📃Dex Imitation Learning 리뷰
리뷰 논문은 꼭 한번 읽어보는 것을 추천합니다.
- ✨ 고차원적 복잡성과 역학으로 인해 전통적인 방법과 강화 학습은 로봇의 능숙한 조작(dexterous manipulation)에 어려움을 겪습니다.
- 🤖 모방 학습(Imitation Learning, IL)은 전문가 시연을 통해 로봇이 복잡한 조작 기술을 직접 학습할 수 있도록 하는 유망한 대안입니다.
- 📘 본 조사는 모방 학습 기반 능숙한 조작의 최신 기술, 도전 과제 및 미래 연구 방향에 대한 포괄적인 개요를 제공합니다.
1 Dexterous Manipulation through Imitation Learning
본 논문은 Imitation Learning (IL) 기반의 Dexterous Manipulation(DM)에 대한 포괄적인 서베이 논문입니다. DM은 로봇 손 또는 다지(multi-fingered) End-effector가 정밀하게 조율된 손가락 움직임과 적응적인 힘 조절을 통해 객체를 능숙하게 제어, 재배향, 조작하는 능력을 의미하며, 인간 손의 dexterity와 유사한 복잡한 상호작용을 가능하게 합니다. 로봇 공학 및 기계 학습의 발전과 함께 복잡하고 비정형적인 환경에서 작동하는 시스템에 대한 수요가 증가하고 있습니다.

다양한 로봇 손과 그리퍼를 활용한 능숙한 조작(dexterous manipulation) 작업의 예시
기존의 모델 기반(model-based) 접근 방식은 DM의 높은 차원성(high dimensionality)과 복잡한 접촉 동역학(contact dynamics)으로 인해 작업 및 객체 변화에 대한 일반화(generalize)에 어려움을 겪습니다. Reinforcement Learning (RL)과 같은 모델 프리(model-free) 방식은 가능성을 보여주지만, 안정성과 효과성을 위해 광범위한 훈련, 대규모 상호작용 데이터, 신중하게 설계된 보상(reward)이 필요합니다. IL은 전문가 데모(expert demonstrations)로부터 DM 기술을 직접 습득하게 하여, 명시적인 모델링이나 대규모 시행착오 없이 미세한 조율(fine-grained coordination) 및 접촉 동역학을 포착할 수 있는 대안을 제공합니다.
본 서베이는 IL에 기반한 DM 방법을 개괄하고, 최근의 발전 사항을 자세히 설명하며, 이 분야의 주요 도전 과제를 다룹니다. 또한, IL 기반 DM을 향상시키기 위한 잠재적인 연구 방향을 탐색합니다.
IL 기반 DM 접근 방식은 크게 5 가지 범주로 분류됩니다:
- Behavioral Cloning (BC),
- Inverse Reinforcement Learning (IRL),
- Generative Adversarial Imitation Learning (GAIL), 그리고 확장 프레임워크로서
- Hierarchical Imitation Learning (HIL) 및
- Continual Imitation Learning (CIL)입니다.
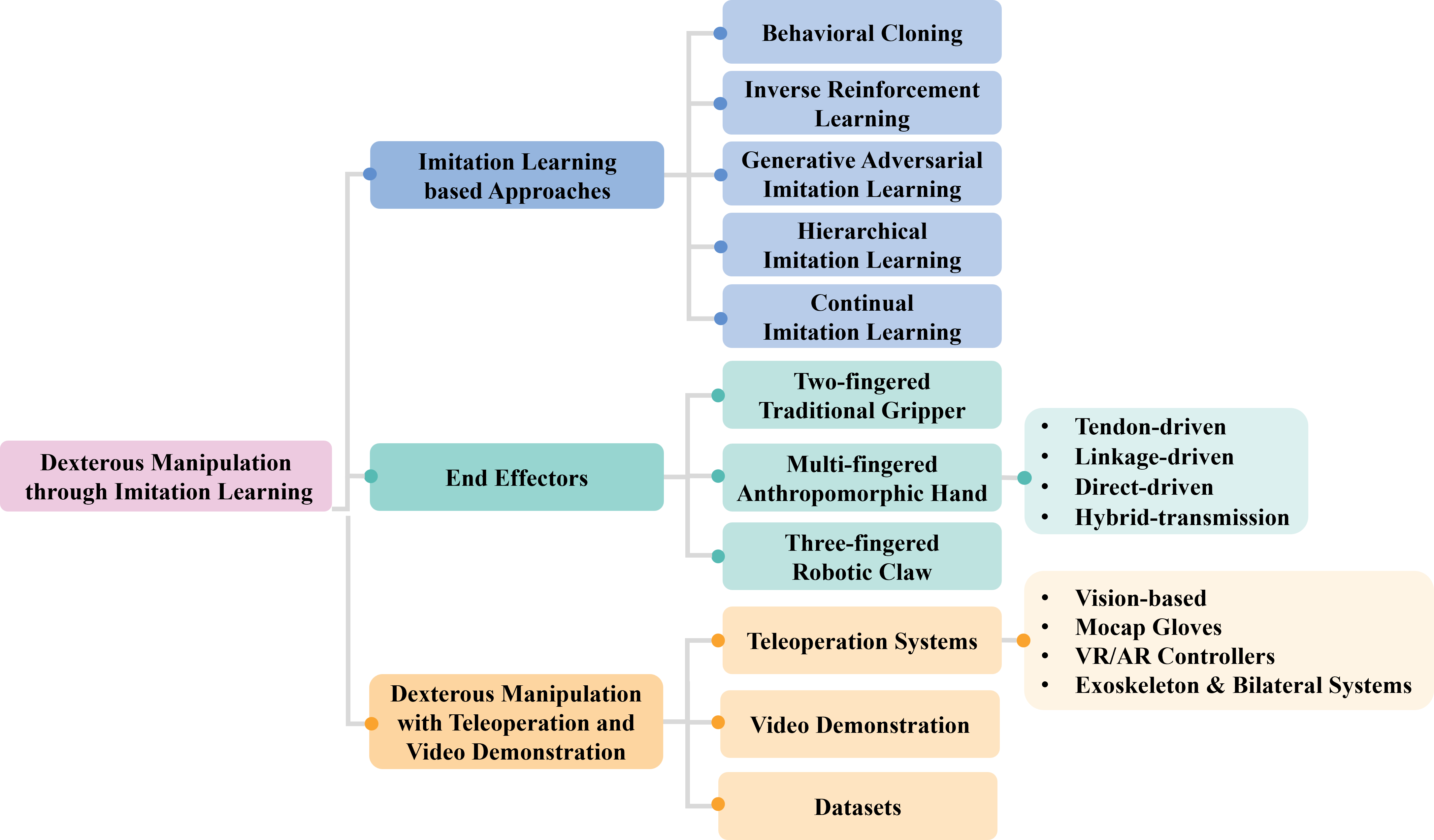
본 서베이의 전체 분류 체계: IL 기반 접근법, End-effector, Teleoperation 및 데이터셋
1.1 Behavioral Cloning (BC)
BC는 전문가 데모의 state-action 쌍으로부터 직접 학습하여 전문가 행동을 복제하는 지도 학습(supervised learning) 패러다임입니다. 보상 신호나 탐색(exploration) 없이 상태에서 행동으로의 직접 매핑을 특징으로 합니다. 목표 함수는 데모된 액션의 negative log-likelihood를 최소화하는 것입니다:
L(\pi) = -E_{(s,a)\sim p_D}[\log \pi(a | s)]
여기서 D = \{\tau_1, \dots, \tau_n\}는 n개의 데모 집합이며, 각 데모 \tau_i는 길이 N_i의 state-action 쌍 시퀀스 \{(s_1, a_1), \dots, (s_{N_i}, a_{N_i})\}입니다. BC는 푸싱(pushing) 및 grasping과 같은 비교적 간단한 작업에서 효과적인 성능을 보였습니다. 그러나 훈련 중 보지 못한 상태에 직면할 때 전문가 행동에서 벗어나는 액션을 생성할 수 있는 distribution shift 및 sequential decision-making 과정에서 오류가 누적되는 compounding error 문제에 취약합니다. 이를 완화하기 위해 계층적 프레임워크 [29]를 사용하거나, 단계별 액션 대신 전체 액션 시퀀스를 예측하여 유효 결정 시간 범위(effective decision horizon)를 줄이는 접근 방식 [53]이 제안되었습니다. 인간 데모에 흔한 multi-modal 데이터를 모델링하기 위해 에너지 기반 모델링 [26], 가우시안 혼합 모델 [58], 생성 모델 [59] 등이 탐구되었으며, 최근 Diffusion models [32, 60, 61, 62]이 BC 방법의 강건성 및 일반화 향상에 큰 잠재력을 보여주고 있습니다. BC 기반 방법은 일반화 및 multi-modal 액션 분포 모델링에 어려움을 겪지만, Diffusion models는 직접 액션 시퀀스를 생성하거나 고수준 전략을 안내하는 방식으로 유연성을 향상시키고 있습니다.
1.2 Inverse Reinforcement Learning (IRL)
IRL은 사전 정의된 보상 함수를 최대화하기 위해 정책을 학습하는 기존 RL 프레임워크를 역전시킵니다. 대신, 전문가 데모 집합 D를 가장 잘 설명하는 기저의 보상 함수 R(s, a)를 추론하는 것을 목표로 합니다. 데모는 최적 또는 거의 최적의 정책을 따르는 전문가에 의해 생성되었다고 가정합니다.
IRL 문제는 일반적으로 유한 Markov Decision Process M = \langle S, A, T, R, \gamma \rangle 내에서 공식화되며, 여기서 S와 A는 상태 및 액션 공간, T(s'|s, a)는 상태 전이 확률, R(s, a)는 보상 함수, \gamma \in [0, 1]는 할인율입니다. 보상 함수는 종종 특징 함수 \phi(s, a)의 선형 조합 R(s_t, a_t) = w^\top\phi(s_t, a_t)으로 표현됩니다. 정책 \pi 하에서의 기대 특징 카운트는 \mu_\phi(\pi) = \sum_{t=0}^\infty \gamma^t \psi_\pi(s_t)\phi(s_t, a_t)로 정의됩니다. IRL은 보상 함수를 수동으로 정의하기 어려운 DM 시나리오에서 특히 유리합니다.
최근 연구들은 reward normalization, task-specific feature masking [63], adaptive sampling [64], 사용자 피드백 통합 [65], 비정형 데모로부터 보상 함수 학습 [67], Proximal Policy Optimization [45]과의 통합 [68], 시각 기반 인간-로봇 협업 [69] 등을 통해 IRL 프레임워크를 발전시켰습니다. IRL은 전문가 데모로부터 기저 보상 함수를 추론함으로써 복잡한 행동을 일반화하고 다양한 환경에 적응할 수 있도록 하지만, 고차원 액션 공간이나 희소한 피드백 신호에서 정확한 보상 함수 추정 및 대량의 데모 데이터 요구와 같은 한계에 직면합니다.
1.3 Generative Adversarial Imitation Learning (GAIL)
GAIL은 GAN [102] 프레임워크를 IL 영역으로 확장합니다. 모방 프로세스를 생성자와 판별자 사이의 2인 적대적 게임으로 공식화합니다. 생성자는 전문가 데모와 유사한 행동을 생성하려는 정책 \pi에 해당하며, 판별자 D(s, a)는 state-action 쌍 (s, a)가 전문가 데이터 M에서 왔는지 또는 \pi에 의해 생성되었는지 평가합니다. GAIL은 전문가와 생성자의 state-action 분포 사이의 Jensen-Shannon divergence를 최소화합니다.
판별자는 다음 목표를 최대화하도록 훈련됩니다:
\arg \min_D -E_{d_M(s,a)}[\log D(s, a)] - E_{d_\pi(s,a)}[\log(1 - D(s, a))]
생성자의 정책 \pi는 판별자에서 파생된 보상 r_t = -\log(1 - D(s_t, a_t))을 사용하여 RL로 최적화됩니다. 이 적대적 훈련 과정을 통해 GAIL은 명시적으로 보상 함수를 복구하지 않고도 전문가 데모로부터 복잡한 행동을 효과적으로 학습합니다.
GAIL은 DM에서 널리 채택되었지만, 데모 데이터의 품질 및 가용성, 그리고 훈련 불안정성(mode collapse, gradient vanishing) 문제에 크게 의존합니다. Hindsight Experience Replay [77], semi-supervised correction [76], Sim-to-real transfer [78] 등이 데이터 문제를 해결하려 시도했으며, Variational Autoencoders [79], Wasserstein GAN [80], self-organizing generative model [82] 등을 사용하여 훈련 안정성을 개선하고 Mode collapse를 완화하려는 노력이 있었습니다. GAIL은 적대적 훈련의 근본적인 한계를 상속받아 훈련 불안정성 및 고차원 액션 공간으로의 확장 어려움에 직면합니다.
1.4 Hierarchical Imitation Learning (HIL)
HIL은 복잡한 작업을 계층적 구조로 분해하여 해결하도록 설계된 IL 프레임워크입니다. 일반적으로 2단계 계층 구조를 채택하며, 상위 수준 정책은 현재 상태 및 작업 요구 사항에 따라 하위 작업 또는 원시(primitives) 시퀀스를 생성하고, 하위 수준 정책은 하위 작업을 실행하여 전체 목표를 달성합니다. 이 계층적 분해는 의사 결정 및 제어를 분리하여 장기적인 복잡한 작업을 보다 효과적으로 처리할 수 있도록 합니다.
상위 정책 \pi_h는 미리 정의된 원시 집합 \{p_1, \dots, p_K\}에서 원시 p_i를 선택합니다: \pi_h(s_t) = p_i. 해당 하위 정책 \pi_{p_i}는 선택된 원시를 실행할 액션을 생성합니다: a_t = \pi_{p_i}(s_t). 전체 목표는 누적 손실 함수를 최소화하는 것입니다:
L(\pi) = \sum_{t=1}^T E_{(s_t,a_t)\sim\pi}[\ell(s_t, a_t)]
HIL의 주요 장점은 작업을 계층적 구조로 분해하여 직접적인 액션 공간 탐색의 복잡성을 줄이는 것입니다.
CompILE [88], HDR-IL [89], ARCH [90], XSkill [91], LOTUS [92] 등의 연구들이 작업 분해, 기술 일반화, 장기적인 작업 처리에 기여했습니다. 최근 연구들은 Play data [93, 94]를 활용하여 두 수준의 정책을 효율적으로 훈련하는 방법을 탐구했습니다. HIL은 작업 분해 및 기술 일반화에서 상당한 이점을 보여주지만, Cross-modal 기술 일반화에서의 적응성 및 동적 환경에서의 모델 강건성 및 연속성 확보에 어려움을 겪고 있습니다.
1.5 Continual Imitation Learning (CIL)
CIL은 지속 학습(continual learning)과 IL을 통합하여 에이전트가 동적으로 변화하는 환경에서 전문가 행동을 모방함으로써 기술을 지속적으로 습득하고 적응할 수 있도록 합니다. 에이전트는 초기 단계에서 전문가 데모로부터 기본 기술을 학습하고, 이후 단계에서 점진적으로 지식을 축적하고 새로운 작업이나 환경에 적응하며 이전에 습득한 기술을 잊어버릴 위험을 완화합니다.
CIL에서 정책 \pi는 이전에 접한 모든 작업에 대한 누적 모방 손실을 최소화하여 최적화됩니다:
L(\pi) = -\sum_{i=1}^t \lambda^{(i)} E_{(s^{(i)},a^{(i)})\sim \rho^{(i)}_{exp}}[\log \pi(a^{(i)} | s^{(i)})]
여기서 \lambda^{(i)}는 t개의 각 작업에 할당된 가중치이고 \rho^{(i)}_{exp}는 작업 i에 대한 전문가 state-action 쌍의 분포입니다.
초기 연구 [95]는 이전에 습득한 기술을 손상시키지 않고 작업 간 전환을 가능하게 했지만, 상당한 저장 및 계산 리소스가 필요했습니다. Task-specific adapter 구조 [96], 비지도 기술 발견 [92], 행동 증류를 통한 통합 정책 학습 [97], Deep Generative Replay (DGR) [98], 자기 지도 학습 [99] 등 다양한 접근 방식이 제안되었습니다. CIL은 효과적인 멀티태스킹 학습, DGR 기술 적용, 자기 지도 기술 추상화에 중점을 두지만, 생성된 데이터의 품질 및 일관성, 리소스 소비, 현실 세계 응용을 위한 일반화 능력 부족과 같은 실질적인 배포 과제가 남아 있습니다.
2 End Effectors for Dexterous Manipulation
DM을 위한 End-effector는 크게 두 가지 그리퍼(two-fingered grippers), 다지 인간형 손(multi-fingered anthropomorphic hands), 세 가지 로봇 클로(three-fingered robotic claws)로 나뉩니다. 두 가지 그리퍼는 신뢰성, 단순성, 제어 용이성으로 널리 사용되지만 (예: Franka robot [104], ALOHA [53], Mobile ALOHA [112]), 손 안에서의 객체 재구성 능력이 제한적이고 인간 손과의 형태학적 차이로 인해 인간 데모로부터 학습하는 데 방해가 됩니다 [115]. 다지 인간형 손은 인간과 유사한 형태를 가지며 인간이 사용하도록 설계된 객체와의 상호작용에 더 적합합니다 [116].
구동 메커니즘에 따라
- Tendon-driven (예: Shadow Dexterous Hand [130]),
- Linkage-driven (예: INSPIRE-ROBOTS RH56 [122]),
- Direct-driven (예: Allegro Hand [125]),
- Hybrid-transmission (예: DLR/HIT Hand II [179]) 방식으로 분류됩니다.
Tendon-driven은 높은 DoF와 Dexterity를 제공하지만 마찰, 마모 등의 문제가 있고, Linkage-driven은 정밀하고 강건하지만 DoF가 적은 경향이 있습니다. Direct-driven은 제어 정밀도가 높지만 질량, 관성 증가의 단점이 있으며, Hybrid 방식은 여러 방식의 장점을 결합합니다. 이러한 손들은 높은 Dexterity를 제공하지만 복잡성, 비용, 고장 취약성 등의 과제가 있습니다.

다양한 다지 인간형 손(multi-fingered anthropomorphic hands)의 예시
세 가지 로봇 클로 (예: DEX-EE [204], BarrettHand [208])는 두 가지 그리퍼와 다지 인간형 손 사이의 절충안으로, 일반적인 grasping 유형과 제한적인 in-hand manipulation을 지원합니다.

세 가지 로봇 클로(three-fingered robotic claws)의 예시
3 Teleoperation Systems and Data Collection
Teleoperation 시스템은 인간-로봇 협업을 위한 인터페이스를 제공하며, 로봇 행동이 인간 수준의 지능을 따르도록 합니다. 이는 인간의 광범위한 지식과 경험을 활용하여 복잡한 장면에서 다양한 작업을 판단하고 피드백에 신속하게 대응할 수 있기 때문에 매우 직관적입니다. Teleoperation 중 로봇 상태와 해당 액션 데이터를 수집하여 end-to-end IL을 위한 데이터셋을 구축할 수 있습니다. Teleoperation 시스템은 로컬 사이트(인간 조작자, I/O 장치)와 원격 사이트(로봇, 센서)로 구성됩니다. DM을 위한 I/O 장치로는 카메라 [17], mocap gloves [16], VR/AR controllers [14], exoskeletons 및 bilateral systems [53] 등이 사용됩니다.
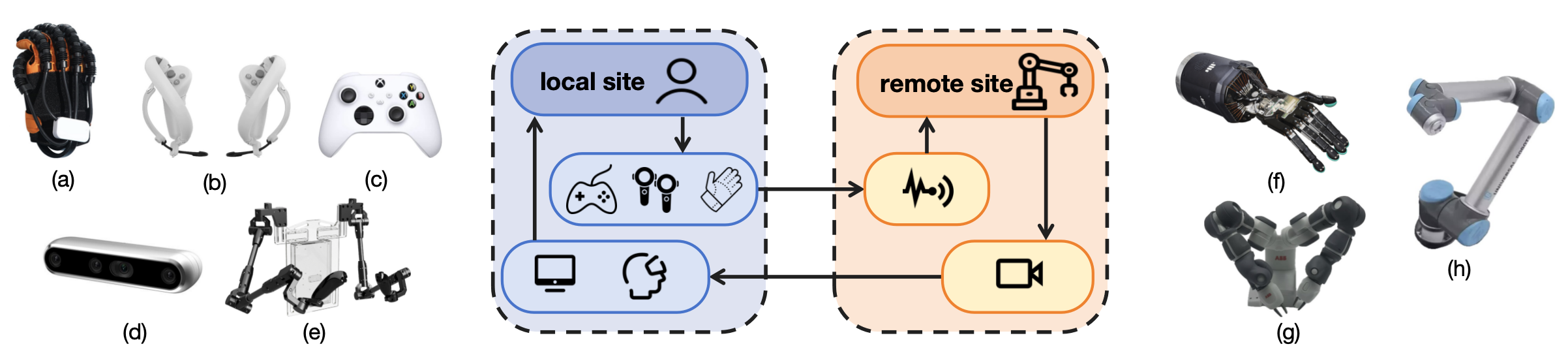
Teleoperation 시스템 구성: 로컬 사이트(조작자, I/O 장치)와 원격 사이트(로봇, 센서)
Vision-based systems는 컴퓨터 비전으로 손 포즈를 추정하지만, 가림(occlusion), 조명 등의 문제에 취약합니다. TeachNet [222], Dexpilot [18], Robotic Telekinesis [17], AnyTeleop [19], ACE [221] 등이 개발되었습니다. 인간 손과 로봇 손의 형태학적 불일치를 해결하기 위한 연구 [20]도 있습니다.
Mocap Gloves는 센서를 통해 인간 손 움직임을 직접 정밀하게 추적합니다 [16]. 비싸지만 데이터 수집 효율을 높입니다.
VR/AR Controllers는 몰입형 환경을 제공하며 저비용 솔루션으로 탐구됩니다 [14, 234]. 시뮬레이션 [245], 혼합 현실 [234], haptic feedback 통합 [235] 등이 시도되었습니다.
Exoskeleton 및 Bilateral Systems는 joint space 제어에 중점을 두어 inverse kinematics (IK) 계산 문제를 회피합니다 [239, 240, 241]. 리더-팔로워 구조로 힘 피드백을 제공합니다 [53, 242, 243].
Retargeting [19, 221]은 다양한 로봇 플랫폼에서 데모 데이터를 공유할 수 있게 합니다. 주요 데이터셋으로는 MIME [250], RH20T [251], BridgeData [252, 253], DROID [254] 등이 있으며, 대규모의 다양한 작업 및 환경 데모 데이터를 제공합니다. 데이터 증강 [255, 256] 및 데모 생성 시스템 [257, 258, 259]은 데이터 수집 비용을 줄이고 데이터 다양성을 높이는 데 기여합니다. ARCTIC [260], DexGraspNet [261], OAKINK2 [262] 등은 특히 bimanual manipulation 및 손-객체 상호작용에 초점을 맞춘 데이터셋입니다.
4 Challenges and Future Directions
IL 기반 DM은 데이터 수집 및 생성, 벤치마킹 및 재현성, 새로운 환경으로의 일반화, 실시간 제어, 안전성, 강건성 및 사회적 준수 측면에서 여러 도전 과제에 직면해 있습니다.
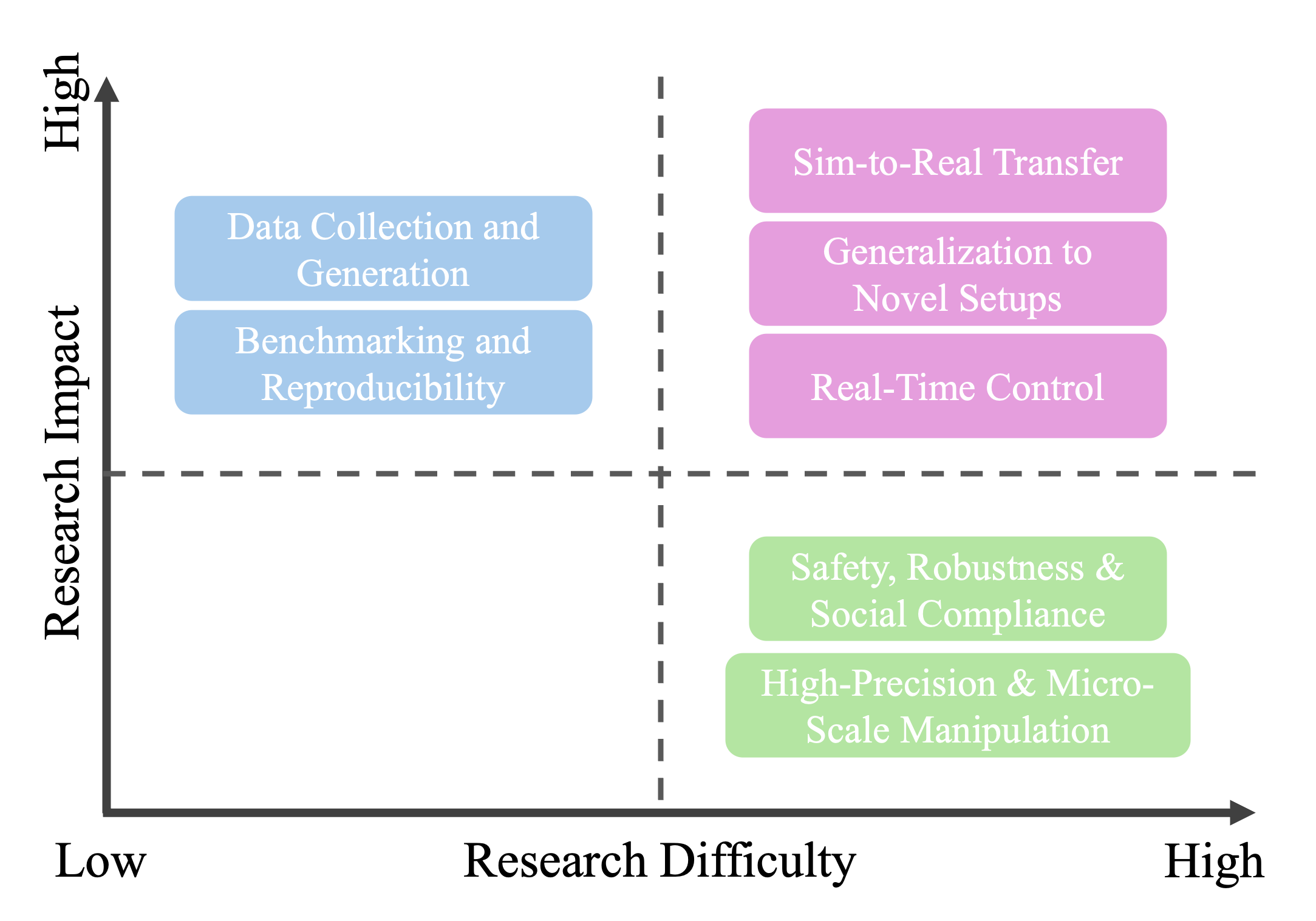
연구 난이도(difficulty)와 영향력(impact) 관점에서 본 주요 도전 과제 매트릭스
- Data Collection and Generation: 이종 데이터 융합(heterogeneous data fusion), 데이터 양, 품질, 다양성 확보의 어려움, 고차원 데이터 희소성, 데이터 수집 비용이 문제입니다. 미래 연구 방향으로는 Multi-modal alignment 기술, Cross-embodiment 학습 프레임워크, 합성 데이터 증강, Domain randomization, 생성 모델, Crowdsourced teleoperation, Self-supervised learning, 데이터 수집 프로토콜 표준화, Sim-to-real fidelity 향상, Differentiable physics engines, Adaptive parameter tuning, Self-supervised real-to-sim refinement 등이 있습니다.
- Benchmarking and Reproducibility: 현실 세계 하드웨어 실험의 의존성 및 시뮬레이션 환경의 가변성으로 인해 벤치마킹 및 결과 재현이 어렵습니다. 표준화된 벤치마킹 프레임워크 및 오픈 소스 데이터셋 구축, 시뮬레이션 물리 파라미터 및 환경 표현의 일관성 확보, 다양한 로봇 형태에 걸친 Multi-modal 데이터 기록, 표준 평가 프로토콜 마련이 필요합니다.
- Generalization to Novel Setups: 작업 및 환경 가변성, 전통적 IL의 적응 학습 한계, Sim-to-real transfer 문제, Cross-embodiment 적응성 부족이 문제입니다. 적응적 및 지속 학습 프레임워크 (Meta-learning, RL fine-tuning), 불확실성 인지 모델, 물리 시뮬레이션의 현실성 향상, Hybrid learning 접근 방식, Morphology-agnostic policy learning, 그래프 기반 및 잠재 공간 표현 활용, Modular policy architectures, Few-shot adaptation 등이 미래 연구 방향입니다.
- Real-Time Control: 고차원 액션 공간 및 복잡한 동역학으로 인한 계산 복잡성이 문제입니다. Model-based (MPC)와 Model-free (RL) 방법의 효율적인 활용, Hybrid control strategies, Accelerated learning 기술, 고성능 컴퓨팅 하드웨어 (GPUs, TPUs), Edge computing, Custom ASICs, Neuromorphic computing 등 하드웨어 아키텍처 개선이 필요합니다.
- Safety, Robustness, and Social Compliance: 오류 탐지 및 복구, 안전 조치(충돌 회피, 힘 조절), 사회적 규범 준수가 중요합니다. 대규모 실패 데이터셋 및 표준화된 벤치마킹, Self-supervised multi-modal anomaly detection, 강건한 정책 훈련/벤치마킹, 충돌 완화를 위한 Compliant actuators 및 Soft robotic designs, 인간 중심 환경에 통합되기 위한 사회적 준수 학습, Interactive learning paradigm, Multi-modal human-robot interaction datasets, 사회적 준수 벤치마크 표준화 등이 미래 연구 방향으로 제시됩니다.
5 Conclusion
IL은 로봇이 인간과 유사한 기술과 정밀도로 DM 작업을 수행할 수 있도록 하는 데 상당한 가능성을 보여주었습니다. 그러나 데이터 수집, 일반화, 실시간 제어, 안전성, Sim-to-real transfer와 관련된 문제가 실질적인 배포를 가로막고 있습니다. 이 분야의 발전을 위해서는 최적화된 IL 알고리즘 개발, 인간-로봇 협업 강화, 첨단 센서 시스템 통합에 초점을 맞춘 미래 연구가 필수적입니다. DM의 미래는 산업 자동화부터 헬스케어 및 서비스 로봇에 이르기까지 큰 잠재력을 가지고 있으며, IL 및 로봇 조작의 경계를 계속 확장함으로써 더 유능하고 적응 가능하며 지능적인 로봇 시스템의 길을 열 수 있을 것입니다.