📃IPO 리뷰
1 Introduction
오늘은 “IPO: Interior-point Policy Optimization under Constraints”라는 논문에 대해서 리뷰해보려고 합니다. 흔히 강화학습(Reinforcement Learning)을 처음 개념을 공부하고 나면, 강화학습의 문제를 MDP(Markov Decision Process)로 정의한다는 것을 떠올릴 수 있습니다. 이때 강화학습의 핵심인 Reward, 즉 보상을 잘 설정해주어야 Agent가 원하는 방향대로 학습을 하게 됩니다. 보상은 Agent가 해야하는 행동 양식의 (+)가 되는 방향을 나타내는 지 표이며 우리가 원하는 행동을 Encourage(장려)하는 역할을 하게 됩니다.
이번 논문에서는 기본적인 강화학습의 MDP가 아닌 Constraint라는 개념을 넣어서 생각을 해보려고 합니다. Constraint(제약)은 가장 단순하게는 -Reward 라고 생각해볼 수 도 있습니다. 우리가 Agent가 하지 않았으면 하는 행동을 정의함으로써 negative reward를 준다고 볼 수 있는 것이죠. (마치 Gradient Ascent가 Gradient Discent의 반대로 생각해볼 수 있듯이요.) 따라서 Reward와 Constraint는 서로 (+)/(-) 부호적인 성격이 다르지만 Agent에게 학습의 방향을 제시하는 신호라는 측면에서는 공통점을 가지고 있습니다.
조금 더 Constraint에 대해서 자세히 살펴보겠습니다. Constraint는 제약이 발생되는 시점에 따라 2가지로 나누어서 생각해 볼 수 있습니다.

우선, instantaneous constraint는 뜻에서도 알 수 있듯이 일시적으로 constraint를 주는 것을 말합니다. 강화학습에서 Agent가 action을 하게 되는 timestep 마다 제약 상황인지를 판단하여 constraint를 주는 것을 말합니다. 이는 기본적인 강화학습 개념에서 매 timestep마다 reward를 주는 상황과 같습니다. 예를 들어 로봇팔(Manipulator)을 제어하는 상황을 생각해보면, Agent는 적절한 움직임을 위해 로봇팔을 구성하는 모터들을 잘 구동하여 원하는 모션을 만들어야 합니다. 이때 로봇이 움직이는 모든 매 순간마다 각 모터들(joint)이 가동범위에 있어야 하고 과한 토크가 가해지지 않도록 해야 합니다. 이러한 제약 상황들은 매 순간 판단해서 해당 범위들을 넘지 않는 action을 선택하도록 학습해야 하므로 instantaneous constraint의 예로 볼 수 있습니다.
다음으로 cumulative constraint는 Agent가 학습하는 하나의 Episode 내에서 누적해서 나온 값으로 판단하여 제약상황을 판단하는 것을 말합니다. 이때 누적되는 시간은 하나의 Episode가 시작해서 끝날 때까지일 수도 있고 아니면 5 timesteps 동안이라는 특정 timestep 수를 지정하여 계산할 수 있습니다. 로봇팔의 예시로 살펴보자면, 로봇이 펜을 잡는 모션을 할 때까지 100 timestep이 걸렸는데 매 timestep 마다 지연(latency)가 발생하여 이를 제약하고자 합니다. 이러한 상황에서 100 timestep동안의 average latency를 구해서 특정 latency를 넘지 못하도록 constraint를 줄 수 있습니다. 이러한 예시처럼 특정 구간 동안의 값을 통해서 constraint를 주는 것을 cumulative constraint라고 합니다. 이번 IPO 논문에서는 두번째로 소개드린 cumulative constraint에 초점을 맞춰 개발된 알고리즘을 소개하고 있습니다.
1.1 Constrained Markov Decision Process(CMDP)
앞서 설명드린 Constraint가 MDP에 추가된 것을 Constrained Markov Decision Process(CMDP)라고 합니다. CMDP에서는 Reward와 같이 현재 State에서 Action을 취하고 다음 State에 도달했을 때 얻게 되므로 아래 사진에서와 같이 Space가 정의되게 됩니다.
Constraint는 (s_n, a_n, s_{n+1})과 같은 transition tuple로 계산되게 되며, cumulative constraint는 일정 timestep, 즉 transition이 n(서수:t)개 모여서 계산되게 됩니다. 이때 Constraint도 여러 종류가 있을 수 있으므로 constraint의 가짓 수는 m(서수:i)으로 나타낼 수 있습니다. Constraint는 more than better인 reward와 다르게 제약되는 상황을 정의하게 되는 constraint limit이 있게 되고 이를 \epsilon_i로 나타내게 됩니다.

Constraint의 Expectation은 다음과 같이 정의가 되며 2가지의 constraint 계산방법이 있습니다. 첫번째로는 discounted cumulative constraint로 할인율 \gamma를 고려한 constraint들을 하나의 policy가 동작하는 동안 누적합한 값을 말합니다. 두번째로는 일정 timestep T동안 계산한 constraint들의 평균을 말하는 것으로 mean values constraint가 있습니다. 이 2가지 종류의 지표에 대해서 후에 실험에서 다룰 예정이며 CMDP의 목표를 정리해보면, 기존에 J_R만을 Maximization했던 강화학습 문제가 J_{C_i}를 고려해야 한다는 것이 추가 되었다는 것을 알 수 있습니다.

기존의 Constraint가 있는 최적화 문제는 Lagrangian Relaxation Method를 통해서 해결했었습니다. 라그랑지안 승수법이라고도 불리는 해당 방법은 기존의 최적화 식 f(x)에 constraint g_i(x)가 추가된 최적화 문제를 Lagrange Multipilers를 곱하여 기존 최적화 함수 목적식에 더하여서 제약 조건을 푸는 방법입니다.

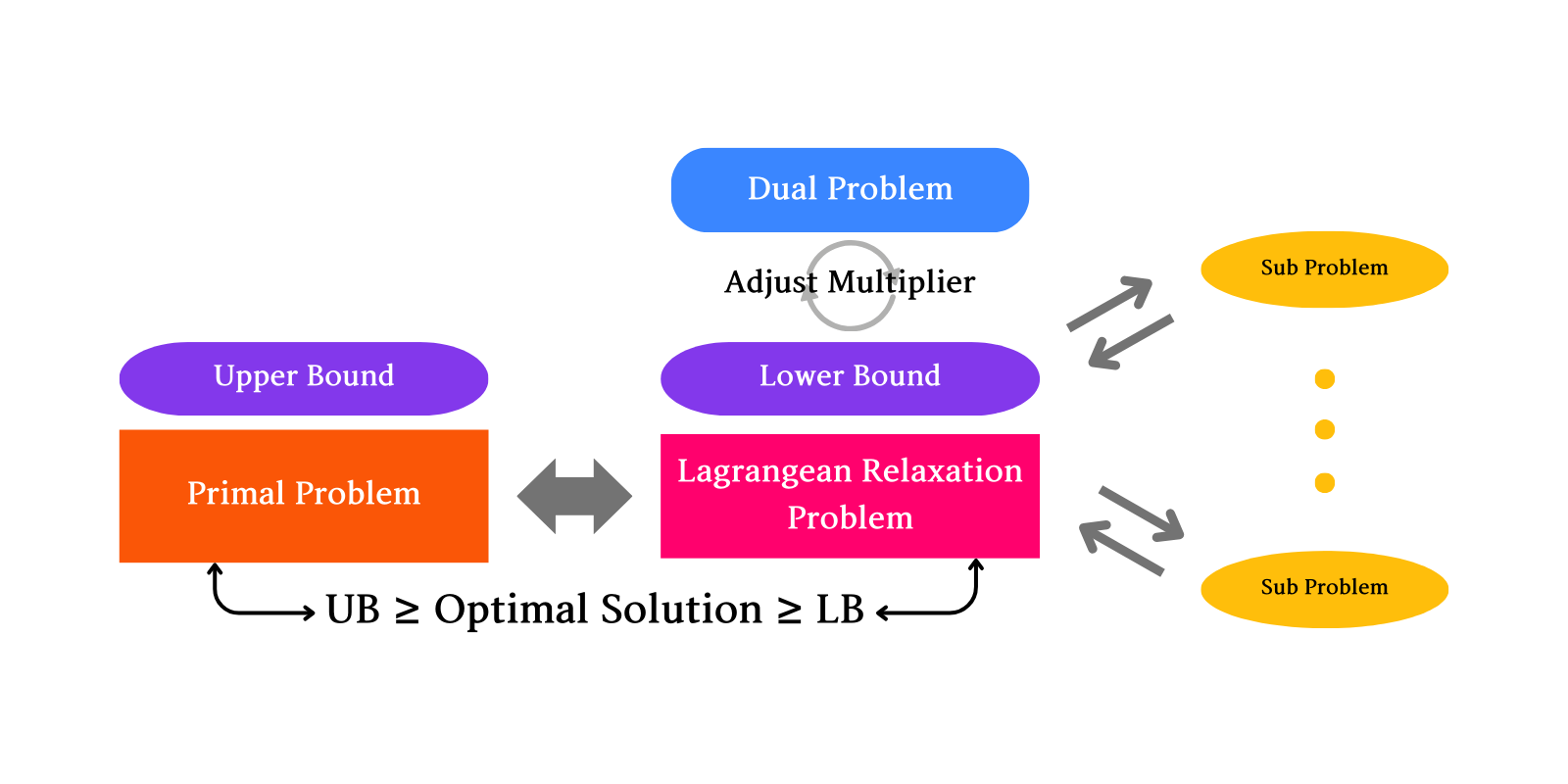
라그랑지안 승수법은 가장 심플하게 제약 조건들을 메인 최적화식에 녹여내어 풀어내는 방식으로, CMDP 문제들도 해당 방법을 통해 해결하는 것이 통상적인 방법이었지만 라그랑지안 승수법은 정책이 수렴할 때 제약 조건이 만족되지만, 이 접근법은 Lagrange multiplier의 초기값과 학습률에 민감하고 학습 과정에서 얻은 정책이 항상 제약 조건을 일관되게 만족시키지는 않는다는 한계점이 있습니다.
1.2 Policy Gradient Methods
앞 부분에서 살펴본 것과 같이 CMDP Goal은 Reward 값을 최대화하면서 제약식을 만족하는 최적의 policy를 찾는 것이라고 할 수 있습니다.

먼저 제약조건을 잠시 뒤로 두고, 본래 기본적인 강화학습의 목적식인 Reward Maximization은 어떻게 할까요? Policy Gradient는 강화학습의 한 계열로 최적의 policy, 즉 가장 Reward를 많이 받을 수 있는 policy를 찾기 위해 아래와 같은 목적식의 gradient를 계산하게 됩니다. 이때 최적의 policy를 찾기 위해서 \theta는 위에서 구한 gradient 값을 기반으로 아래와 같이 업데이트하게 됩니다.

Trust Region Policy Optimization(TRPO)라는 알고리즘이 PG계열에서 대표적으로 사용되는 알고리즘이며, 최적이 policy를 찾기 위해 surrogate function을 이용하고 policy가 업데이트 되는 step size를 제한하기 위해 KL divergence를 사용합니다. TRPO의 최적화 식은 아래와 같이 표현할 수 있습니다.
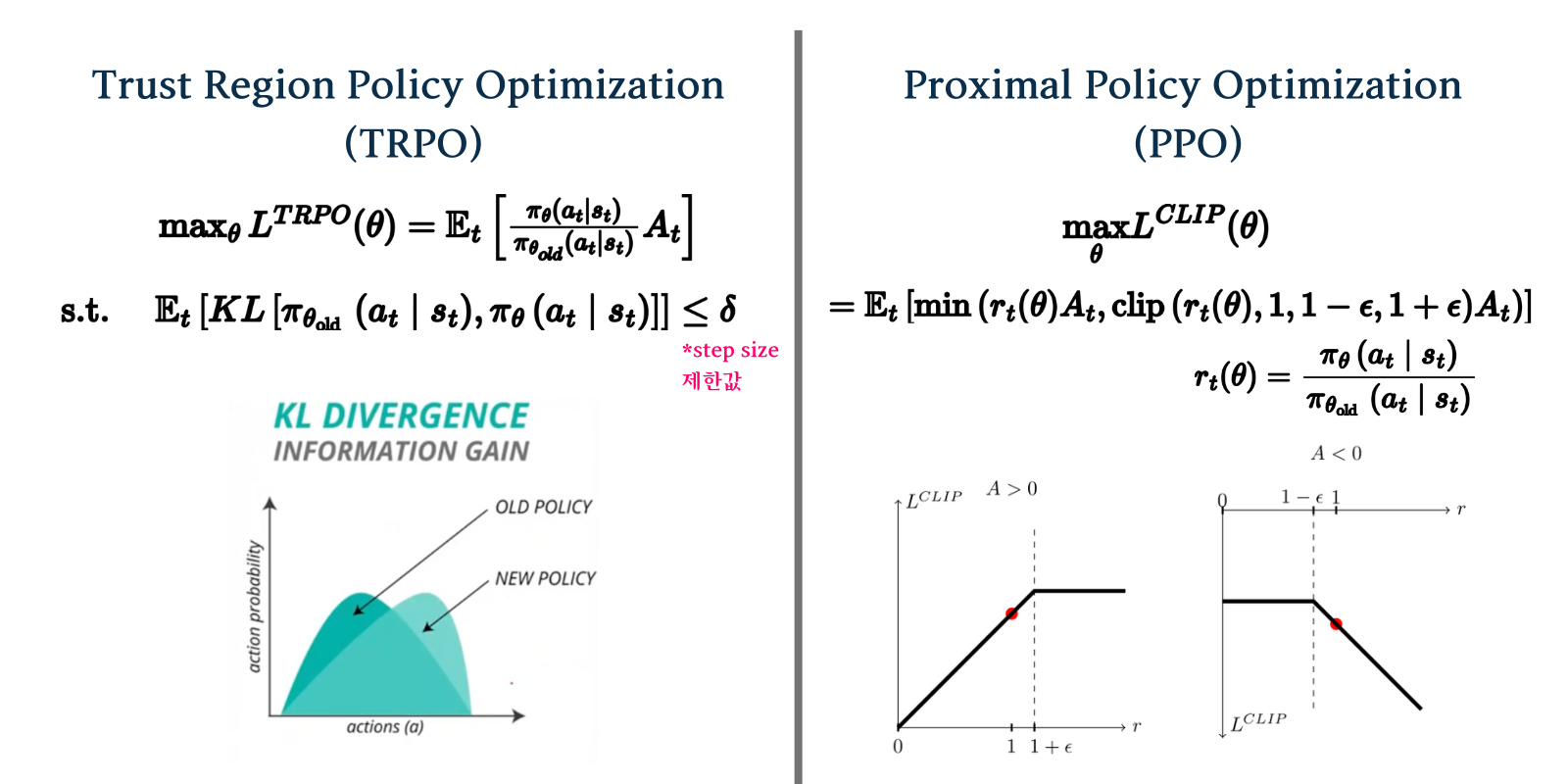
하지만 TRPO는 conjugate gradient optimization으로 풀리는 2차 미분 최적화를 사용하기 때문에 계산 cost가 큽니다. 따라서 TRPO를 실용적으로 사용할 수 있게한 Proximal Policy Optimization (PPO) 알고리즘이 제안되었습니다. PPO의 최적화 식은 TRPO에서 문제였던 2차미분을 1차 미분 surrogate function으로 대체할 수 있었으며 계산복잡성을 줄일 수 있었습니다.
IPO는 이러한 흐름대로 발전해온 PPO 알고리즘의 최적화 식에서 제약식을 추가하면서 발전하게 됩니다.
2 Method
2.1 Interior-point Policy Optimization
IPO이전에 CPO(Constrained policy optimization)라는 알고리즘이 제안되었었습니다. IPO는 CPO의 단점을 보완하여 제안된 알고리즘으로 볼 수 있으며 아래와 같이 2개 알고리즘을 비교해볼 수 있습니다.
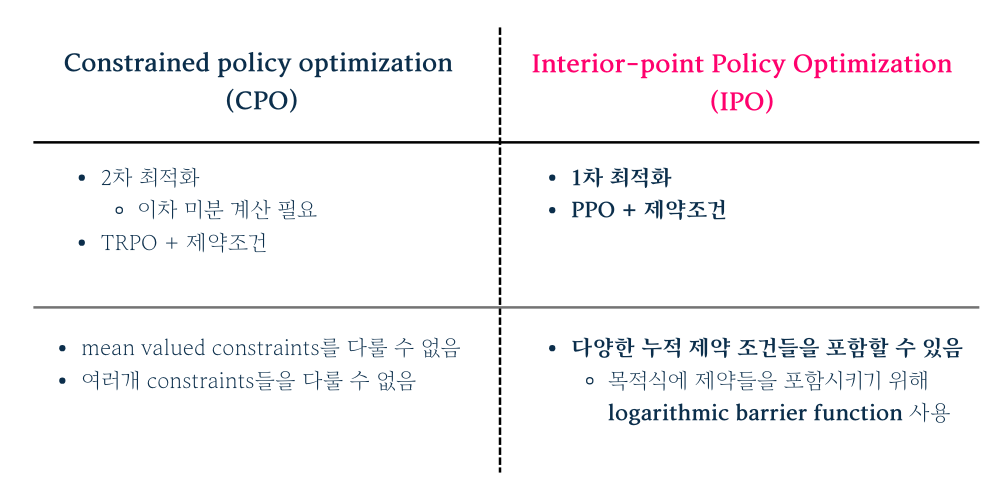
우선, CPO는 TRPO에서 제약조건을 추가한 목적식을 사용하여 TRPO의 문제이기도 했던 2차 미분 계산이 필요하다는 특성이 있습니다. 따라서 제약조건들을 추가하거나 mean valued constraint와 같은 누적 제약식을 계산하기 까다롭거나 할 수 없다는 문제점을 가지고 있었습니다. 이에 반해, IPO는 PPO에 제약조건을 추가한 목적식을 기반으로 하여 1차 미분만을 하면 된다는 장점을 가지고 있으며, 다양한 제약조건들을 이후에 설명할 핵심 아이디어인 logarithmic barrier function을 이용하여 쉽게 추가할 수 있습니다.
2.2 Logarithmic Barrier Function
우선 IPO의 문제 정의는 아래와 같이 PPO의 목적식에다가 Constraint를 추가한 것으로 정의할 수 있습니다.

Constraint는 Limit을 고려하여 부등호로 나타낼 수 있으며 이는 Indicatior Function에 넣었을때, Constraint를 넘었을 경우 -\infin로 나타내고 Constraint를 만족했을 경우 0으로 나타낼 수 있습니다. 하지만 Indicator Function은 불연속적이며 미분 불가능하기 때문에 gradient를 구할 수 없어서 Logarithmic Barrier Function을 통해 근사하게 됩니다.
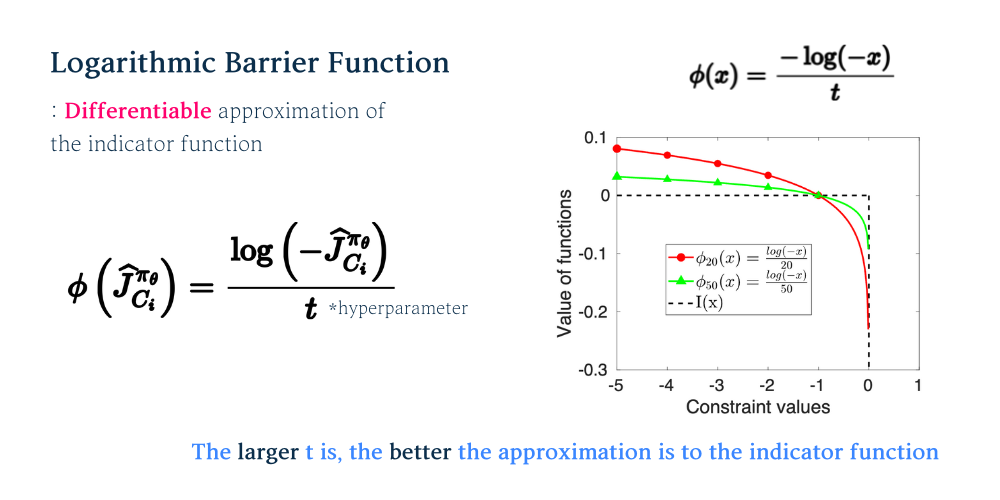
Logarithmic Barrier Function(\phi)은 그래프에서와 같이 하이퍼 파라미터인 t의 값이 클수록 Indicator Function과 유사하다는 것을 알 수 있습니다. 그래프에서 초록색 t=50일 때의 그래프가 점선의 Indicator Function과 유사한 것 처럼요. 또한 \phi는 이분이 가능하기 때문에 gradient를 통해 최적화할 수 있습니다.

따라서 IPO의 최적화식은 PPO의 목적식 (L^{C L I P}(\theta))에 Logarithmic Barrier Function(\phi)을 이용하여 제약조건을 합치게 된(\sum_{i=1}^m \phi\left(\widehat{J}_{C_i}^{\pi_i}\right)) 모습이 됩니다.
2.3 Performance Guarantee Bound
그렇다면 IPO의 성능 보장을 이론적으로 검증해보겠습니다.

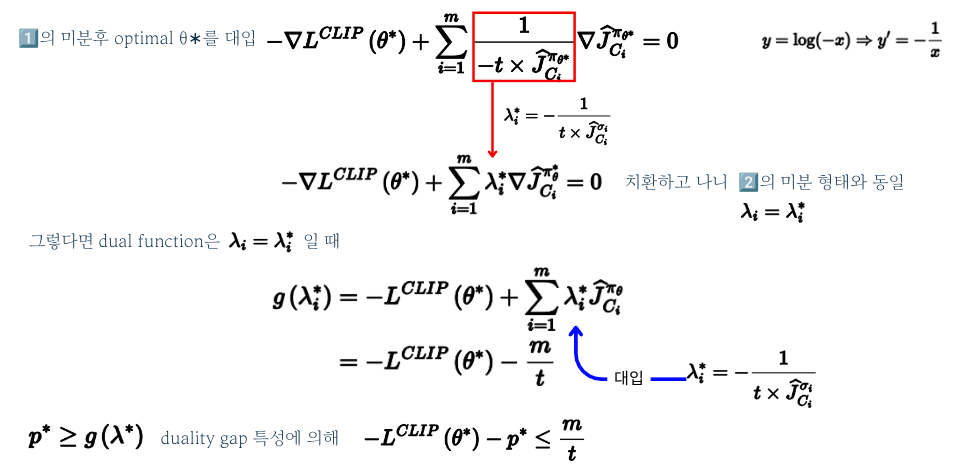
이러한 수식적인 검증 과정을 거쳐 IPO의 목적식은 일정 한계 내에 있다는 것(Bounded) 되어있다는 결론을 내릴 수 있습니다.

수식적으로 Performance Guarantee Bound를 확인하여 t(logarithmic barrier function의 하이퍼파라미터)가 클수록 Indicator function에 대한 더 좋은 근사값을 제공하게 되고 더 높은 reward와 cost를 얻을 수 있다는 것을 확인할 수 있습니다. 하지만 t가 클수록 최적화 식이 수렴하는 속도는 느려진다는 단점이 있습니다. 또한 수식으로 확인한 단조성(monotonicity)을 이용하여, 수렴 속도와 최적화 성능 사이의 균형을 맞출 수 있는 적절한 t 값을 찾기 위해 이진 탐색 알고리즘(binary search)을 사용할 수 있다는 사실도 확인할 수 있습니다.
3 Experiment
실험을 통해 확인할 수 있는 IPO(Interior Point Optimization)의 주요 장점은 다음과 같습니다:
- 할인 누적 제약(discounted cumulative constraints)과 평균 값 제약(mean valued constraints)을 포함한 보다 일반적인 형태의 누적 제약을 처리할 수 있습니다.
- 하이퍼파라미터 설정이 간단하고 조정이 용이합니다.
- 복수의 제약 조건이 있는 최적화 문제로 쉽게 확장할 수 있습니다.
- 확률적인(stochastic) 환경에서도 높은 안정성과 견고함을 보여줍니다.
3.1 Discounted Cumulative Constraints
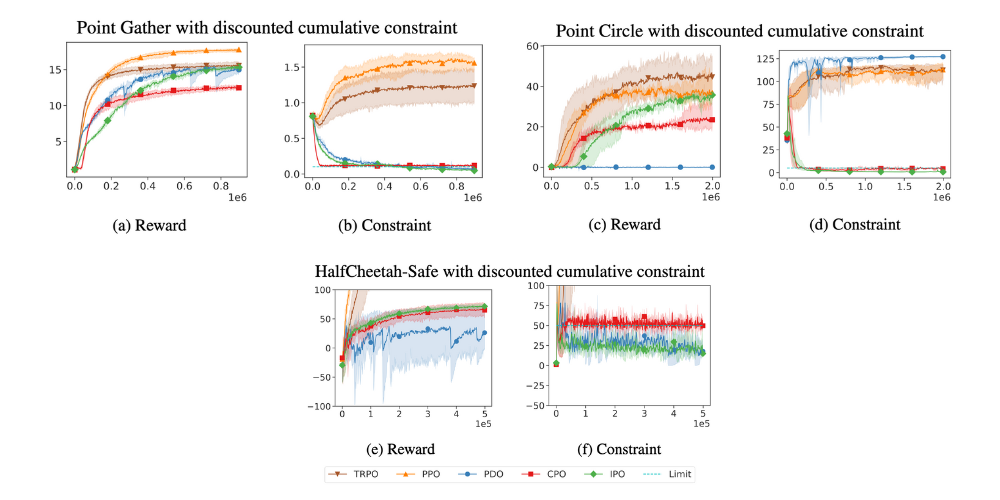
- IPO VS. CPO
- IPO
- 최고 성능을 보여줍니다.
- 제약 조건이 충족된 이후에도 더 나은 정책을 찾기 위해 탐색을 계속합니다.
- 이로 인해 더 높은 보상과 더 낮은 비용으로 수렴합니다.
- 수렴 속도는 느리지만, 최종 성능은 CPO보다 우수합니다.
- CPO
- 수렴 속도가 IPO보다 빠릅니다.
- 제약 조건이 충족되면 개선 작업을 중단합니다.
- 제약 조건을 빠르게 만족시키지만, 그 이후에는 성능 개선이 멈춥니다.
- 따라서 보상이나 비용 측면에서 IPO만큼의 최적화를 이루지 못할 가능성이 있습니다.
- IPO
| 특징 | IPO | CPO |
|---|---|---|
| 수렴 속도 | 느림 | 빠름 |
| 제약 충족 후 개선 | 계속 탐색 (더 나은 정책을 찾음) | 개선 중단 (제약 조건 충족 시) |
| 최종 성능 | 더 높은 보상과 낮은 비용 | 제약 조건 만족 후 개선 없음 |
- IPO VS. PDO
- IPO
- 최고 성능을 보여줍니다.
- 제약 조건이 충족된 이후에도 더 나은 정책을 찾기 위해 탐색을 계속합니다.
- 안정적인 학습 과정을 가지며, 성능의 변동이 적습니다.
- 초기화나 학습률에 덜 민감합니다.
- PDO
- IPO만큼 좋은 정책으로 수렴 가능하지만, 훈련 중 성능의 분산(variance)이 높습니다.
- 제약 조건 값을 한계 이하로 낮추는 정책을 찾을 수 있으나, 그 결과 보상(reward)이 가장 낮아질 수 있습니다.
- Lagrange multiplier의 초기값과 학습률(learning rate)에 민감하게 반응합니다.
- 초기 설정이 잘못되면, 학습 과정이 불안정해질 수 있습니다.
- IPO
| 특징 | IPO | PDO |
|---|---|---|
| 수렴 성능 | 최고 성능에 수렴 | IPO 수준으로 수렴 가능 |
| 훈련 중 성능 변동 | 낮음 (안정적) | 높음 (변동이 큼) |
| 제약 조건 만족도 | 제약 조건을 충족하며 탐색 지속 | 제약 조건 값을 한계 이하로 낮춤 |
| 보상 (Reward) | 높은 보상 | 가장 낮은 보상 가능성 |
| 초기화/학습률 민감도 | 낮음 | 높음 |
- (optional)CPO vs. PPO / TRPO
| 특징 | CPO | PPO | TRPO |
|---|---|---|---|
| 제약 조건 처리 여부 | 제약 조건을 고려함 | 제약 조건 없음 | 제약 조건 없음 |
| 보상 (Reward) | 높음 (제약 조건 내에서) | 가장 높음 (제약 조건 위반 가능성 있음) | 높음 (제약 조건을 간접적으로 완화) |
| 제약 조건 위반 가능성 | 낮음 | 높음 | 중간 (신뢰 영역으로 일부 완화) |
| 학습 안정성 | 높음 | 높음 | 매우 높음 |
| 계산 복잡도 | 중간 | 낮음 | 높음 |
3.2 Mean Valued Constraints
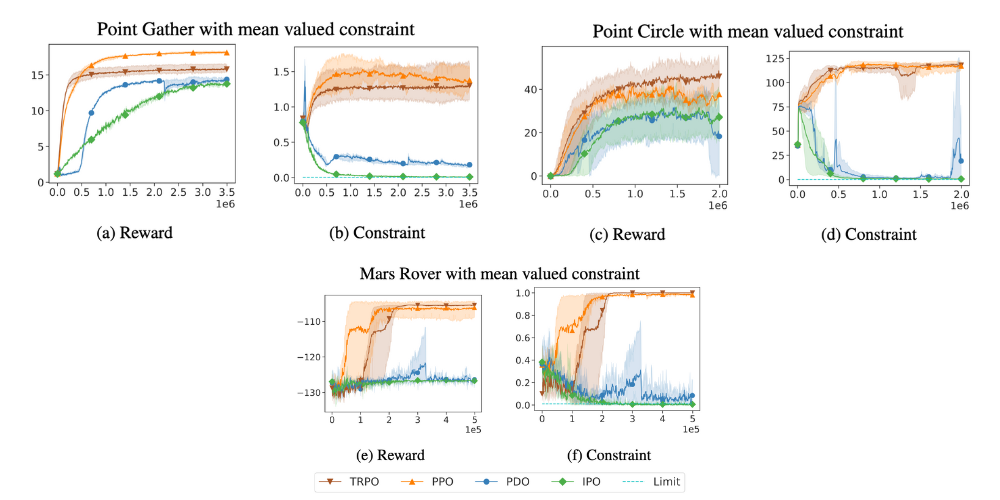
- IPO VS. PDO
- IPO
- 일관된 수렴: 모든 작업(task)에서 할인 누적 보상(discounted cumulative reward)이 높은 정책으로 안정적으로 수렴합니다.
- 제약 조건 만족: 모든 작업에서 평균 값 제약(mean valued constraints)을 지속적으로 만족시킵니다.
- 안정적인 학습: 훈련 중 성능의 변동이 적으며, 낮은 분산(variance)을 보입니다.
- PDO
- 제약 조건 위반 가능성: 간혹 제약 조건을 위반하는 정책으로 수렴할 수 있습니다. (참조: Figure 3b)
- 훈련 중 높은 분산: 훈련 과정에서 성능의 변동이 크며, 높은 분산을 보입니다. (참조: Figure 3d 및 Figure 3f)
- 높은 보상 가능성: 때때로 높은 보상을 달성할 수 있지만, 제약 조건을 지키지 못할 위험이 있습니다.
- IPO
| 특징 | IPO | PDO |
|---|---|---|
| 할인 누적 보상 | 안정적으로 높은 보상에 수렴 | 높은 보상 가능성이 있으나 불안정 |
| 제약 조건 만족도 | 항상 제약 조건을 만족함 | 간혹 제약 조건을 위반 |
| 훈련 중 성능 변동 (분산) | 낮음 (안정적) | 높음 (변동이 큼) |
| 안정성 | 매우 안정적 | 초기화와 학습률에 민감 |
3.3 Constraint Effects
Point Gather 환경에서 제약 조건을 완화하여 임계값을 1로 설정한 경우, 각 에이전트는 평균적으로 최대 1개의 폭탄(bomb)을 수집할 수 있습니다. Constraint 값을 내려서 완화하게 되면 제약 조건이 매우 느슨해져서, 제약 조건이 있는 최적화 문제의 성능이 제약 조건이 없는 경우와 동일한 수준으로 나타납니다.
- CPO
- CPO는 여전히 비용을 증가시켜 제약 임계값(1)에 도달하려고 합니다.
- 이는 때때로 랜덤 초기화된 정책보다도 성능이 떨어질 수 있습니다.
- CPO는 항상 비용을 제약 임계값(1)까지 밀어 올리려는 경향을 보입니다.
- IPO
- IPO는 제약 조건이 충족된 이후에도 비용을 계속 줄여나갑니다.
- 이로 인해 더 낮은 비용을 달성하며, 더 나은 최종 성능을 보여줍니다.
| 특징 | CPO | IPO |
|---|---|---|
| 제약 조건 만족도 | 제약 임계값(1)까지 비용 증가 | 제약 충족 후에도 비용 감소 지속 |
| 최종 비용 수준 | 약 1 | 약 0.25 |
| 성능 | 제약 충족을 우선시하며 성능 저하 가능 | 제약을 충족하면서도 더 나은 성능 |
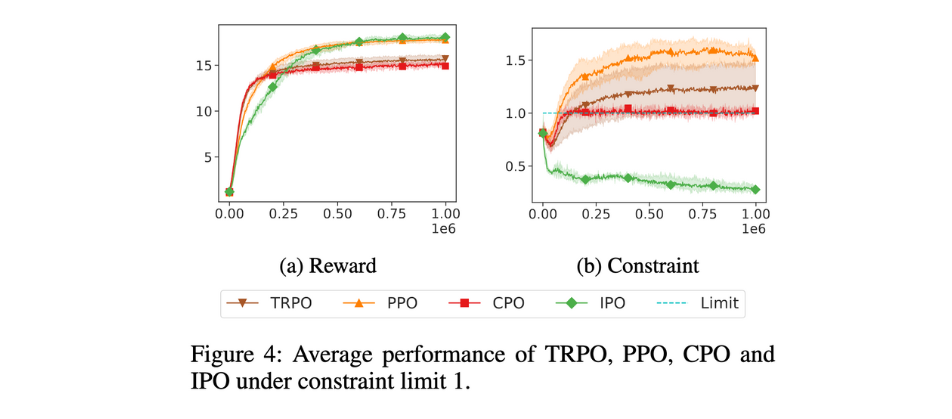
따라서 실험을 통해 다음과 같은 결론을 내릴 수 있습니다.
- CPO는 제약을 맞추기 위해 비용을 적극적으로 증가시키지만, 그 결과 성능이 떨어질 가능성이 있습니다.
- IPO는 제약을 만족한 이후에도 비용을 줄이며, 더 높은 성능을 달성할 수 있습니다.
3.4 Hyperparameter Tuning
- IPO vs. PDO
- IPO
- 하이퍼파라미터 t의 튜닝이 용이합니다.
- 보상(reward)과 비용(cost)은 하이퍼파라미터 t와 양의 상관 관계를 가집니다.
- t 값이 커질수록, 보상과 비용이 동시에 증가합니다.
- 이진 탐색(binary search)이 가능:
- t 값을 조정하며 성능을 확인할 수 있으며, 이진 탐색을 통해 빠르게 최적의 값을 찾을 수 있습니다.
- PDO
- 초기 Lagrange multiplier (\lambda)와 학습률(learning rate)의 설정이 까다롭습니다.
- 초기 \lambda 값이 0.01에서 0.1 사이일 때 매우 민감하게 반응합니다.
- 잘못된 초기화는 학습 과정의 불안정을 초래할 수 있습니다.
- 학습률(learning rate)의 변화에도 민감합니다.
- 학습률이 0.01에서 0.001로 작아지면, 정책의 수렴 속도가 느려집니다.
- 하이퍼파라미터 설정에 많은 시간과 노력이 필요합니다.
- IPO
| 특징 | IPO | PDO |
|---|---|---|
| 하이퍼파라미터 튜닝 용이성 | 쉬움 | 어렵고 복잡함 |
| 보상과 비용의 관계 | t와 양의 상관 관계 | 초기 \lambda와 학습률에 민감 |
| 초기 설정 민감도 | 낮음 | 높음 |
| 튜닝 방법 | 이진 탐색 가능 | 초기화와 학습률 설정에 많은 노력 필요 |
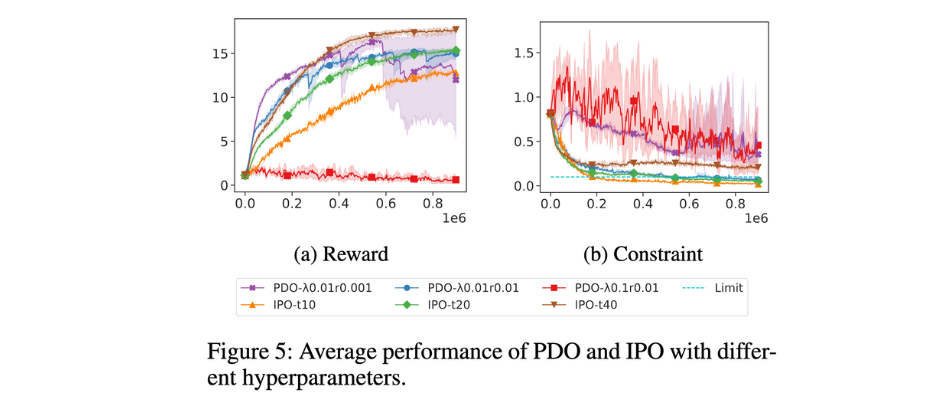
따라서 실험을 통해 다음과 같은 결론을 내릴 수 있습니다.
- IPO는 하이퍼파라미터 t의 튜닝이 쉽고, 보상과 비용이 t 값에 따라 예측 가능하게 변화하기 때문에 안정적인 최적화가 가능합니다.
- PDO는 초기화와 학습률에 민감하여 튜닝이 까다롭고 학습 과정이 불안정할 수 있습니다. 특히 초기 \lambda와 학습률 설정이 중요한 역할을 합니다.
3.5 Multiple Constraints
IPO (Interior Point Optimization)는 제약 조건을 다룰 때 유연하고 확장 가능한 방식으로 설계되어 있습니다. 특히, logarithmic barrier function을 사용하여 제약 조건을 쉽게 추가할 수 있습니다. IPO에서는 새로운 제약 조건이 필요할 때, 기존 최적화 함수에 로그 배리어 항을 추가하기만 하면 됩니다. 이 방식은 CPO보다 간단하게 제약 조건을 추가할 수 있는 이점이 있습니다. IPO는 logarithmic barrier function을 사용하여 제약 조건을 쉽게 추가할 수 있어, 확장성과 유연성 측면에서 CPO보다 유리합니다.
- CPO와의 비교
- CPO (Constrained Policy Optimization)는 제약 조건을 직접적으로 다루지만, 새로운 제약 조건이 추가될 때마다 문제의 복잡도가 증가하고, 튜닝이 어려워질 수 있습니다.
- 반면, IPO는 logarithmic barrier function을 사용하기 때문에, 제약 조건을 쉽게 확장할 수 있으며 구현과 튜닝이 더 간단합니다.
- Point Gather 실험에서의 제약 조건 확장
- Point Gather 환경에서는 에이전트가 보상을 얻는 과정에서 다양한 제약 조건을 추가할 수 있습니다.
- 실험에서 다양한 제약 조건을 추가하기 위해, 새로운 타입의 ball (제약 조건에 해당하는 오브젝트)을 도입할 수 있습니다.
- 예를 들어, 기존의 bomb 외에 새로운 제약 조건을 나타내는 여러 종류의 ball을 추가하여, 에이전트가 이들을 피하면서도 최대한 많은 보상을 얻는 정책을 학습할 수 있습니다.
- 이를 통해 다중 제약 조건 환경에서도 IPO의 성능을 평가할 수 있습니다.
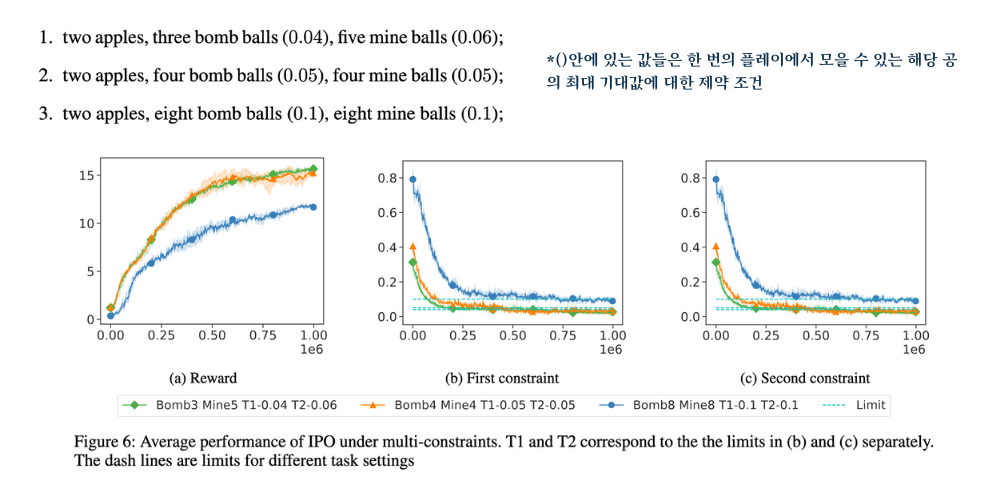
| 특징 | IPO | CPO |
|---|---|---|
| 제약 조건 추가 용이성 | 로그 배리어 항 추가만으로 가능 | 복잡한 추가 작업과 튜닝 필요 |
| 확장성 | 간단하게 여러 제약 조건 확장 가능 | 제약 조건 추가 시 복잡도 증가 |
| Point Gather 실험 적용 | 다양한 제약 조건 ball 추가 가능 | 제약 조건 추가 시 성능 저하 위험 |
3.6 Stochastic Environment Effects
실세계 환경에서의 불확실성 및 랜덤 노이즈 추가 실험 실제 환경에서는 항상 불확실성(uncertainty)이 존재합니다. 에이전트의 행동 결과는 종종 랜덤 노이즈(random noise)에 의해 영향을 받습니다. 예를 들어, 바람, 센서 오류, 마찰 등의 예기치 못한 요인들이 시스템에 영향을 줄 수 있습니다. 해당 실험에서 행동(action)은 속도(velocity)와 진행 방향(heading)의 벡터로 정의되며, 값의 범위는 -1에서 1 사이입니다. (-1, 1) 범위의 벡터는 에이전트가 움직일 방향과 속도를 나타냅니다.
실험에서는 평균 0의 랜덤 노이즈를 행동(action)에 추가하여 환경의 불확실성을 모사했습니다.
- 노이즈의 분산(variance)은 세 가지 값으로 설정되었습니다:
- \sigma^2 = 0.2
- \sigma^2 = 0.5
- \sigma^2 = 1.0
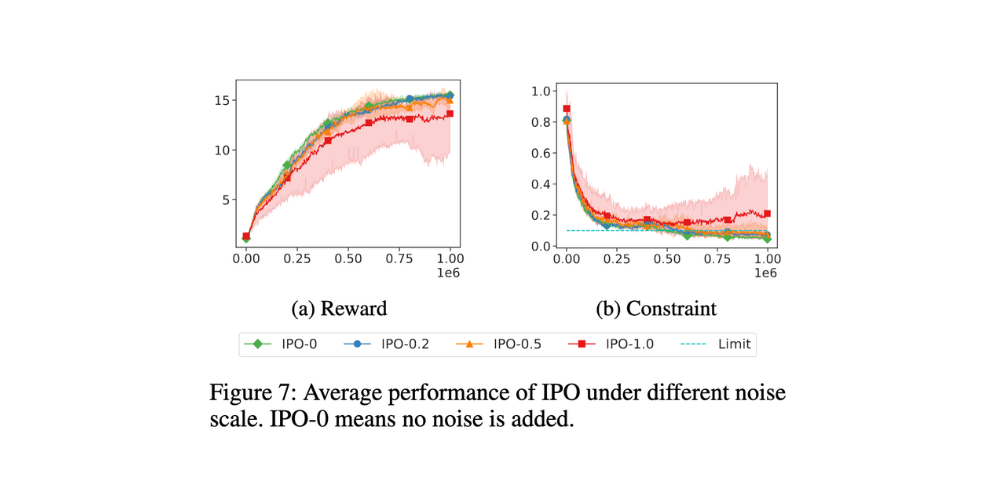
- \sigma^2 = 0.5일 때도 학습이 성공적으로 수렴하는 것을 확인할 수 있었습니다.
- 이는 에이전트가 일정 수준의 환경 불확실성에서도 안정적으로 정책을 학습할 수 있음을 보여줍니다.
- \sigma^2 = 1.0의 경우, 노이즈가 커져 학습이 불안정해질 가능성이 있으며, 이는 추가 실험에서 확인할 필요가 있습니다.
- 실제 환경의 불확실성을 반영하기 위해 랜덤 노이즈를 추가하는 것은 강화 학습의 강건성(robustness) 평가에 중요한 역할을 합니다.
- 적절한 수준의 노이즈(\sigma^2 = 0.5)에서는 학습이 안정적으로 진행되었으며, 에이전트가 다양한 환경 변동에도 잘 적응할 수 있음을 확인했습니다.
4 Conclusion
이번 포스팅에서는 제약조건을 포함한 MDP의 문제는 어떻게 정의할 수 있고 어떤 방식으로 최적화식을 디자인하여 풀 수 있는지 살펴보며 IPO 알고리즘에 대해 알아보았습니다. 강화학습에서 학습의 방향성을 Reward로만 디자인 하게될 경우의 문제들을 Constraint로 바꾸어서 디자인하게 된다면 많은 이점이 있을 수 있고, CMDP를 다룬 다른 알고리즘들에 비해 심플하면서도 사용하기 편한 아이디어라는 생각이 들었습니다.