📃Offline RL Survey 리뷰
- 오프라인 RL(Offline RL)은 환경과의 상호작용 없이 정적 데이터셋만을 이용해 학습하는 패러다임으로, 실제 환경 적용에 필수적이지만 데이터 분포 변화(distributional shift) 문제를 해결해야 합니다.
- 본 논문은 오프라인 RL 기법을 분류하는 새로운 Taxonomy를 제안하고, 최신 알고리즘 및 벤치마크를 종합적으로 검토하며 다양한 데이터 특성에 따른 기법별 성능을 분석합니다.
- 더불어 오프라인 정책 평가(Off-Policy Evaluation, OPE)를 포함한 미해결 과제들을 논의하고 분야의 향후 연구 방향에 대한 통찰을 제공합니다.
Brief Review
본 논문은 정적 데이터셋(\mathcal{D})으로부터 학습하며 환경과의 추가 상호작용 없이 정책(\pi_{\text{off}})을 도출하는 Offline Reinforcement Learning (오프라인 강화학습) 분야에 대한 포괄적인 서베이 논문입니다. 온라인 또는 Off-policy RL (오프-폴리시 강화학습)과 달리 오프라인 RL은 고비용 또는 위험성으로 인해 환경 상호작용이 어려운 실제 응용 분야(예: 교육, 헬스케어, 로보틱스)에 특히 유용합니다.
오프라인 RL의 핵심 과제는 학습된 정책(\pi_{\theta})이 훈련 데이터의 분포(\pi_{\beta}또는d^{\pi_\beta})에서 벗어날 때 발생하는 Distributional Shift (분포 변화) 문제입니다. 특히 function approximator의 과대 추정(overestimation)과 오차 누적(compounding error)이 문제가 됩니다. 가치 기반 방법(value-based method)의 경우, 벨만 에러(Bellman error) 최소화 목표 함수
J(\phi) = \mathbb{E}_{s, a, s' \sim \mathcal{D}}[(r(s, a) + \gamma \mathbb{E}_{a' \sim \pi_{\text{off}}(\cdot|s')}[Q^{\pi}_{\phi}(s', a')] - Q^{\pi}_{\phi}(s, a))^2]
에서a'이 데이터셋의 행동 분포\pi_{\beta}와 다를 때 문제가 발생합니다.
종류
논문은 오프라인 RL 방법론을 분류하기 위한 새로운 Taxonomy (분류체계)를 제안합니다. 상위 수준에서는 학습 대상을 기준으로 Model-Based (모델 기반), One-step (원스텝), Imitation Learning (모방 학습) 방법으로 나뉩니다. 또한, 손실 함수나 훈련 절차에 대한 변형인 Policy Constraints (정책 제약), Regularization (정규화), Uncertainty Estimation (불확실성 추정)을 부가적인 특성으로 설명합니다.
Policy Constraints: 학습된 정책\pi_{\theta}를 행동 정책\pi_{\beta}에 가깝게 제약합니다.
- Direct (직접):\pi_{\beta}를 명시적으로 추정하고\mathcal{D}(\pi_{\theta}(\cdot|s), \hat{\pi}_{\beta}(\cdot|s)) \le \epsilon와 같은 제약 조건(e.g.,f-divergence 사용)을 부여합니다 (BCQ, BRAC). 추정 오류에 민감합니다.
- Implicit (암묵적):\pi_{\beta} 추정 없이 수정된 목적 함수를 통해 암묵적으로 제약합니다. 아래와 같은 Advantage-weighted regression 형태가 대표적입니다 (BEAR, AWR, AWAC, TD3+BC). J(\theta) = \mathbb{E}_{s,a \sim \mathcal{D}}[\log \pi_{\theta}(a|s) \exp(\frac{1}{\lambda} \hat{A}^{\pi}(s, a))]
Importance Sampling (IS): Off-policy 정책 평가를 위해 사용됩니다. 트라젝토리 확률 비율의 곱(w_{i:j})으로 인해 분산이 매우 높습니다. Variance Reduction (분산 감소) 기법(Per-decision IS, Doubly Robust Estimator, Marginalized IS)이 제안되었습니다. Marginalized IS는 상태 한계 분포 비율(\rho_{\pi}(s)) 또는 상태-행동 한계 분포 비율(\rho_{\pi}(s, a))의 벨만 방정식d^{\pi_\beta}(s')\rho_\pi(s') = (1-\gamma)d_0(s') + \gamma \sum_{s,a} d^{\pi_\beta}(s)\rho_\pi(s)\pi(a|s)T(s'|s,a)을 활용하여 분산 문제를 완화합니다 (GenDICE).
Regularization: 정책 또는 가치 함수에 페널티 항을 추가하여 바람직한 속성을 부여합니다.
- Policy Regularization: 정책의 엔트로피(entropy)를 최대화하여 확률성(stochasticity)을 높입니다 (SAC).
- Value Regularization: OOD 행동에 대한 Q-값 추정을 낮게 강제하여 보수적인 가치 추정을 수행합니다. CQL은 \max_{\mu} \mathbb{E}_{s \sim \mathcal{D}, a \sim \mu(\cdot|s)}[Q^{\pi}_{\phi}(s, a)] - \mathbb{E}_{s \sim \mathcal{D}, a \sim \hat{\pi}_{\beta}(\cdot|s)}[Q^{\pi}_{\phi}(s, a)] + \mathcal{R}(\mu) 와 같은 정규화 항을 통해 데이터셋의 가치 함수가 참 값의 하한(lower bound)이 되도록 학습합니다.
Uncertainty Estimation: 학습된 정책, 가치 함수 또는 모델의 불확실성을 추정하여 보수성의 정도를 동적으로 조절합니다. 보통 앙상블(ensemble)을 사용하여 예측 분산 등으로 불확실성을 측정합니다 (REM).
Model-Based Methods: 데이터셋\mathcal{D}로 전이 동역학(T)과 보상 함수(r)를 학습합니다. 학습된 모델은 계획(planning)에 사용되거나 모델 롤아웃(model rollout)을 통해 합성 데이터 생성에 사용됩니다. 모델 분포 변화 문제를 피하기 위해 불확실성을 기반으로 보상에 페널티를 주는 보수적인 모델(\tilde{r}_{\psi_r}(s, a) = r_{\psi_r}(s, a) - \lambda U_r(s, a))을 학습하는 접근 방식이 있습니다 (MOReL, MOPO, COMBO). COMBO는 모델 기반 환경에서의 가치 정규화(value regularization)를 통해 불확실성 정량화 없이도 보수성을 확보합니다.
One-Step Methods: 정책 평가 및 정책 개선 단계를 반복하지 않고, 행동 정책(\pi_{\beta})의 가치 함수(Q^{\pi_{\beta}})를 정확하게 학습한 후 단일 정책 개선 단계만 수행합니다. 이를 통해 OOD 행동에 대한 가치 평가를 피합니다. IQL(Implicit Q-Learning)은 가치 함수(V^{\pi}) 학습에 Expectile Regression (분위 회귀) 손실 함수를 사용하여 데이터 분포 내의 ‘좋은’ 행동들에 대한 Q값의 상한에 근사합니다.
Imitation Learning: 행동 정책을 모방(mimic)합니다. 단순 Behavior Cloning (행동 복제, BC)은 전체 데이터를 복제합니다. 고급 기법은 가치 함수 등을 사용하여 차선 행동을 필터링하거나(BAIL, CRR) 원하는 결과(목표, 보상 등)에 조건화된 정책을 학습합니다(RvS).
Trajectory Optimization (트라젝토리 최적화): 전체 트라젝토리(\tau = (s_0, a_0, \dots, s_H))에 대한 결합 상태-행동 분포(p_{\pi_{\beta}}(\tau))를 시퀀스 모델(Sequence Model, 예: Transformer)로 학습합니다. 학습된 분포를 기반으로 원하는 수익(Return-to-Go) 등에 조건화하여 계획을 수행합니다(TT, DT). 희소 보상 문제에 강점을 보입니다.
평가
Off-policy Evaluation (OPE, 오프-폴리시 평가)는 오프라인 RL의 중요한 Open Problem 중 하나입니다. 환경과의 상호작용 없이 오프라인으로 정책의 성능을 정확히 추정하고 하이퍼파라미터를 튜닝하는 것은 실용적인 오프라인 RL에 필수적입니다. 주요 OPE 방법에는 Model-Based 접근법, Importance Sampling, Fit Q Evaluation (FQE)가 있습니다. 경험적 연구들에 따르면 FQE가 종종 좋은 성능을 보이지만, 모든 설정에서 일관적으로 우수한 방법은 아직 없습니다 (DOPE 벤치마크).
오프라인 RL Benchmark로는 D4RL과 RL Unplugged가 널리 사용됩니다.
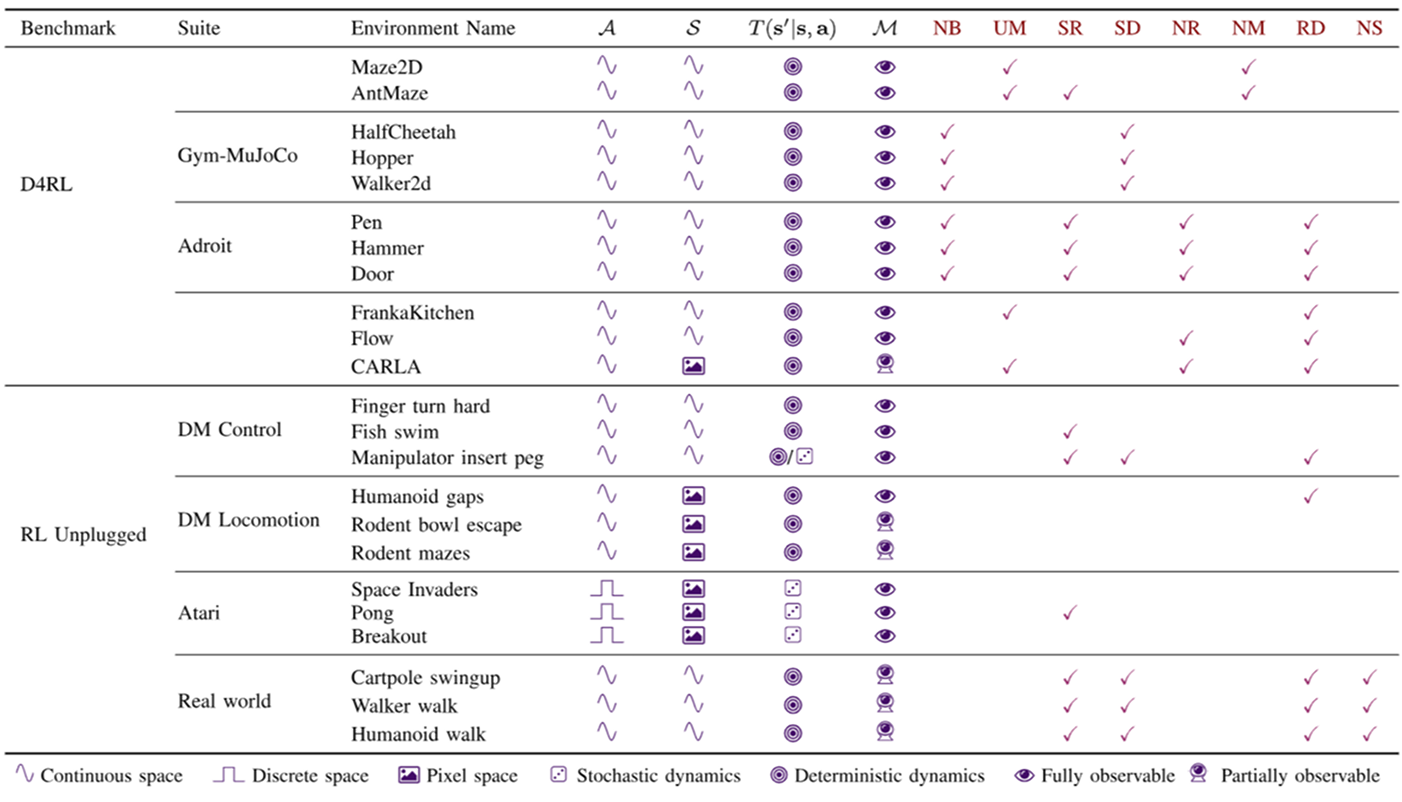
이들은 Narrow and Biased Data Distributions (좁고 편향된 데이터 분포), Undirected and Multitask Data (지향되지 않은 다중 작업 데이터), Sparse Rewards (희소 보상), Suboptimal Data (차선 데이터), Nonrepresentable Behavior Policies (표현 불가능한 행동 정책), Non-Markovian Behavior Policies (비 마르코프 행동 정책), Realistic Domains (현실적인 도메인) 등 실제 응용에 중요한 Dataset Design Factors (데이터셋 설계 요소)를 포함하는 다양한 환경과 데이터셋을 제공합니다.
하지만 Stochastic Dynamics (확률적 동역학), Nonstationarity (비정상성), Risky Biases (위험한 편향), Multiagent 환경 등은 여전히 부족한 실정입니다. D4RL 벤치마크 성능 분석에 따르면 최근 방법(TT, IQL)과 트라젝토리 최적화 및 원스텝 방법이 희소 보상이나 다중 작업 데이터에서 강점을 보이며 유망한 분류로 나타납니다.
미래 연구 방향으로는 OPE의 신뢰성 향상, Unsupervised RL 기법을 활용한 레이블 없는 데이터 활용, Incremental RL을 통한 온라인 Fine-tuning 전략 개발, Safety-critical RL (안전 필수 강화학습, 예: CVaR) 분야 연구 등이 제안됩니다. 효과적인 데이터 수집 및 curation 또한 알고리즘 개발만큼 중요합니다.