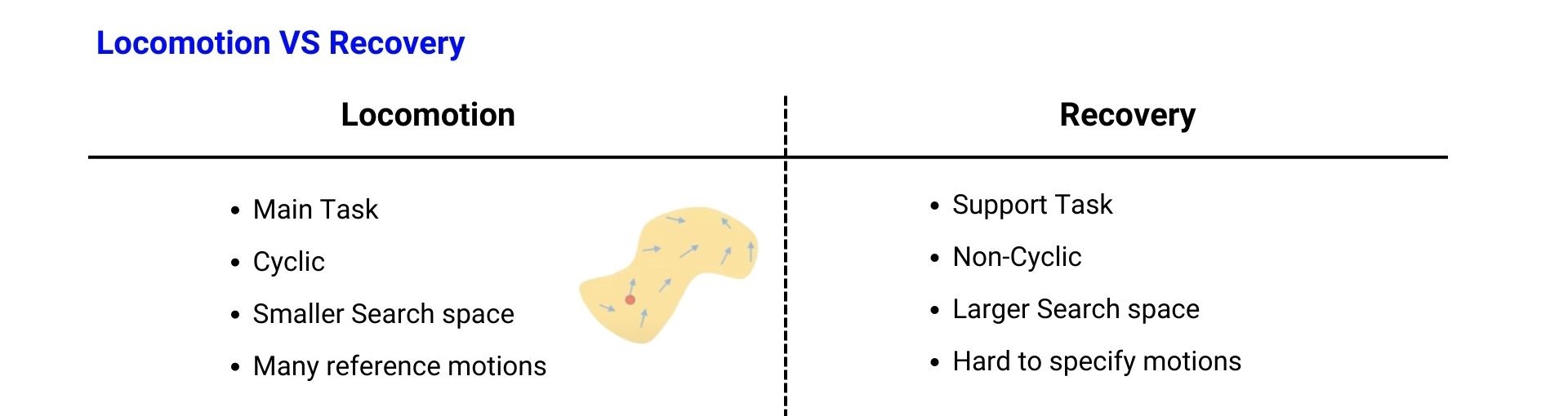
우선 Recovery는 앞서 이야기한 것과 같이 Locomotion이 메인이 되는 task인데 반해, 로봇의 운용 life cycle을 위한 support task라고 할 수 있습니다. 로봇이 적용되는 현장에서 메인 task들을 끊임없이 수행하기 위해 흐름을 유지시켜주는 장치라고 볼 수 있습니다. 다음으로 Locomotion은 보행을 할 때 로봇 다리의 움직임이 주기(period)를 가지는 Cyclic한 모션을 하는 것에 반해 Recovery는 넘어진(Fall) 자세로부터 다시 걸을 수 있는 서있는(Stand) 자세로 가기 위한 모션을 취해야 하기 때문에 Non-cyclic하고 case-by-case로 다양한 회복 모션들을 할 수 있어야 합니다. 따라서 Locomotion은 환경에 따라(지면의 마찰력이나 외력 등) 보행의 난이도가 달라지긴 하지만 로봇의 joint의 동작 범위, 즉 action의 search space로 생각했을 때 Recovery에 비해 좀 더 좁은 search space를 가지고 있다고 할 수 있습니다. 마지막으로 Locomotion을 수행할 때 참고할 수 있는 동물이나 사람의 모션 데이터들이 있지만 Recovery 같은 경우 참고할 수 있는 모션 데이터들이 많이 없고 일어나는 방법에 대해 메뉴얼 같이 각각의 단계를 명시하기 까다롭다는 점이 있습니다.
Method
Overview
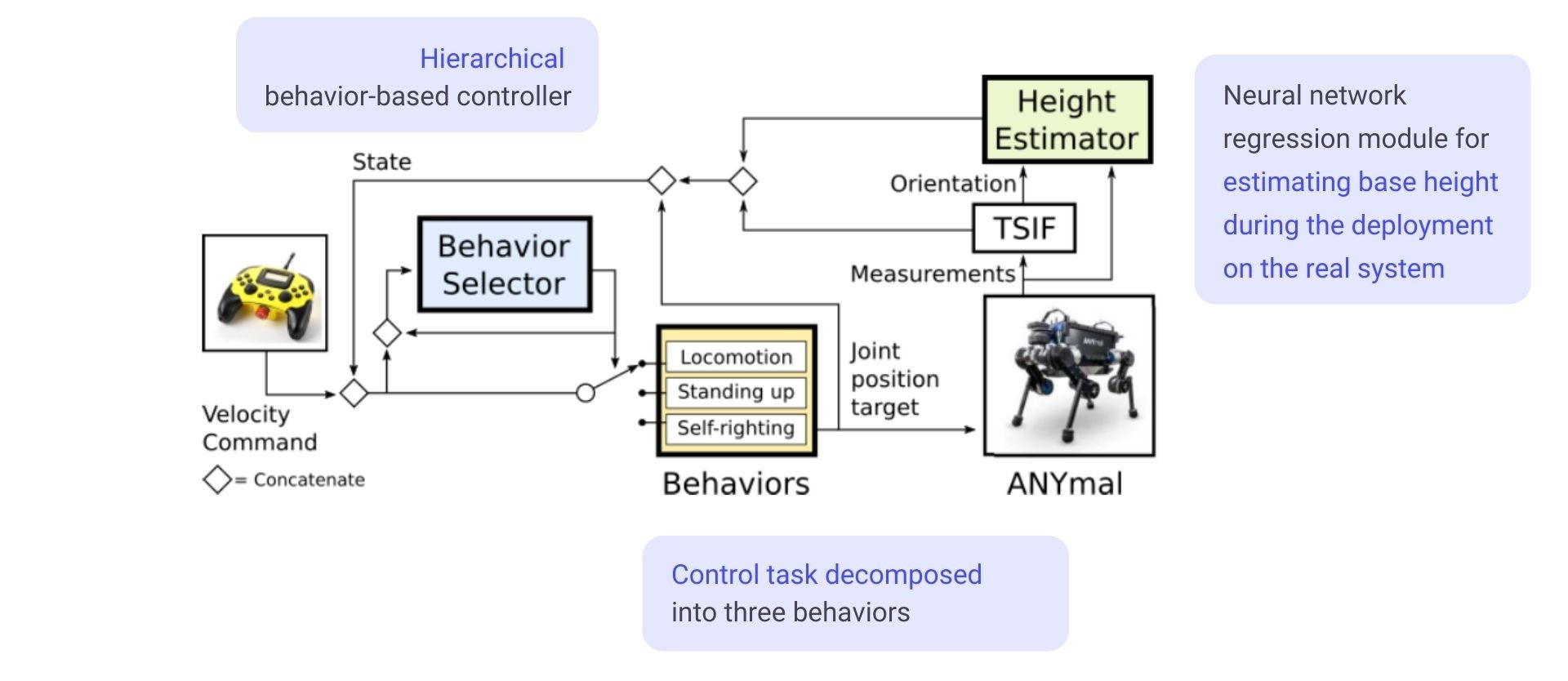
논문에서 제시한 전체적인 Control System의 모습은 아래 그림과 같습니다. 강화학습 알고리즘으로는 TRPO(Trust Region Policy Optimization algorithm)와 GAE(Generalized Advantage Estimator)를 사용했으며 제시된 방법에서는 크게 3가지 특징들이 있습니다.
Control Task Decomposed : Recovery하는 task를 3개로 Behavior들로 나누어서 각각의 Behavior를 수행하는 Control Policy를 학습
Hierarchical Structure : 여러개의 Behavior policies를 조율할 수 있는 상위계층의 Behavior Selector를 만들어서 계층적인 구조를 사용
Height Estimator : 로봇을 실제 운용할 때 필요한 상태 정보인 Height 값의 부정확한 정보를 보완하기 위해 Neural Network 사용(Regression model)
Behavior Policies
Recovery task를 여러개의 Behavior들로 나누어서 총 3개의 각각의 task, Self-Righting, Standing up, Locomotion가 있고 각 behavior을 담당하는 policy가 있습니다.
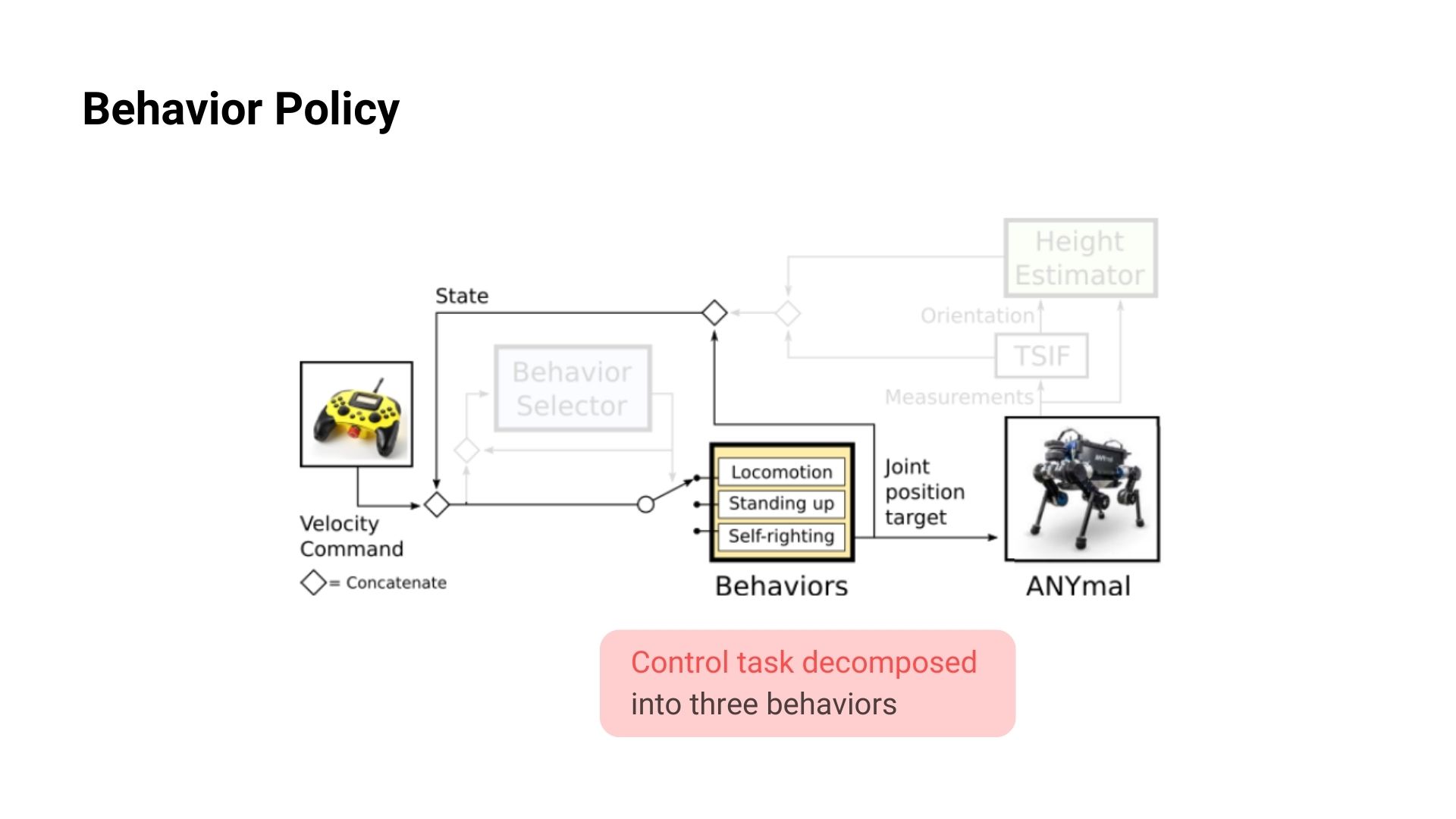
Self-Righting은 임의의 로봇의 넘어진 자세에서 로봇의 몸체(base)가 똑바로(뒤집어져 있거나 옆으로 돌아가 있지 않은 상태) 되어 있고 4개의 발이 지면에 닿아 있는 자세로 움직이는 것을 말합니다. Standing up은 Self-righting에서 만든 자세에서 4개의 다리들을 이용하여 일어선 자세로 만드는 것을 말합니다. 마지막으로 Locmotion은 Controller에서 주는 command를 기반으로 보행을 하는 것을 말하며 이때 command로는 forward velocity, lateral velocity, turing rate(yaw 방향)을 주어 움직이게 됩니다.

(1)Self-righting behavior
Self-righting을 학습하기 위해 policy에 들어가는 data(state 정보)로는 아래의 표에서 볼 수 있듯이 총 6개의 data가 있습니다. 그 중 e_g는 몸체 base의 z 방향으로의 단위 벡터로 몸체의 upright를 판단하기 위한 정보로 볼 수 있습니다.
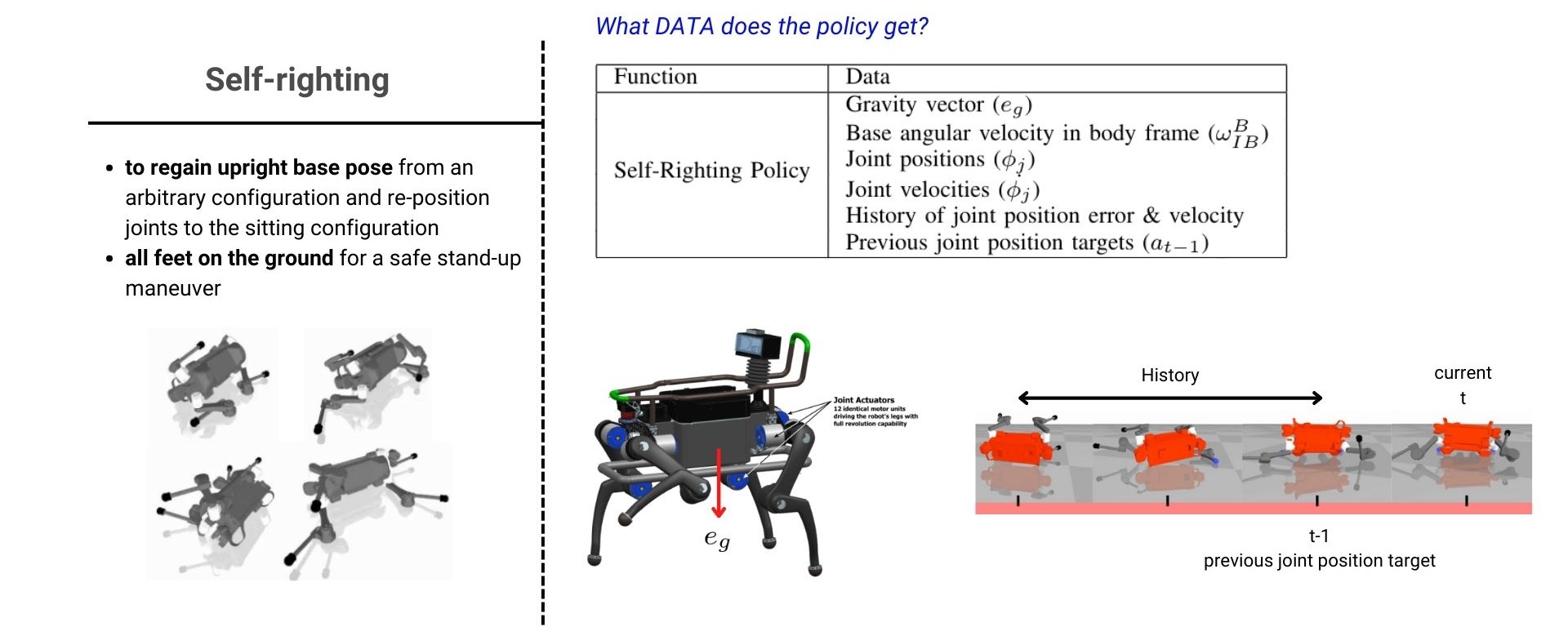
보통 강화학습에서는 reward를 최대화 하는 방향으로 학습(최적화)이 일어나지만 reward의 반대 개념인 cost의 값이 최소화하는 방향으로 학습을 시켰습니다. 아래의 식처럼 여러개의 cost term들이 있지만 그 중 self-righting에서 특징적인 cost term은 orientation cost term 입니다. 이 cost term은 c_o=\left\|[0,0,-1]^T-e_g\right\|로 계산되는데 이는 위에서 설명한 대로 policy network가 로봇 몸체의 base의 방향을 uprighting 하도록 학습되게 하기 위한 term이라고 볼 수 있습니다.

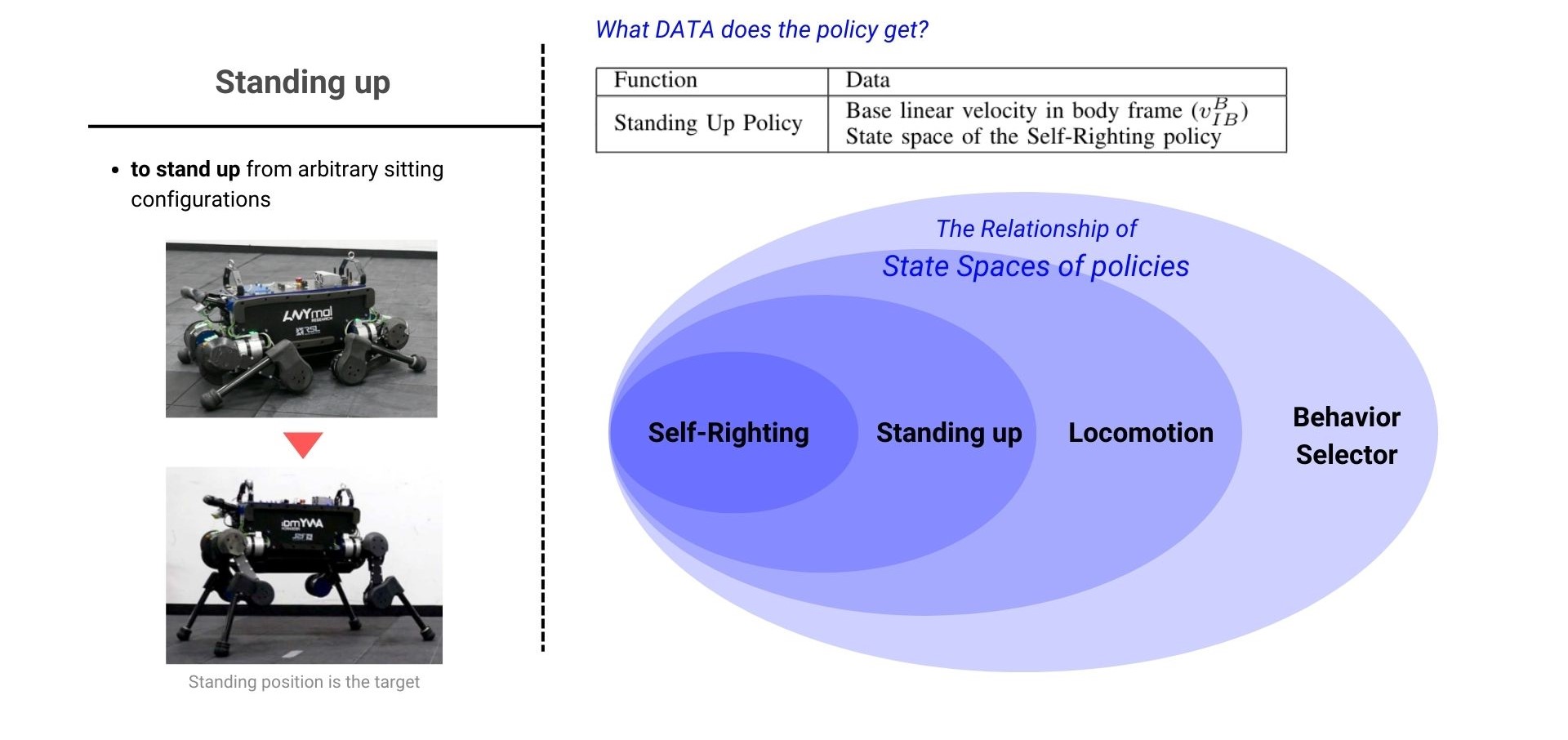
(2)Standing up behavior
Standing up은 이전의 Self-righting의 state 정보를 포함하고 더하여 Base linear velocity 정보까지 포함하여 policy의 input으로 들어가게 됩니다. Self-righting과 Standing up policy 간의 state 정보 포함 관계 뿐만 아니라 이후 소개할 Locomotion policy, Behavor Selector의 state 정보의 집합관계를 보면 다른 policy에 들어가는 정보를 포함하고 추가적인 data를 더하여서 Self-righting → Standing up → Locomotion → Behavior Selector 순으로 state space가 점점 더 커져가는 것을 확인할 수 있습니다.
Staning up behavior policy가 학습해야할 cost 최소화 식은 아래와 같이 여러 cost term들이 있지만 그중 height cost term이 특징적인 cost라고 볼 수 있으며 ANYmal 로봇이 서있을 때의 지면으로부터 몸체(base frame)까지의 거리, height이 0.35m보다 작을시에는 1, 아니면 0으로 계산합니다.

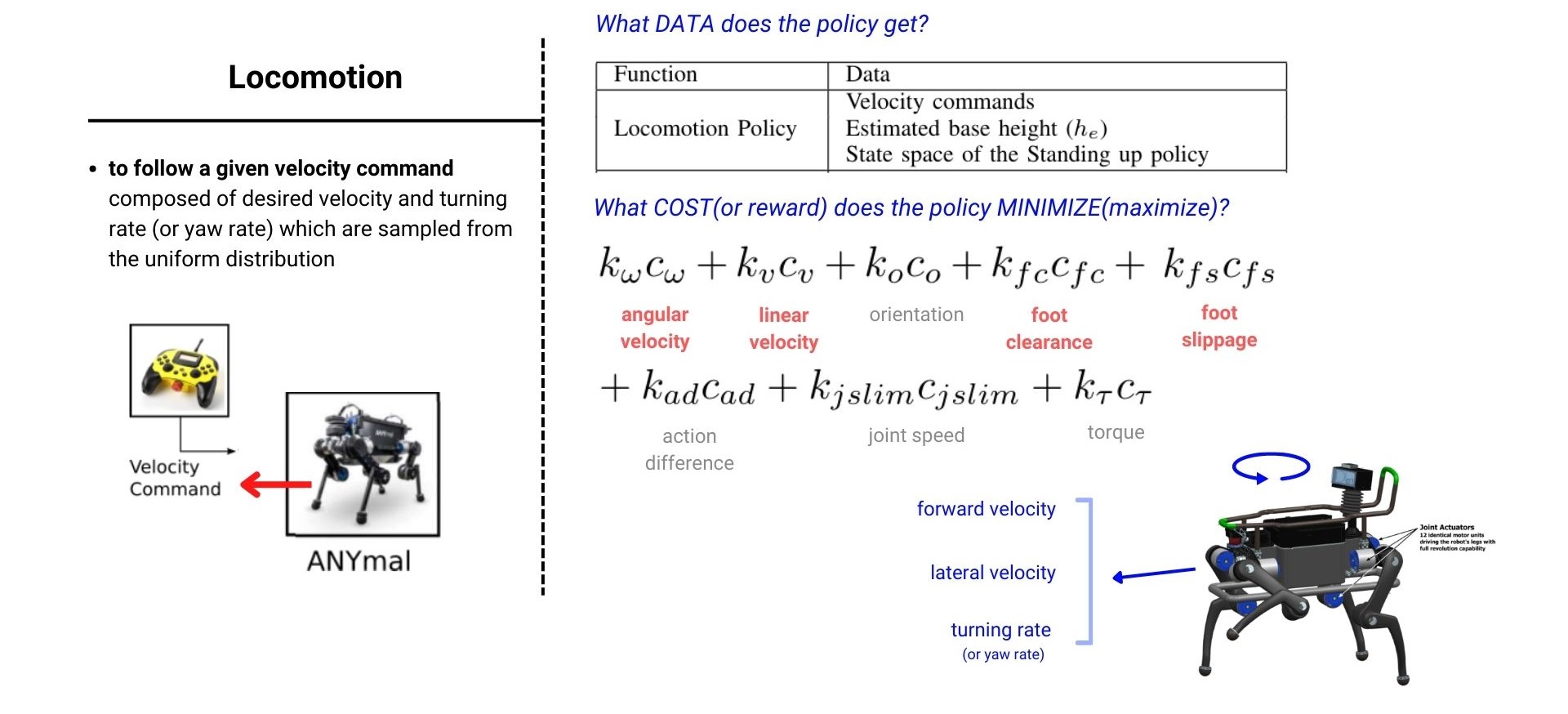
(3)Locomotion behavior
Locomotion task policy에는 input으로 command까지 들어가게 되면서 cost식에는 command를 잘 수행하는지 판단하도록 하는 angular velocity, linear velocity, foot clearance, foot slippage cost가 들어가는 것을 확인할 수 있습니다.
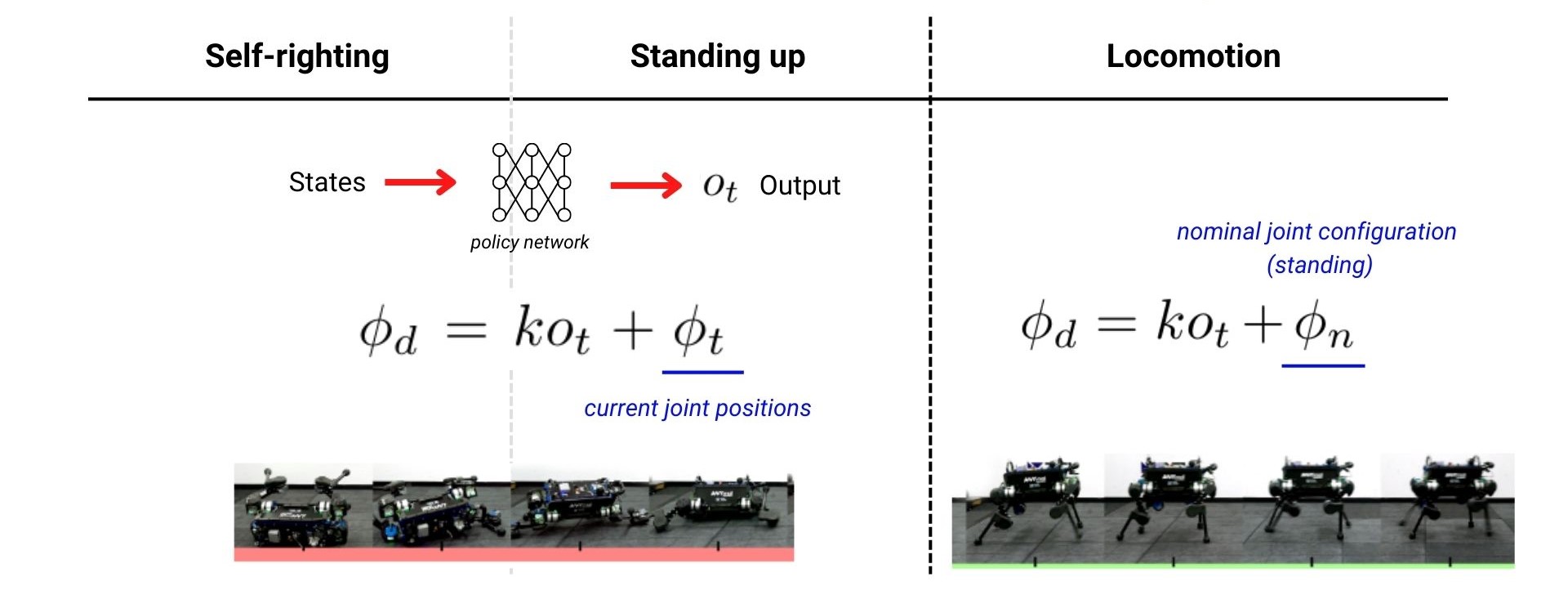
지금까지 policy network들의 input와 objective(=cost 최소화)에 대해서 이야기 했지만 결과적으로 network가 어떤 값들을 output 하는지, 그리고 실제로 그 output으로 어떻게 로봇을 움직이는지에 대해서는 아직 설명하지 않았습니다. 로봇을 움직이기 위해서는 timestep마다 로봇의 각 모터가 움직여야 하는 desired joint position을 구해서 해당 position으로 모터를 돌려주면 됩니다.

각 Behavior policy에서 나오는 output은 o_t이며 이는 로봇을 구동시키는 12개의 joint motor에 대응하는 실수 벡터입니다. 대응이라고 표현한 이유는 해당 실수값을 바로 joint의 desired position으로 사용하는 것이 아니라 좀 더 빠른 학습 수렴을 위해 desired joint position을 구하는 식을 거쳐 계산된 값을 사용하기 때문입니다. 우선 Self-righting과 Standing up task에서는 네트워크에서 나온 값 o_t를 현재 각 모터의 position인 \phi_t에 더해주어서 최종 desired joint position인 \phi_d 값으로 제어합니다. Locomotion에서는 현재의 joint position 대신, 로봇이 서있는 자세인 nominal joint configuration \phi_n에 o_t을 더해주어 최종 desired joint position인 \phi_d을 사용합니다.(o_t에 곱해지는 k는 하이퍼파라미터처럼 찾아야 하는 상수값입니다.)
Height Estimator
data-driven RL에서 policy에 들어가는 data의 quality는 매우 중요합니다. 따라서 실제 작동하는 로봇의 state를 추정하는 State estimation 또한 로봇에 RL을 적용하기 위해서 뗄레야 뗄수 없는 중요한 부분이라고 할 수 있습니다. 로봇에 모션 캡쳐와 같은 센서를 부착하지 않는한 실제 로봇의 base height값을 잘 알 수 없고 로봇이 정상적으로 보행할 때는 TSIF(Two State Implicit Filter)와 같은 State Estimation 기법을 통해 어느정도 추정할 수 있지만 넘어져서 base가 거의 바닥과 가까울 경우 추정값이 매우 불안정하게 됩니다. 따라서 해당 논문에서는 Regression Neural Network를 통해 height를 넘어진 상태에서도 잘 추정할 수 있도록 했습니다.
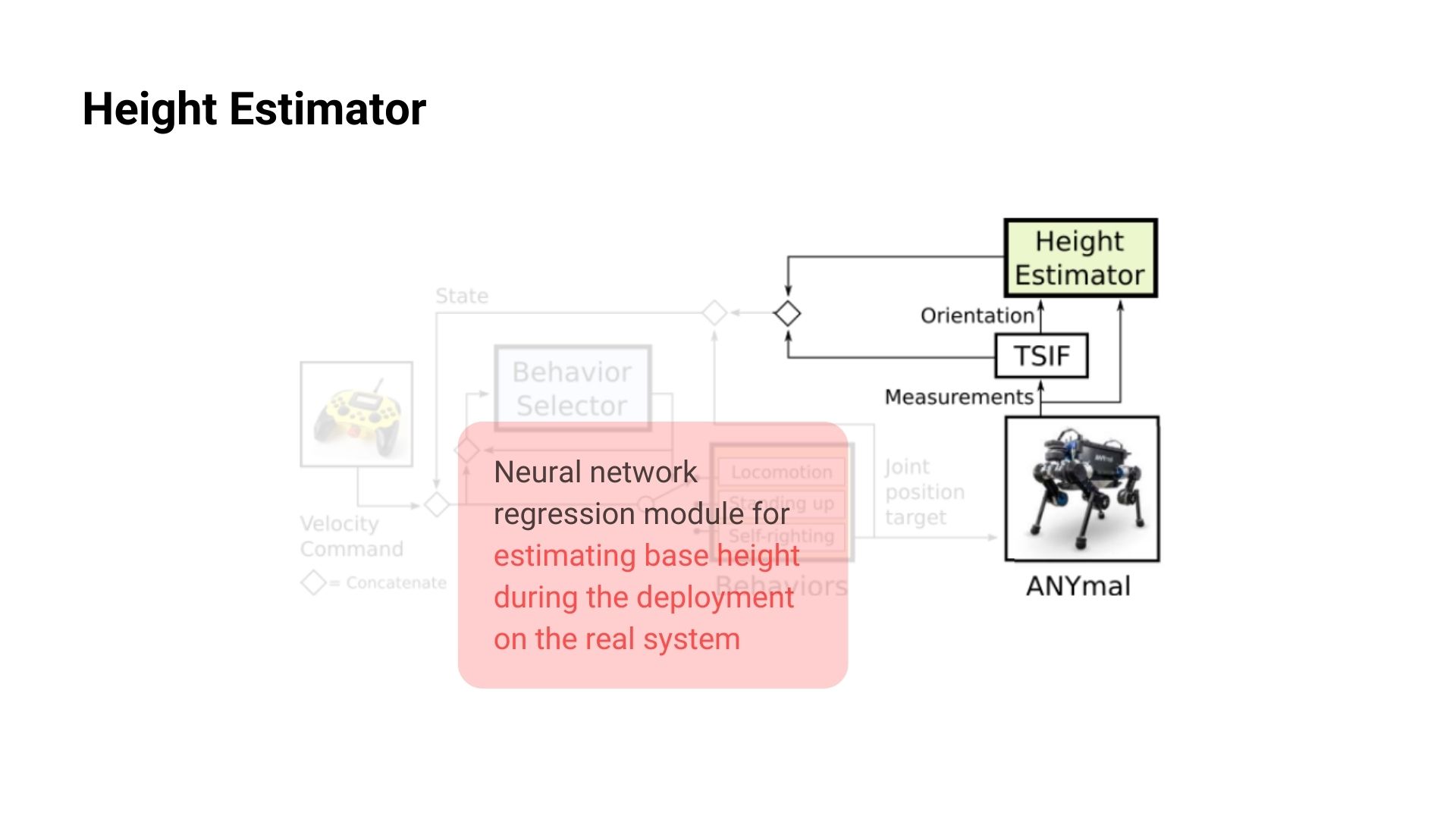
Height Estimator Network가 input으로 받는 data는 아래의 표와 같습니다. Output으로는 body의 IMU 값과 12개 joint들의 position을 출력하여 해당 값들을 가지고 forward kinematics를 이용하여 구한 height 값을 네트워크에서 추정한 값으로 사용합니다. 이 신경망은 강화학습으로 학습을 하는 것이 아니라 지도학습 방법으로 true 값을 맞춰가는 과정을 통해 학습하게 되는데 이떄 true data는 시뮬레이션 상에서는 쉽게 구할 수 있고 Regression model의 loss 값은 \sum_{j=0}^K\left\|h_j-h_\psi\left(s_j\right)\right\|^2으로 계산됩니다. (j: joint index, s_j: joint state, \psi: network parameter)

Behavior Selector
여러개의 behavior policy들을 어떻게 조율할 것인지는 상위 계층에 Behavior Selector를 NN을 이용하여 만들어서 학습시킵니다.
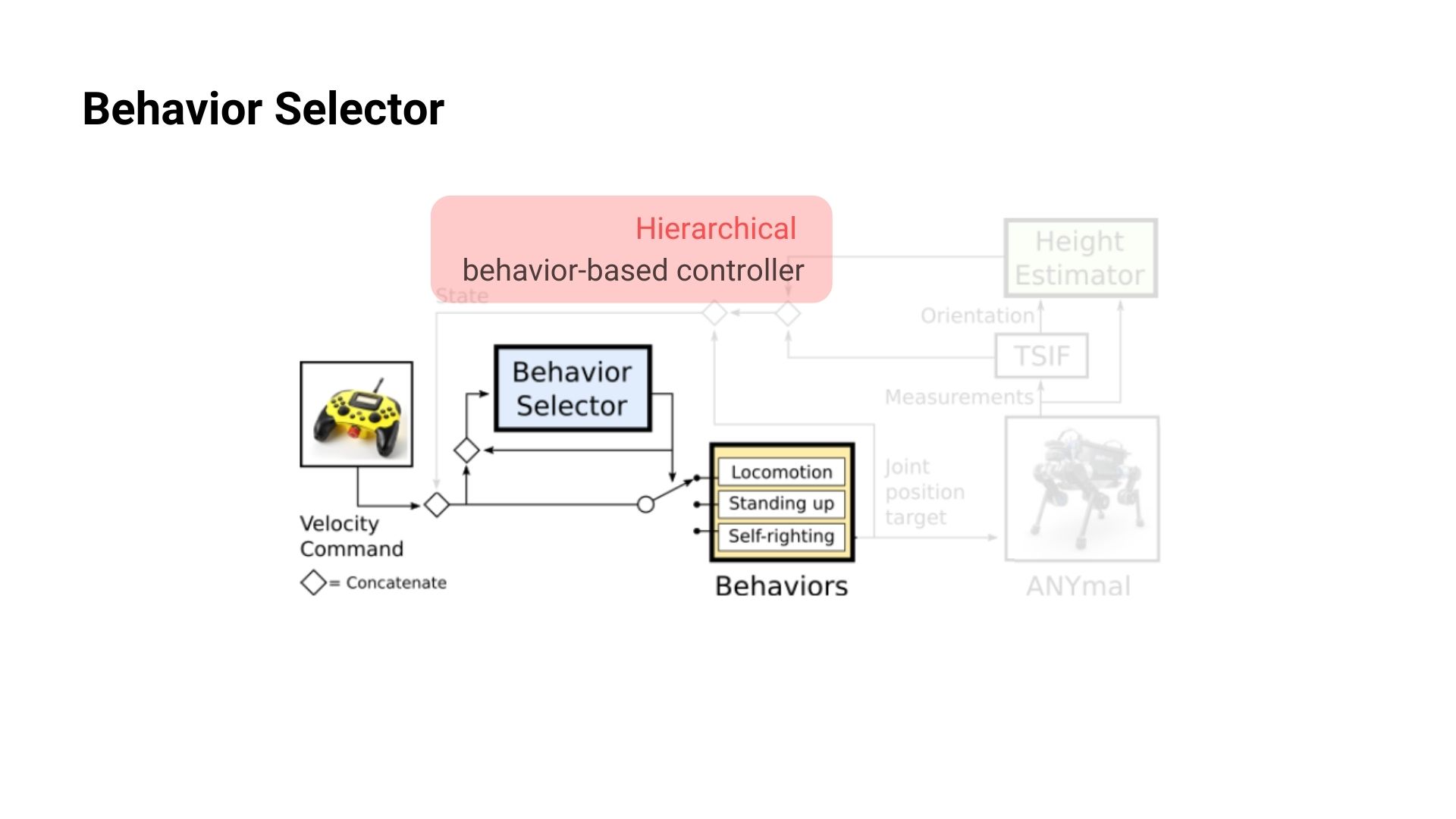
로봇의 상황에 맞추어서 적절한 behavoir를 하도록 behavior selector는 categorical distribution을 학습하게 됩니다. Behavior selector와 앞서 설명한 Height estimator는 3개의 behavior policy들이 다 학습이 된 후에 아래 그림의 오른쪽에 보이는 Algorithm1의 흐름에 따라 학습되게 됩니다. Behavior selelctor의 state 나cost는 locomotion과 매우 유사하고 해당 포스트의 appendix에 표로 정리되어 있으며 cost식 같은 경우에도 모터의 power efficiency를 위한 term 정도 추가된 것이기 때문에 해당 cost 식이 궁금하신분은 원문 논문에서 확인하실 수 있습니다.

Simulating ANYmal
로봇에 강화학습을 적용할 때 큰 이슈들 중 하나는 Sim-to-Real입니다. 시뮬레이션으로 실제 환경을 단순화하고 모사한 것이기 떄문에 시뮬레이션에서 잘 학습이되고 잘 동작하더라도 실제 로봇을 deploy했을때 잘 작동하지 않는 문제가 생깁니다. 따라서 실제 환경에서도 로봇이 경험하게 되는 noise들을 시뮬레이션에도 random하게 적용시켜 최대한 실제 상황과도 유사하게 만든 환경에서 학습을 하게 됩니다.
해당 논문에서도 Link length, Intertial property, Link mass, CoM(Center of Mass), Collision geometry, Coefficient of friction 등과 같이 물리적인 값들을 아래 표에서 볼 수 있듯이 일정 범위에서 random하게 값을 넣어주었고 policy의 input data가 되는 observation 값들에도 noise 값을 추가하여 Sim-to-Real 문제를 해결하였습니다. 이외에도 ANYmal 로봇 플랫폼에서 사용하는 SEA motor에 스프링과 같은 기계적 요소들의 변수로 인한 제어 이슈도 해결하기 위해 Actuator Network를 학습시켜 이를 해결하였습니다.
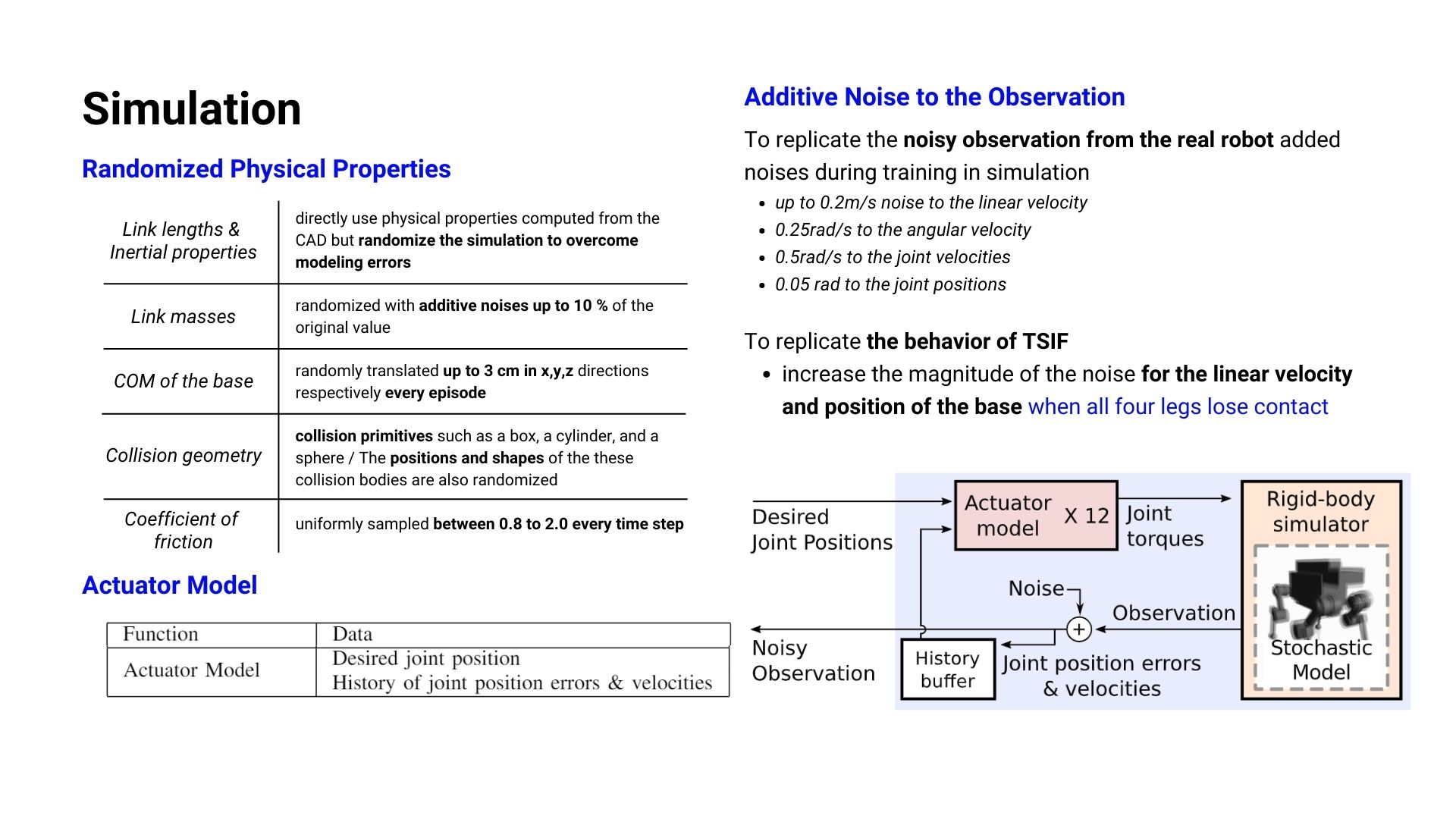
(위 요약에서 언급했던 대로 사실상 Actuator Network나 Height Estimator까지 NN이 추가되므로 4개가 아닌 총 6개의 NN이 사용되었음을 알 수 있습니다.)
Result and Discussion
논문에서 설계한 Recovery Controller의 실험 결과는 다음과 같이 (1) Recovery 성공률, (2) Height Estimator의 상태 추정 효과, (3) Behavior Selector의 (기존 방법론인 State Machine과 비교했을 때의) 경쟁력 3가지로 살펴볼 수 있습니다.
The success of recovery
Recovery 실험은 총 2가지로 진행되었는데 첫번째는 지면에 로봇을 임의의 position으로 넘어진 상황을 연출한 후 5초 이내로 일어날 수 있는지를 확인했고 두번째로는 로봇이 걷고 있을 때 발로 쳐서 넘어뜨린후 로봇이 다시 자연스럽게(각 behavior들 간의 switching이 자연스럽게) 일어나는지를 확인했습니다. 각각의 실험 모두 50번 이상씩 진행했으며이때 약 100번중 97번을 성공하여 97% 성공률을 보였습니다. (실패한 케이스들의 경우에는 joint의 position이 2\pi를 넘어가는 값으로 나올 때 잘 작동하지 않았다고 합니다.)

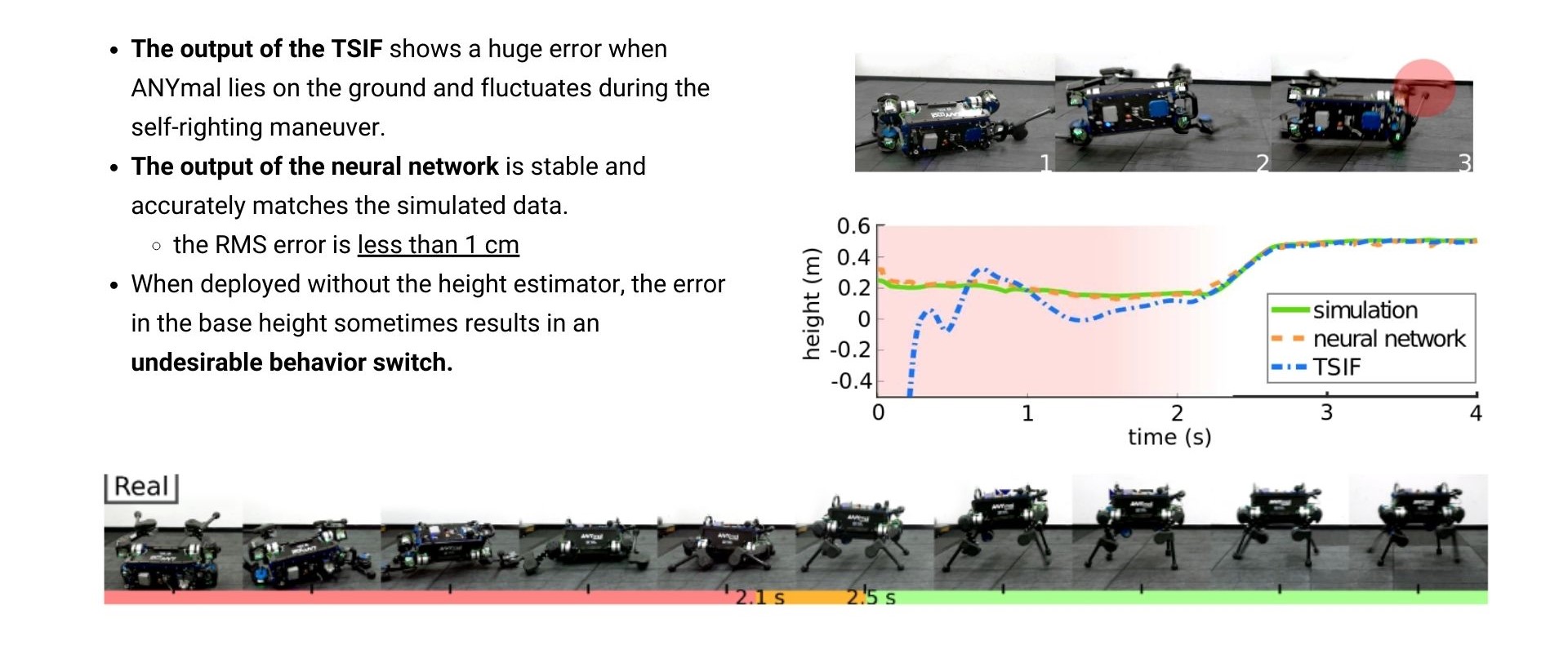
The effectiveness of Height Estimator
기존의 State Estimator TSIF(Two State Implicit Filter)만을 사용했을 때는 로봇이 바닥에 넘어져 있을 경우 error 값이 매우컸지마나 Neural Network를 통해 보정했을 때 오차가 1cm 미만으로 떨어지는 것을 확인할 수 있었습니다. 오른쪽의 height 그래프는 맨 아래 캡쳐되어있는 로봇의 일련의 모션과정 중에 height를 그래프로 plotting한 것인데 simulation(초록색)이 true값이며, TSIF만을 사용했을 때(파란색)는 로봇이 넘어져있을 때 오차가 큰데 반해 neural network(주황색)은 simulation data와 거의 같음을 확인할 수 있습니다.
The competitiveness of Beahavior Selector
기존의 제어방법들에서는 여러가지 mode를 조율하기 위해서 FSM(Finite State Machine)을 많이 사용합니다. 특정 조건을 if에 넣어주어서 각 mode를 transition하는 기법인데 논문에서도 강화학습으로 학습한 Behavior Selector의 비교를 위해 기존의 FSM 방식을 활용하여 State Machine을 만들어서 비교했습니다. FSM 방식은 여전히 corner case들이 Behavior Selector에 비해 많이 존재했고 각 behavior들 간의 전환도 자연스럽지 않았습니다.

Review
아직 minor 한 주제인 Recovery task에 대해 집중적으로 잘 분석하고 성과도 확실히 보여준 논문이라고 생각합니다. Control system을 working하게 하기 위해 각 파트들을 어떻게 설계하고 학습해야할 지 많은 고민을 했다는 것을 느낄 수 있었습니다. 여전히 flat ground에서만 진행된 연구이기에 slope가 있는 환경이나 다른 object가 있는 좀 더 실제 상황과 비슷한 상황에 대한 recovery가 해결되기 위해서는 연구되어야 할 부분이 충분히 많은 것 같습니다.
Appendix

Reference
orginal paper : https://arxiv.org/abs/1901.07517