📃WASABI 리뷰

이번 포스팅은 WASABI: Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations 논문을 읽고 정리한 내용입니다. 4족 보행 로봇 연구에서 많은 연구 성과들을 발표하는 스위스의 ETH Robotic System Lab과 독일의 Max Plank Institude for Intelligent Systems에서 발표한 논문으로, 강화학습에서 중요한 부분들 중 하나인 reward design에 대한 고민을 generatvie adversarial method(WGAN, Wasserstein GAN)를 통해 해결할 수 있음을 보여주었습니다.

보행 로봇의 모션 제어에서 기본적인 보행뿐만 아니라 다양한 다이나믹한 모션을 수행하도록 로봇의 퍼포먼스를 끌어올리는 방향으로 연구가 활발하게 진행되고 있습니다. 여기서 말하는 다이나믹한 모션들로는 로봇이 공중에서 한바퀴 돌아야 하는 backflip과 같은 기존의 전통적인 보행 제어 연구를 기반으로 rule-based로 제어하기에는 매우 어려운 모션들을 말합니다. 로봇이 이런 모션들을 수행하도록 수학적으로 자세히 명시하고 그리고 모든 물리적 환경요소들을 고려하여 제어하기 어려울 때, 강화학습이라는 인공지능 프레임 워크를 이용하여 reward라는 보상체계를 기준으로 trial-and-error를 통해 모션을 학습하도록 하는 것이 직관적으로 매우 좋은 해결책으로 보입니다.
하지만 다이나믹한 모션을 각 task로 정의하고 우리가 원하는 방향대로 로봇이 모션들을 학습되기 위해서는 reward를 잘 정의해주어야 하는데 이 과정이 만만치 않게 까다롭고 어려우며, 오히려 수학적인 동역학 모델을 기반으로 제어할 때보다 분석적인 접근이 어렵기 때문에 reward design이라는 과제를 해결해야만 우리가 원했던 다이나믹 모션들을 강화학습을 이용하여 로봇이 수행할 수 있을 것 입니다. 바로 이 부분을 생성모델로 유명한 GAN 모델들 중 하나인 WGAN을 이용하여 해결하고자 했으며 해당 논문에서 가장 흥미로웠던 접근법은 강화학습의 policy를 GAN의 generator 관점으로 바라보고 reward를 추론하도록하는 프레임 워크를 만들었다는 점이었습니다. (이후 관련해서 더 논문들을 찾아보니 생성모델과 강화학습은 닮은 점이 많은 것 같습니다. 관련해서 흥미롭게 읽었던 다른 논문 Connecting Generative Adversarial Networks and Actor-Critic Methods도 관심이 있으시다면 가볍게 읽어보시는 것을 추천드립니다.)
Introduction
강화학습은 정말 매력적인 인공지능 학습법 중 하나라고 생각합니다. 저도 직관적이고, 어떻게 보면 가끔 우리네 인생의 모습을 단순하지만 명료하게 보여주는 것 같아 그런 강화학습의 매력에 빠져 지금까지도 열심히 이해하고 공부하려고 노력하고 있는 것 같습니다. 많은 분들이 인공지능을 처음에 학습할 때 마주하게 되는 것은 “지도학습(Supervised Learning)”인데 이론 공부를 어느정도 마친 후, 관련해서 vision이나 자연어 등의 프로젝트를 시작하면 처음에 마주치는 난관은 데이터셋 구축이라고 생각됩니다. 빅데이터 기반으로 동작되는 방법론이다 보니 Garbage In, Garbage Out이 안되도록 조심해야하고 내가 원하는 커스텀 데이터 셋을 구축하는 데만 엄청난 에너지를 쏟아야 합니다. (오픈 데이터셋이나 transfer learning 기법 등을 이용해서 해결하기도 하지만요.)
하지만 강화학습에서는 데이터 셋이 필요없습니다! 왜냐하면 강화학습 프레임워크가 동작하면서 trial-and-error를 통해 interaction data를 만들게 되고 이를 기반으로 학습이 되는 것이기 때문입니다. 하지만 안타깝게도 강화학습에도 데이터셋 구축의 어려움 만큼이나(혹은 그 이상으로) 어려운 점이 있습니다. 바로 환경(Environment) 구축입니다. 유명한 DeepMind의 시니어 연구자는 Behind every great agent, there’s a great environment라고 이야기 했을 정도로 강화학습에서는 환경 구축에 학습의 성패가 달렸다고 해도 과언이 아닙니다.

강화학습의 현실에 대해 좀 더 살펴보겠습니다.(로봇틱스 분야 강화학습 연구자의 관점이므로 다른 분야에서 강화학습을 도입할 때의 관점과는 차이가 있을 수 있습니다.) 먼저 첫번째로 딥러닝 기반 강화학습 또한 빅데이터 기반으로 학습되는 것이기 때문에 (1)많은 interaction data가 필요합니다. 따라서 로봇틱스에 강화학습을 도입하기 위해서는 로봇을 여러번 돌리며 데이터를 얻어야 하는데 (연구 초기에는 실제로 로봇을 연구자가 여러번 다시 셋팅하고 실험을 하며 데이터를 얻었다고는 하지만..) 사실상 불가능에 가깝기 때문에 시뮬레이터를 활용하여 데이터를 얻게 됩니다. 하지만 이 점에서 실제 물리적인 세계에서 로봇이 구동되어 얻어지는 데이터와 물리적인 세계를 모사한 시뮬레이터에서 얻게된 데이터는 차이가 존재할 수 밖에 없기 때문에 Sim-to-real이라는 또 하나의 연구과제가 만들어지게 됩니다.
다음으로는 앞서 이야기 했던, (2)강화학습의 환경 구축이 잘 되어야 제대로 학습이 될 수 있다는 것입니다. 여기서 환경 구축, 혹은 강화학습의 수학적 모델링인 MDP(Markov Decision Process)의 요소들을 잘 정의해주어야 한다는 것은 사진에서 보이는 강화학습 프레임워크에 있는 State, Reward, Action 등을 풀고자 하는 문제에 맞게 잘 정해주어야 한다는 것입니다. 저는 강화학습 알고리즘 연구자가 아니고 강화학습을 활용한 로봇제어 연구자이기에 같은 강화학습 방법론을 보더라도 알고리즘 연구자와 어플리케이션 연구자가 보는 환경의 디테일이 많이 다른 것을 느꼈었습니다. 위 사진에서 같은 quadruped walking robot의 locomotion(보행) task를 생각할 때, 강화학습 알고리즘 논문들은 Ant와 같은 단순한 rigid model을 생각하고 실험을 하지만 강화학습을 실제 로봇에 적용하려고 보면 로봇의 각 모터의 특성, 센서등을 고려한 State, Reward, Action을 정의해야 하기 때문에 훨씬 복잡합니다. 사실 환경의 요소들 중, State와 Action은 각 도메인 마다 관례적인 정의 방법들이 있고 로봇의 센서들이 한정적이기 때문에 어느정도 정해져있다(limited)고 볼 수 있지만 Reward는 강화학습에서 학습의 motivation이 되는 가장 중요한 부분이자 수행하고자 하는 task에 영향을 가장 많이 받는 부분이기 때문에 가장 정의하기가 어렵습니다. 따라서 이런 어려움을 해결하고자 하는 또 하나의 연구 방향을 Reward Engineering이라고 지칭하기도 합니다. 이번 논문에서는 바로 이점을 파고든 것이라고 볼 수 있습니다.
어떤 Decision Process(의사결정 방법)를 학습한다고 생각했을 때 가장 직관적으로 떠오르는 방법이 무엇인가요? 그냥 잘하는 사람을 따라하는 것입니다. 이를 Imitation Learning 혹은 Behavior Cloning이라고 하는데(구별을 위해 이하 내용에서 Plain Imitation Learning이라고 칭하기도 함.) 한가지 예시로는 운전을 잘하는 인공지능(Agent)을 만들고 싶다면 운전을 잘하는 사람의 데이터를 그대로 따라하도록 학습하면 될 것 입니다. 이 방법은 Expert의 State-Action pair를 데이터 셋으로 보고 지도학습을 한 Agent를 만드는 것인데 Expert의 데이터만 학습하다보니 error가 들어가게 되고 generalization도 잘 되지 않습니다.
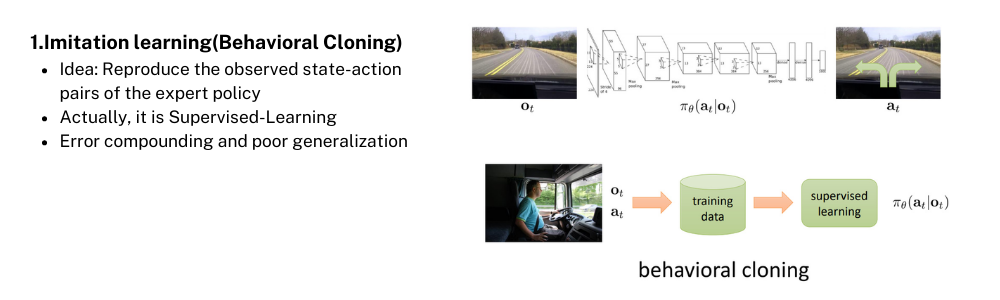
이에 대한 보완으로 GAIL(Generative Adversarial Imitation Learning)이라는 방법이 제안되었습니다. 이름에서도 볼 수 있듯이 Generative Adversarial Network(적대적 신경망)와 Imitation Learning(모방 학습)이 합쳐진 학습 방법인데, Expert의 state-action 분포를 True data distribution으로, 학습하는 Agent의 Policy를 True data distribution을 따라가고자 하는 Generator로 보는 것 입니다. 앞서 이야기한 plain imitation learning과 비교해보면 pair data point에 대해 맞춰가는 학습이 아닌 data distribution이라는 확률적 스펙트럼을 이용해서 더 generalization을 잘할 수 있는 해결책을 제안한 것으로 이해할 수 있을 것 같습니다. Data distribution을 학습하는 방법들은 생성 모델 분야에서 활발히 연구되고 있고, 이 중 GAN이라는 적대적 신경망 방법에서 Generator와 Discriminator라는 개념을 Imitation Learning에 적용한 것이라고 볼 수 있습니다.

GAIL의 방법론들 중 하나로, AMP(Adversarial Motion Priors)라는 방법이 있습니다. 이번 포스팅에서 소개되는 알고리즘인 WASABI와 AMP 모두 GAIL이라는 방법론 안에 속해있고, 둘을 비교해서 생각해보면 좋기 때문에 간략하게 짚고 넘어가보려고 합니다. AMP는 Motion data, 예를 들면 동물의 움직임에서 따온 expert data를 가지고 로봇 agent의 모션이 좀 더 자연스럽게 움직임을 학습할 수 있도록 합니다. Discriminator가 Motion data에서 나온 State-transition(S_t \rightarrow S_{t+1})인지 아니면 학습 중인 Policy(Generator 역할)에서 나온 State-transition인지를 구별하여 실제 동물의 움직임처럼 자연스러운 스타일을 학습 할 수 있도록 보조적인 Style Reward(r_{style})을 기존의 강화학습 프레임워크 안에 추가해줍니다. State-action pair를 가지고 학습하는 Plain imitation learning과 다르게, State-transition을 보고 Discriminator가 판단하는 것이기 때문에 expert의 Action에 대한 정보는 필요가 없습니다.
AMP 방법에서는 자연스러운 모션에 초점을 맞추었다는 것을 짚어볼 필요가 있습니다. Walking, Jumping과 같은 다이나믹한 주요 모션 task에 대한 reward가 아니라 학습할 때 자연스럽지 못한 모션으로 학습 방향이 튀지 않도록, 말 그대로 보조적인 모션 스타일을 잡아준 것입니다. 따라서 이런 자연스러움을 학습하기 위해서는 Motion data는 로봇의 pose configuration에 대해서 하나하나 명시되어 있어야 합니다. 이를 well-defined된 task이어야 한다는 말로 바꿔 말할 수 있는데, 로봇의 joint(관절) position이 timestep 마다 어떻게 움직여야 하는지 수치적으로 다 명시되어 있는 Motion data가 있어야 한다고 볼 수 있습니다. 이렇게 주요 모션 Task reward 디자인에 고려가 아닌 Style reward 디자인에 GAN 방법을 도입한 AMP 방법에 반해 WASABI는 Task reward에 GAN 방법을 도입했다는 점에서 가장 큰 차이점이 있다고 볼 수 있습니다.
GAN
적대적 신경망에 대해 기본적인 이론부터 시작해보겠습니다. GAN은 생성 모델을 학습하기 위한 방법론 중 하나로 Generative, 어떠한 새로운 데이터 생성을 하는, Adversarial 게임과 같이 Discriminator와 Generator라는 2개의 알고리즘 모듈이 경쟁을 하며 학습을 하는 방법론 입니다. 아래 사진에서 보이는 예시로 보면 진짜 모나리자 그림이라는 Real example을 보고 이를 모사한 작품을 파는 화가를 Generator라고 생각해볼 수 있습니다. 그러면 미술 작품 감별사인 Discriminator는 이 작품이 진짜 모나리자 그림인지 아니면 화가가 모사한 가짜 모나리자 인지 판단하게 됩니다. 당연히 Generator 입장에서는 Discriminator가 감별하기 어렵게 점점 더 진짜같은 모나리자를 그리게 되고(new data) Discriminiator 입장에서는 진짜와 가짜 사이에 더 자세하고 민감한 차이를 찾아내어 Generator의 모사품을 찾아내려고 할 것 입니다.
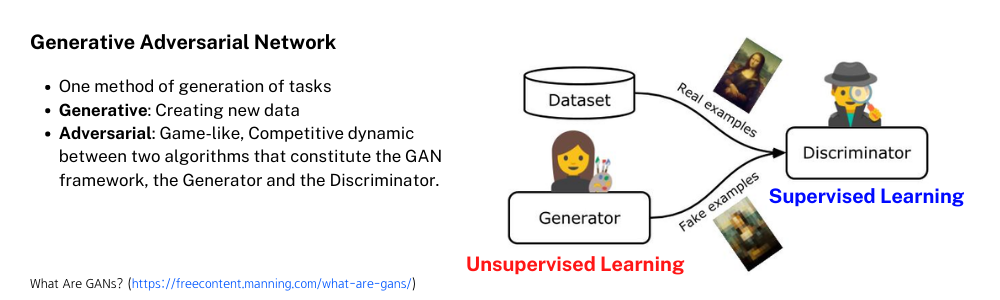
이러한 GAN의 학습 과정에는 지도 학습과 비지도 학습이 모두 들어있습니다. 우선 Discriminator 입장에서는 진짜와 가짜 라벨을 가진, 인풋 데이터가 들어오면 2개의 카테고리들 중 하나를 선택하는 지도학습을 하게 됩니다. Generator는 비지도 학습으로 latent code라는 일종의 trigger 요소인 어떤 벡터를 인풋으로 받으면 진짜 data distribution과 가까운 데이터인 new data를 생성하게 됩니다.
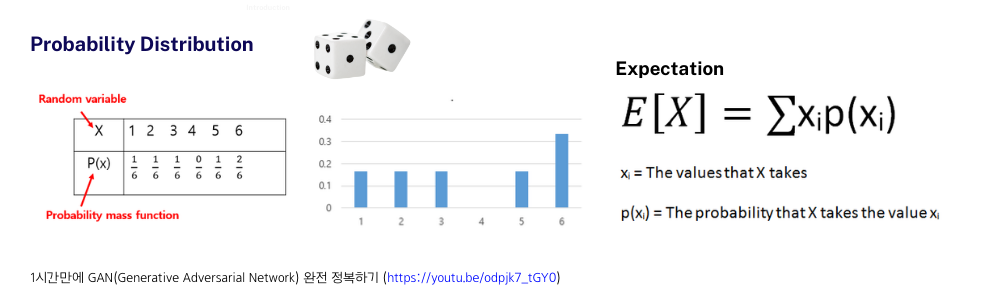
잠깐 data distribution이라는 개념이 GAN에서는 중요한 개념이므로 Probability Distribution(확률 분포)을 간단하게 짚고 넘어가겠습니다. 확률 분포란 어떤 사건을 대변하는 랜덤 변수들의 확률 분포라고 볼 수 있습니다. 주사위를 총 6번 던져서 1, 2, 3, 5가 각각 1번씩 그리고 6이 2번 나왔다면 아래와 같은 확률 분포 그래프를 그릴 수 있고, 이때의 Expectation(기댓값)을 구해보면 1 \cdot \frac{1}{6} + 2 \cdot \frac{1}{6} + 3 \cdot \frac{1}{6} + 4 \cdot \frac{0}{6} + 5 \cdot \frac{1}{6} + 6 \cdot \frac{2}{6} = \frac{23}{6} \eqsim 3.8 임을 알 수 있습니다.
이미지를 데이터 포인트 x라고 하고 우리가 가지고 있는 사람 얼굴 이미지 데이터 셋의 분포가 왼쪽의 분포와 같다고 한다면, 여러개의 모드(mode)가 있는데 가장 높은 확률의 mode에서는 금발 여성의 얼굴이 있고 상대적으로 낮은 확률로 흑발의 안경 쓴 남자의 얼굴 이미지가 있음을 알 수 있습니다. 또한 mode가 아닌 매우 낮은 확률을 보이는 분포의 꼬리 부분을 보면 매우 이상한 얼굴 이미지들이 나오는 것을 알 수 있습니다.
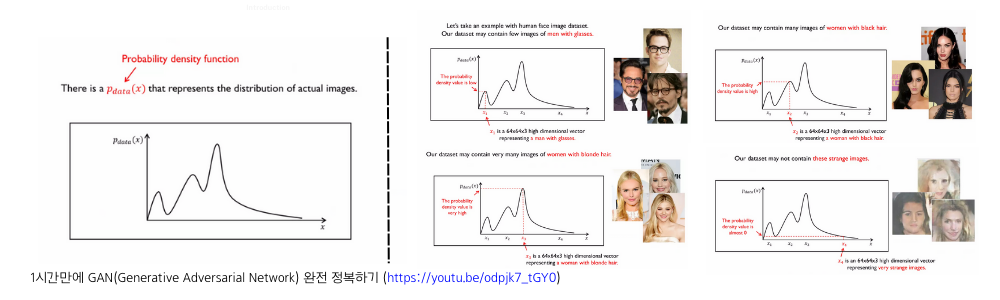
바로 우리가 가지고 있는 이미지 데이터 셋 분포(빨강색)과 유사한 데이터 분포(파란색)를 학습하는 것이 생성 모델의 목표이고 이를 Discriminator와 Generator를 가지고 학습하도록 하는 것이 GAN입니다.
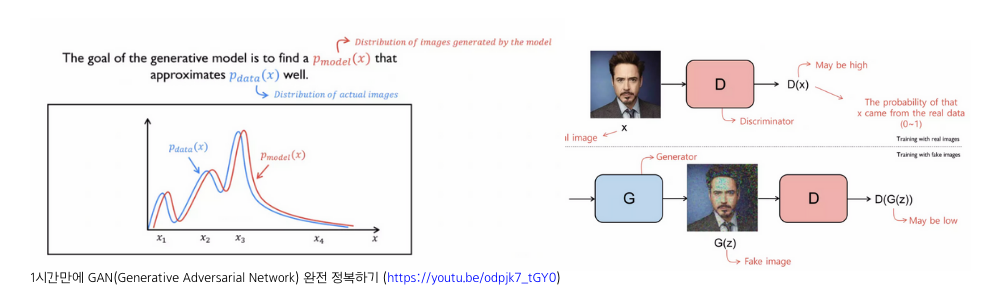
Discriminator의 Objective Function(V)을 보면, 먼저 첫번째 term은 데이터 x는 true dataset distribution인 p_{data}에서 샘플링 되었을 때 Discriminator는 이를 진짜라고 판별해야 하고 이는 output 1(true label)을 출력해야하는 방향으로 학습되어야 합니다. 두번째 term은 fake dataset distribution인, 즉 generator가 만든 데이터일 경우에 가짜라고 판별해야 하고 output 0(fake label)을 출력해야 합니다. 따라서 2개의 term을 모두 maxmization하는 것이 Discriminator의 목표이기 때문에 \text{max}_DV(\cdot)이 됩니다.

Generator의 Objective Function을 보면, 첫번째 true dataset distribution에서 샘플링 되는 부분은 Generator와 상관이 없습니다. 두번째 term에서 Generator에서 나온 ouput new data를 Discriminator에게 넘겨주었을 때 1(true label)로 착각하도록 만들어야 하므로 \text{min}_GV(\cdot)이 됩니다.

WGAN
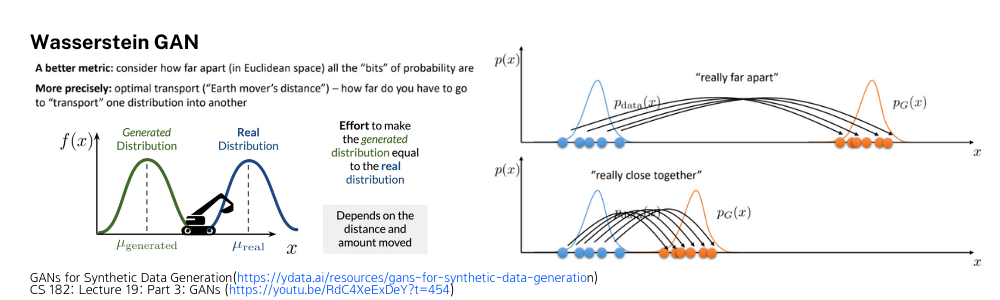
위에서 설명한 기본적인 GAN을 잘 학습했을 때 확률분포를 그려보면 다음과 같이 Discriminator의 판별 분포가 빨간색 그래프처럼 그려지는 것을 알 수 있습니다. 완벽하게 true distribution인 p_{data}에 대해서는 1을, generated distribution p_G에 대해서는 0을 보여주고 있지만 이런 상황에서는 유의미한 학습이 일어나기 힘듭니다.
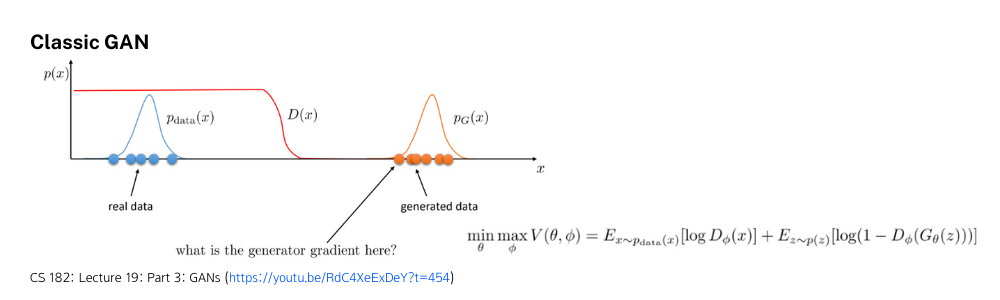
Optimal한 Discriminator를 가정하고 Objective function을 다시보면 p_{data}와 p_G가 너무 멀리 떨어져 있어서 사실상 계산된 V(\cdot)값이 0이기 때문입니다. 따라서 Generator가 두 분포가 가깝도록 만드는 방향으로 학습을 해야 하는데 Classic GAN의 Objective Function에는 이러한 정보를 알려줄 수 있는 부분이 수학적으로 모델링이 되어 있지 않습니다.
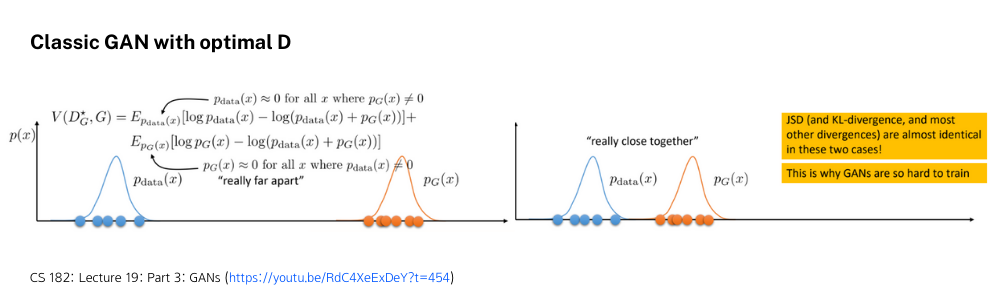
따라서 분포들간의 먼 정도를 모델링할 수 있는 WGAN(Wasserstein GAN)이 제안되었고 이에 대해서는 수학적으로 매우 딥한 내용이 있지만 본 포스팅에서는 간단하게 개념적으로 공사장의 포크레인을 이용하여 이해하고 넘어가겠습니다. Wassertein Distance는 Earth mover’s distance라고도 불리는데 이름에서 직관적으로 이해할 수 있듯이, 두 분포를 어떤 흙더미라고 생각하고 우리가 Generated Distribution에 있는 흙들을 Real Distribution의 모양대로 흙들을 옮긴다고 했을 때 드는 cost가 distance로 정의된다고 볼 수 있습니다. (수학적으로 더 궁금하신 분들은 Implicit DGM 29 | Wasserstein Distance with GAN을 추천합니다.) 본 연구에서는 이 WGAN을 이용하여 reward 디자인을 했습니다.
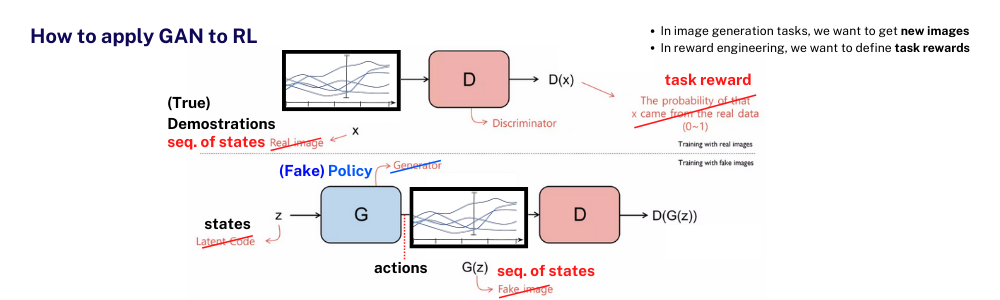
RL with GAN
GAN 내용을 설명할 때 이미지 생성 분야의 예시가 직관적이고 쉽기 때문에 이를 가지고 설명하다 보니 문득 그래서 강화학습에서 어떻게 GAN을 사용하는데? 라는 의문이 생길 수 있습니다. 다시 강화학습에서의 여러 어려움들 중 Task reward를 잘 정의해주기가 어렵다는 점을 상기시켜보면 Task reward를 Discriminator가 결정해줄 수 있지 않을까라는 아이디어를 떠올려볼 수 있습니다. 모션의 reference가 될 수 있는 demonstration의 일련의 state들이 true distribution이 되고, policy에서 나오는 일련의 state들이 generated distribution이 되어서, Discriminator가 두 분포를 못 구분할 정도를 task reward로 정의한다면 policy가 demonstration에서 나타난 다이나믹한 모션들을 따라하도록 학습할 수 있는 지표가 될 수 있을 것 입니다. 이전에 locomotion이나 backflip 등의 각각의 모션마다 task reward를 hand design 할 때는 각 모션에서 보행 로봇의 발이 어떻게 움직여야 하는지, 몸체의 속도가 어떠해야 하는지 일일이 reward로 고려하고 여러 reward term들을 weighted sum하는 방식이었지만 이 GAN 방식을 이용하면 각 모션에 대한 demonstration의 state들을 보고 어떤 모션을 어떻게 따라해야하는지 agent의 policy가 알아서 task reward를 높이는 방향으로 학습할 수 있는 것 입니다.
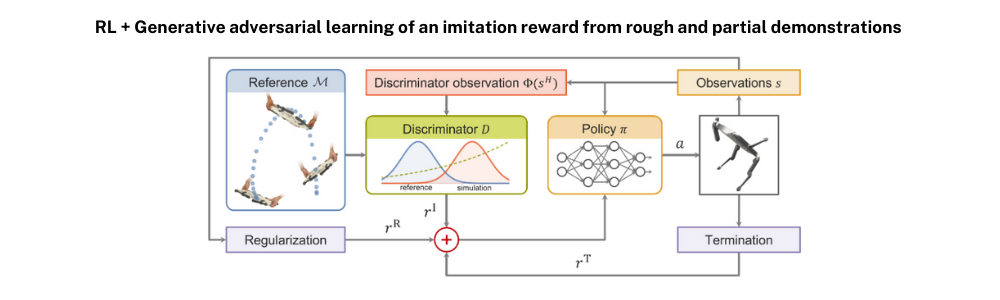
Method
Problem Definition
이전에 AMP 방식에서 모션의 자연스러움을 학습하기 위해 Motion data가 매우 well-defined 되어 있어야 한다고 했습니다. 하지만 이러한 Motion data(혹은 demonstration)을 얻기는 어렵고 특히나 보행과 같이 이미 많이 연구가 되어왔고 동물들의 모습에서도 많이 관찰될 수 있는 task와는 다르게 다이나믹한 backflip하는 모션 task들은 참고할 데이터들도 매우 적고 만들어내기도 어렵습니다. 이런 문제 상황을 본 연구에서는 Rough하고 Partial한 demonstration만 있는 문제로 파악하고 Rough한 모션 데이터라는 것은 실제 로봇이나 동물이 움직여서 얻은 데이터가 아닌 사람이 로봇을 단순히 들고 움직여서 얻은 데이터를 말하며 Partial하다는 것은 로봇의 모션 데이터라고 해서 로봇을 구성하고 있는 모든 joint들의 움직임에 대한 데이터가 아닌 로봇의 몸체에 대한 정보만 있는 모션데이터만 있는 것을 말합니다.

말로만 들으면 잘 와닿지 않기 때문에 위에 사진에서 한 연구자가 backflip하는 demonstration 데이터를 얻기 위해 로봇을 들고 손으로 그냥 한번 뒤집어주는 모습을 보면서 다시한번 설명을 해보겠습니다. 앞서 설명했듯이 로봇이 backflip하는 작동을 해서 데이터를 얻지 않고 사람이 단순히 로봇을 들고 원하는 모션의 demonstration 데이터를 얻습니다. 여기서 Backflip demonstration 데이터는 로봇의 12개의 joint들에 대한 정보는 없이 몸체에 대한 정보(base linear, angular velocity, projected gravity, base height)만을 포함하게 됩니다. 여기서 demonstration 데이터에 대한 놀라운 점은 로봇이 직접 움직여서 얻은 데이터도 아니고 실제 동물의 모션 데이터도 아니기 때문에 물리적으로도 시간적으로도 로봇 플랫폼에서는 사실상 따라하기 어려운 데이터라는 것입니다. 이런 demo 데이터만 있다고 문제상황을 가정한 이유는 backflip과 같이 다이나믹하고 다양한 모션에 대해서는 reference가 될 만한 motion data를 well-defined하기 어렵기 때문입니다.
이쯤에서 다시한번 AMP와 WASABI를 다시 비교해보면, 두가지 방법 모두 expert의 action이 없이도 reference가 될 수 있는 motion data(혹은 demonstration)를 가지고 reward engineering을 잘해서 모션 제어를 할 수 있었다는 점에서 공통점이 있습니다. 하지만 AMP는 well-defined한 모션 데이터가 있어야 가능한 방법론인 반면 WASABI는 로봇의 몸체에 대한 partial한 모션 데이터만 있으면 학습할 수 있었고 AMP는 모션의 주요 reward를 디자인한 것이 아니라 자연스러움을 위한 보조적인 style reward 디자인을 했고 WASABI는 각 모션에 대한 task reward를 디자인 한 것이 큰 차이점이라고 볼 수 있습니다.

Reward Design
Partial하고 Rough한 모션 demo들을 가지고 어떻게 하면 다이나믹한 모션에 대한 reward를 정의할 수 있을까요?
WASABI에서 제안한 전체적인 알고리즘 구조는 아래와 같습니다. r^I, r^R, r^T 라는 각각의 reward가 합쳐지는 것을 볼 수 있는데요 이제부터 각각의 reward가 어떤 의미와 목적을 가지고 있는 것인지 살펴보겠습니다.
Imitation(Task) Reward
우선, task reward는 다이나믹 모션의 demo를 잘 모방(imitate)할 수 있도록 해야할 것 입니다. 그래서 imitation reward 혹은 task reward로 불리며 여기서 WGAN 방법을 이용해서 정의하게 되는 부분입니다. 다시한번 이야기하지만 우리가 backflip을 하는 학습을 하기 위해서 로봇의 몸체를 공중에 올리고 pitch 방향으로의 회전을 360도 해야해!라고 말해주는 imitation reward function(hand-designed)을 사용하는 것이 아니라 demo(true) distribution을 보고 이를 따라가는 generated distribution을 policy가 학습할 수 있도록 하는 것이 이 방법의 핵심입니다.
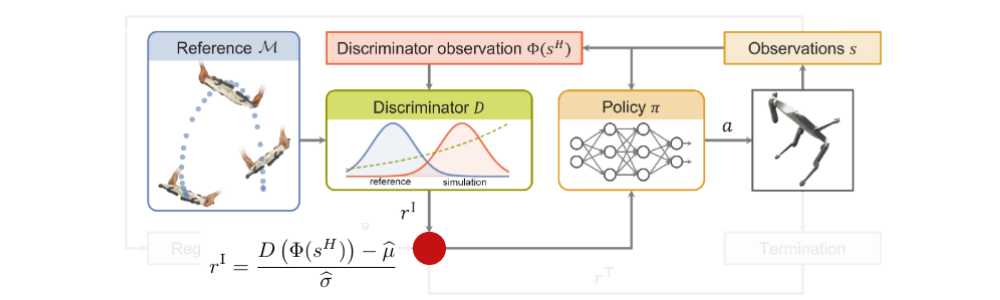
잠깐 앞에서 이야기 했듯이 우리가 사용하는 demo 데이터는 well-defined한 데이터가 아닌 사람이 로봇을 들고 모은 데이터이기 때문에 로봇의 base에 대한 데이터(O)로 한정적입니다. 하지만 policy에서 generated된 observation 데이터(S)는 로봇의 각 joint에 대한 정보 등 더 많은 정보가 있는 vector space이기 때문에 true distribution과 generated distribution을 비교가능한 상태로 만들어주기 위해 Mapping function \phi를 사용하여 맞춰줍니다. 쉽게 생각하자면 정보량이 더 많은 S를 차원이 적은 O로 맞춰주기 위해 joint position, velocity, last action과 같은 부분을 가리고 data distribution을 Discriminator에게 넘겨주는 것으로 볼 수 있습니다.

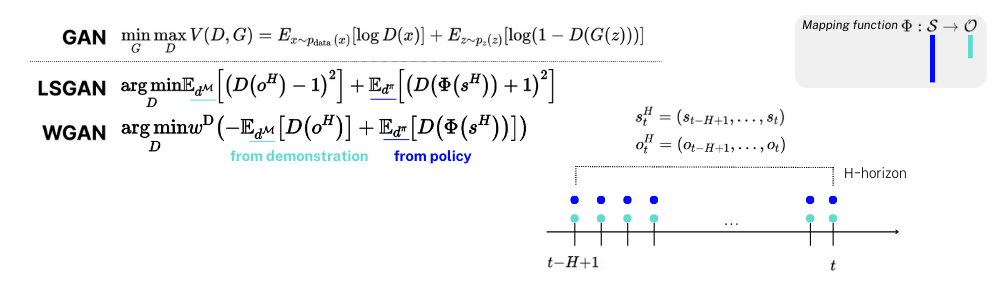
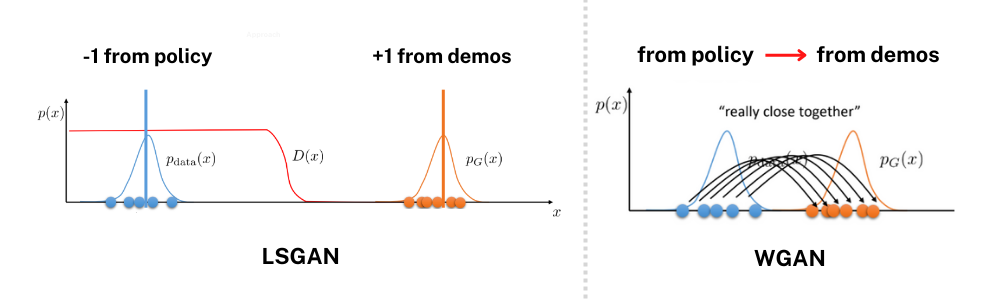
mapping function을 통해 차원을 맞춘 \phi(s) 와 o는 GAN의 objective function에서 Discriminator의 인풋으로 들어가는 seq. of states(observations)이며 아래와 같이 일정 time horizon H동안 모아진 states 벡터들로 볼 수 있습니다. 이러한 seq. of states들을 가지고 Discriminator가 만든 reward distribution을 각각 LSGAN(Least Squares GAN)과 WGAN의 objective function으로 아래와 같이 나타내 볼 수 있습니다. 여기서 LSGAN은 WGAN의 비교군이 되는 또 다른 GAN의 알고리즘이며 LSGAN의 Objective function을 해석해보면, policy에서 나온 state history를 가지고 나온 reward distribution은 -1에 가깝도록 demo를 통해 나온 reward distribution은 +1에 가깝도록 하는 것으로 볼 수 있습니다. 반면, WGAN은 이 두 분포간의 wasserstein distance 줄이도록하는 방향으로 학습합니다. 두 가지 GAN 모두 policy에서 나온 seq. of states로 나온 task reward distribution을 demo의 seq. of states로 나온 task reward distribution을 맞춰가도록 학습하는 것은 공통적입니다.
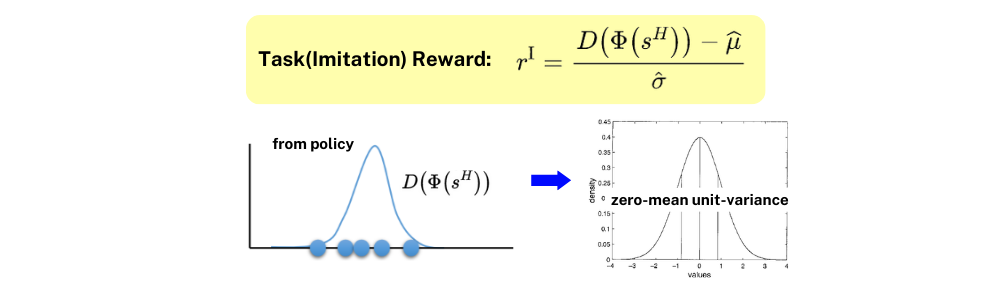
이렇게 Discriminator를 통해 나온 task reward는 바로 사용되는 것이 아니고 zero-mean unit-variance로 만들어주는 과정을 한번 거친 후 비로소 Task(Imitation) Reward로 만들어집니다.
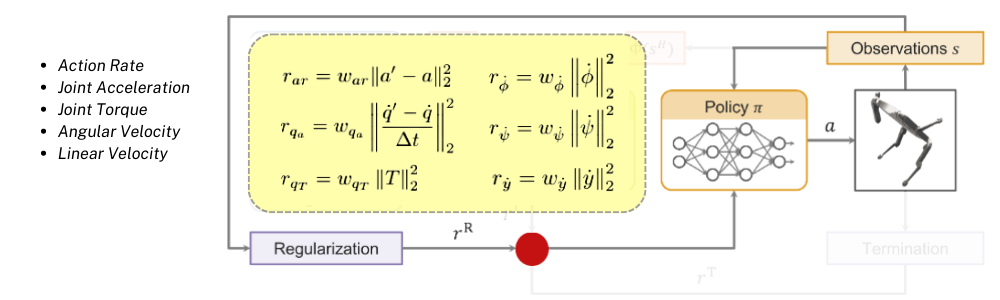
Regularization Reward
이전에 AMP에서의 Style reward의 역할을 WASABI에서는 Regularization Reward가 대신한다고 볼 수 있습니다. 이 reward는 task-dependent하지 않은 task-agnostic한 term들로 이루어져 있어서 backflip 모션을 하든 locomotion 모션을 하든 로봇의 자연스럽고 에너지 효율적인 모션을 위해 부가적으로 더해지는 reward라고 볼 수 있습니다.
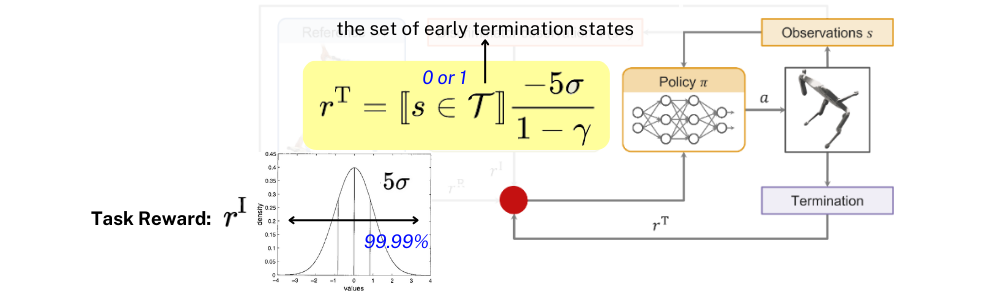
Termination Reward
마지막으로 agent가 모션을 충분히 학습하기도 전에 episode를 더 빨리 끝내는 것이 이득이라 판단하고 학습이 잘 이루어지지 않는 경우를 방지하고자 Termination Reward를 추가해주었습니다. T는 episode를 너무 빨리 끝내버린 경우에 대해서 0 또는 1로 판단하는 인디케이터 역할을 하게 되고, termination에 대한 고려는 Imitation reward의 분포에서 나온 \sigma와 할인율 \gamma를 고려하여 다음과 같이 정해주게 됩니다.
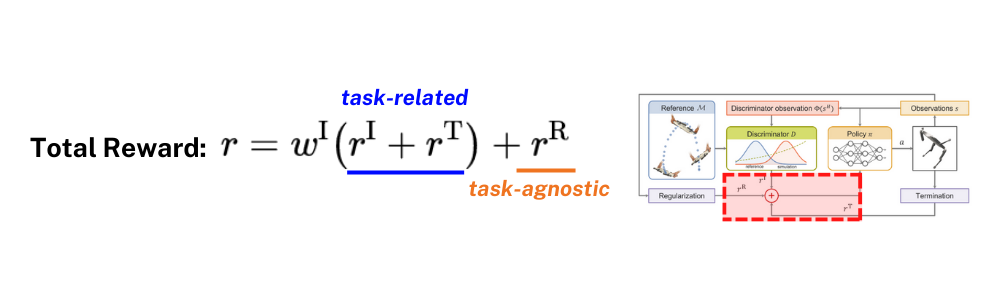
Total Reward
앞서 설명한 Imitation reward r^I, Regularization reward r^R, Termination reward r^T를 모두 합산하여 Total reward가 계산되게 되고 이를 Agent에게 학습 피드백으로 보내주게 됩니다. 이때 r^I와 r^T는 모션 task 마다 다르게 정의될 수 있는 부분이므로 task-related한 부분이라고 볼 수 있으며 r^R는 어떤 모션 task인지 상관없이 항상 동일한 reward term이기 때문에 task-agnostic한 부분이라고 할 수 있습니다. 물론 여기서 해당 연구의 contribution이 두드러진 부분은 Imitation reward r^I이라고 할 수 있습니다.
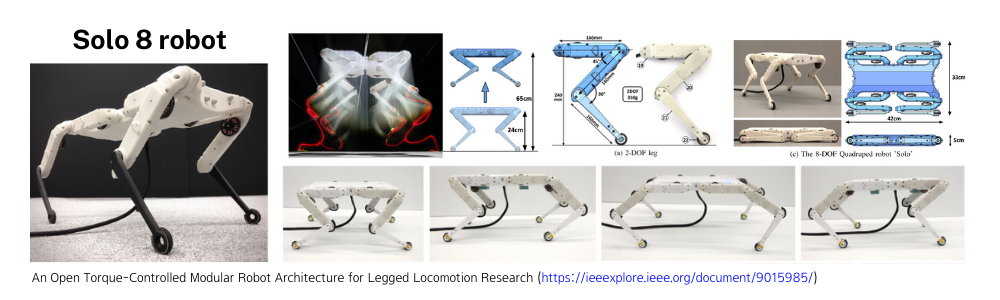
Result
실험에서 사용한 로봇 플랫폼은 Solo 8이라는 4족 보행 로봇입니다. 로봇의 각 다리는 2개의 joint가 있고 상하좌우 대칭적으로 다리의 joint를 꺾을 수 있으며 다른 4족 보행 로봇들에 비해 비교적 소형 플랫폼이고 jumping이 가능하다는 특징을 가진 오픈 소스 플랫폼입니다.
총 4가지 모션 task를 실험했으며 개구리처럼 폴짝폴짝 뛰는 듯한 LEAP, 몸체를 웨이브 타듯 움직이면서 걷는 WAVE, 뒷 다리 2개를 가지고 2족 보행으로 서는 STANDUP, 마지막으로 공중에서 360도 도는 BACKFLIP까지 4개의 모션을 학습했습니다.

Induced Imitation Reward Distributions
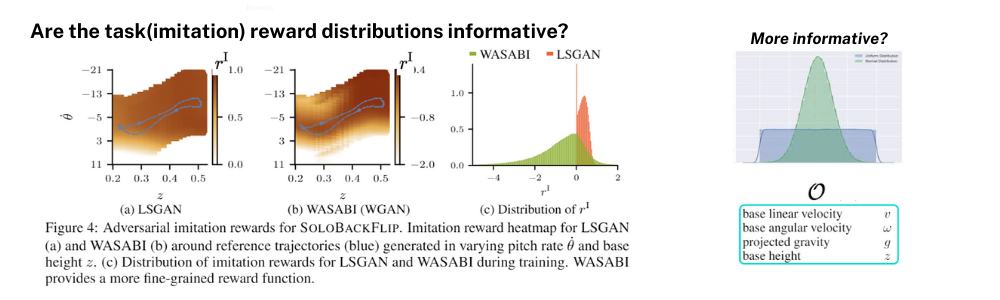
우선 Imitation Reward Distribution이 정말 의미있게 학습을 했는가(Informative한 reward distribution을 만들어 냈는가)를 보기 위해 reward distribution을 시각화해보았습니다. 먼저 Informative한 분포라는 것은 어떤 분포를 말하는가를 짚어볼 필요가 있습니다. 아래 사진의 오른쪽 2개의 분포 그래프에서 평평한 분포(파란색)보다는 뾰족한 분포(초록색)가 여러 x값들에 대해 분별적인 y값(확률)을 가지고 있기 때문에 더 informative하다고 할 수 있습니다.(더 자세한 내용은 정보이론을 살펴보셔도 좋을 것 같습니다.)
왼쪽의 2개의 그래프는 각각 LSGAN과 WGAN(WASABI)를 가지고 학습했을 때, O의 요소들 중 고정된 pitch rate(\dot\theta)와 height(z)를 가지고 Imitation reward 분포를 시각화한 그래프입니다. LSGAN보다 WGAN으로 학습한 분포가 reward range도 더 넓고 더 구분되는 분포를 가지고 있는 것을 볼 수 있습니다. 마지막으로 세번째 그래프는 학습 과정 중에 r^I의 분포를 그린 것으로 LSGAN은 -1과 1, 각각으로 reward targeting을 하게 되는 objective function을 가지고 있었기 때문에 넓고 다양한 reward distribution을 가지지 못한 모습을 볼 수 있고 그에 반해 WGAN은 약 -5~2 정도의 range를 가지는 넓은 reward distribution을 가지고 있는 것을 확인할 수 있었다고 합니다.
Learning to Mimic Rough Demonstrations
그럼 정말로 Demo 모션 데이터들을 얼만큼 잘 따라 학습할 수 있었을까요? 이에 대한 지표는 단순히 reward가 높다고 판단할 수 있는 것이 아니라 모션의 유사성을 판단할 수 있는 다른 metric이 필요합니다.
Dynamic Time Warping
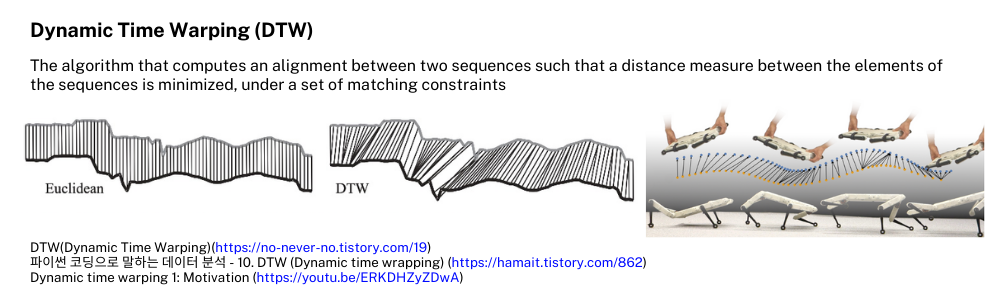
Dynamic Time Warping이란 각 데이터의 시간의 길이도 다르고 데이터 포인트의 수도 다른 2개의 시계열 데이터를 비교할 때 사용하는 방법으로 기존의 Euclidean distance라면 측정할 수 없거나 정확한 비교가 어려운 점을 DTW를 이용하면 시간적인 밀림이나 소실된 데이터 포인트까지 고려하여 시계열 데이터 간의 유사도를 판단할 수 있습니다. 바로 이 방법을 이용해서 사람이 들고 만들었던 demo의 모션 데이터와 실제 학습 후 policy에서 만들어낸 모션 데이터 간의 차이를 측정해보았습니다.
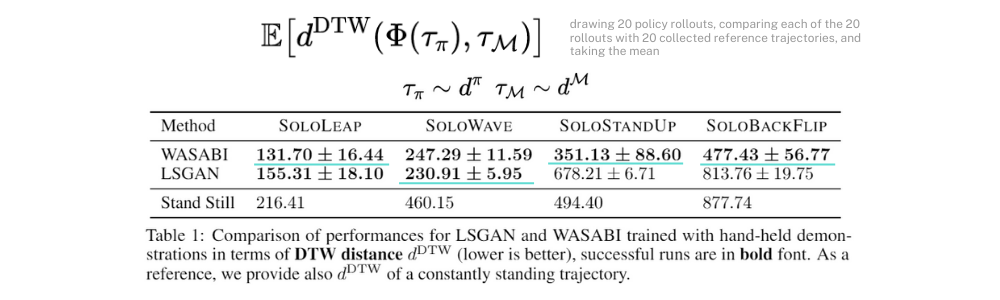
\tau_\pi는 policy에서 만들어진 trajectory를, \tau_M은 demo에서 따온 trajectory를 말하며 아래의 실험 결과표는 각각 WASABI와 LSGAN에서의 4 task에 대한 DTW를 구한 값을 나타내고 있습니다. DTW가 낮을수록 demo 데이터와의 유사성이 높은 것이며 잘 모션을 따라 학습했다고 볼 수 있습니다.(아래 Stand Still은 단순히 가만히 서 있는 모션의 데이터와 demo 데이터 간의 DTW 값을 나타낸 것이며 비교를 위한 DTW의 최대 상한선을 나타낸 것으로 볼 수 있습니다.)
Handcrafted Task Reward
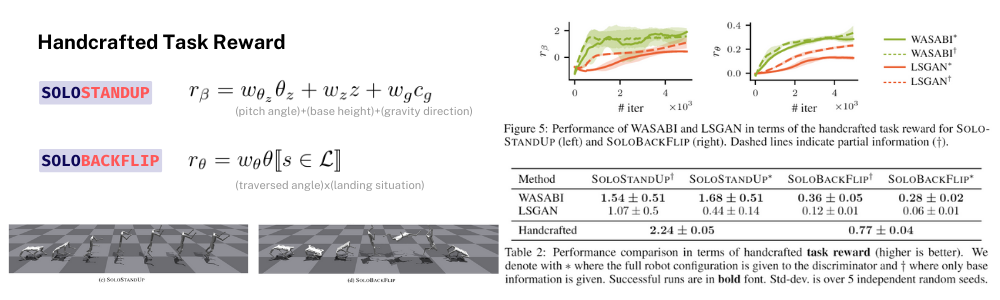
또 다른 지표로는, 해당 모션 task에 대한 Handcrafted task reward로 점수를 매겼을 때 그 점수가 더 높다면 해당 모션을 잘 학습했다고 판단하는 지표가 있습니다. 예를 들어 STANDUP은 몸체의 pitch angle이 90도에 가깝고 몸체의 높이가 높고 몸체의 z축이 중력방향에 수직이 되는 상태라면 해당 모션을 잘 수행하고 있다고 볼 수 있을 것 입니다. 이처럼 우리가 원하는 모션에 대한 Handcrafted task reward를 계산해서 학습 iteration 마다 그려보면 오른쪽 그림과 같이 WASABI를 가지고 학습한 reward 점수가 대체적으로 LSGAN에 비해 높은 것을 알 수 있습니다. 아래 표에서는 학습을 끝낸 후 각 task에 대한 handcrafted reward 점수이며 맨 아래 점수는 최고 상한 기준 점수로 볼 수 있습니다. 표에서 볼드체로 표시된 부분은 roll-out을 했을 때 모션을 눈으로 확인한 결과 잘 수행했다고 판단한 경우를 나타내면 WASABI로 학습한 4가지 task 모두에서 성공적인 학습 결과를 볼 수 있었다는 것을 볼 수 있습니다.
Evaluation on Real Robot
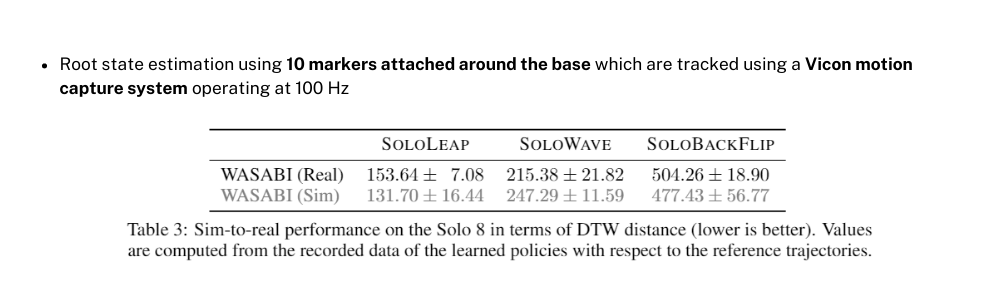
학습이 시뮬레이션에서만 멈춘다면 당연히 의미가 없는 것이므로 실제 로봇을 가지고 해당 policy의 학습 결과를 확인해봐야 합니다. 따라서 WASABI로 학습한 policy를 가지고 실제 로봇으로 작동을 해보고 이때 10개의 marker를 이용해서 모션 데이터를 얻어 DTW를 측정해보았습니다. 그 결과 표에서 볼 수 있듯이 Sim-to-Real의 퍼포먼스 차이가 거의 없었고 실제 로봇에서도 4가지 task 모두 다 잘 수행하는 것을 확인할 수 있었습니다. 이 부분은 실험영상에서 직접 확인할 수 있습니다.
Leap
Wave
Stand up
Backflip
Cross-platform Imitation
사실 강화학습은 특정 로봇 플랫폼에서 학습한 결과를 다른 configuration을 가진 로봇 플랫폼에 바로 적용하기 어렵습니다. 하지만 WASABI 알고리즘은 처음에 Rough하고 Partial한 demo 데이터를 가지고 학습했기 때문에 다른 로봇 플랫폼에 적용해보는 것이 가능했으며 기존에 Solo 8 로봇 플랫폼을 가지고 학습한 policy를 단순히 로봇 플랫폼의 크기 차이만을 고려하여 base height를 0.25m 조금 더 큰값으로 수정해서 Anymal-C 로봇 플랫폼에 적용했을 때 특별한 추가적인 학습 과정없이도 적용할 수 있었다고 합니다. 이때에도 DTW 값을 찍어서 확인한 결과, 낮은 DTW 값과 함께 시뮬레이션으로 roll-out을 했을 때에 로봇이 잘 작동되는 것을 확인할 수 있었다고 합니다.

Conclusion
로봇의 모션제어를 강화학습으로 풀어가려고 할 때 가장 어려운 부분인 task reward를 더 이상 handcrafted 적인 디자인에 의존하지 않고 reward distribution의 관점으로 접근하여 생성 모델 분야의 아이디어인 GAN의 아이디어를 빌려 접근한 것이 정말 신선한 논문이었습니다. Policy를 GAN에서의 Generator로 바라보고 문제를 디자인한 것도 정말 신기했으며 여러가지 GAN 알고리즘 중에서 LSGAN과 WGAN의 차이를 명확히 보여주며 비교를 수치적으로 보여주고 해석한 점도 인상적인 연구였습니다.
Reference
- Original Paper: Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
- Original Project Homepage: CoRL2022-WASABI
- CoRL 2022 Oral Presentation
- Learning Quadrupedal Locomotion over Challenging Terrain
- Joonho Lee: Learning Quadrupedal Locomotion over Challenging Terrain
- Advanced Skills through Multiple Adversarial Motion Priors in Reinforcement Learning
- What Are GANs?
- 1시간만에 GAN(Generative Adversarial Network) 완전 정복하기
- CS 182: Lecture 19: Part 3: GANs
- GANs for Synthetic Data Generation
- An Open Torque-Controlled Modular Robot Architecture for Legged Locomotion Research
- DTW(Dynamic Time Warping)
- 파이썬 코딩으로 말하는 데이터 분석 - 10. DTW (Dynamic time wrapping)
- Dynamic time warping 1: Motivation