📃Physics Informed RL Survey 리뷰
- 이 논문은 Physics-Informed Reinforcement Learning(PIRL) 연구 동향을 조사하고, 물리학 정보를 RL에 통합하는 새로운 분류 체계를 제시합니다.
- PIRL은 방정식, 제약 조건, 시뮬레이터 등 다양한 물리학적 사전 정보를 RL 파이프라인의 상태, 액션, 보상, 네트워크, 모델 등 다양한 부분에 통합하여 RL의 효율성과 안전성을 향상시킵니다.
- 이 논문의 분석은 PIRL의 다양한 적용 분야와 함께 해결되지 않은 문제점 및 향후 연구 방향을 제시하여 분야의 성장에 기여합니다.
Brief Review
본 논문은 물리 정보를 활용한 강화 학습(Physics-Informed Reinforcement Learning, PIRL)에 대한 포괄적인 조사 논문입니다. PIRL은 물리적 제약 조건과 물리 법칙을 학습 과정에 통합하여 기계 학습 프레임워크, 특히 강화 학습(RL)의 성능을 향상시키는 접근 방식입니다.
Introduction
RL은 시행착오를 통해 의사 결정 및 최적화 문제를 해결하는 유망한 접근 방식입니다. 자율 주행, 로봇 공학, 연속 제어 등 다양한 분야에서 성공을 거두었지만, 실제 데이터의 샘플 효율성 부족, 고차원 연속 상태/액션 공간 처리의 어려움, 안전한 탐색, 적절한 보상 함수 정의, 시뮬레이터-실제 환경 간의 차이 등의 문제에 직면해 있습니다. 물리 정보를 ML 모델에 통합하는 PIML(Physics-Informed Machine Learning)은 불완전한 물리 정보와 데이터로부터 더 효율적으로 학습하고, 더 나은 일반화 성능을 보이며, 물리적으로 타당한 솔루션을 제공하는 장점이 있습니다. RL은 대부분 실제 세계 문제와 관련이 있으며 설명 가능한 물리적 구조를 가지고 있기 때문에 물리 정보 통합에 적합한 분야입니다. 최근 연구들은 물리 정보를 RL 파이프라인에 통합하여 이러한 과제를 해결하고 있습니다. 예를 들어, 물리 정보를 사용하여 고차원 연속 상태를 직관적인 표현으로 줄이거나 더 나은 시뮬레이션을 구축하며, 안전한 학습을 위한 물리적 제약 조건을 보상 함수에 통합하는 등의 시도가 이루어지고 있습니다. PIRL 연구는 지난 6년간 증가하는 추세를 보이며 주목받고 있습니다.
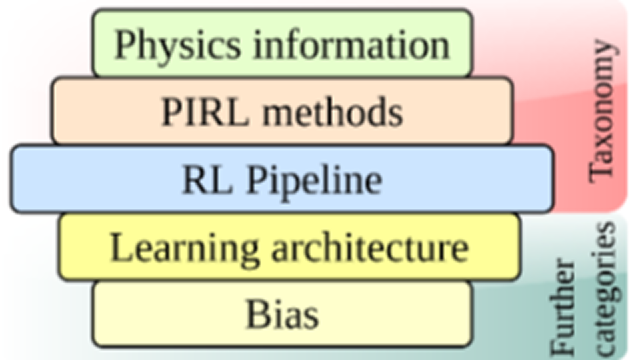
- Taxonomy: 어떤 물리 지식/프로세스가 모델링되고, 어떻게 표현되며, RL 접근 방식에 어떻게 통합되는지에 대한 통합 분류 체계를 제시합니다.
- Algorithmic Review: 물리 정보 기반 RL 방법론에 대한 최신 접근 방식을 통일된 표기법과 기능 다이어그램을 사용하여 검토합니다.
- Training and evaluation benchmark Review: 검토된 문헌에서 사용된 평가 벤치마크를 분석하여 인기 있는 플랫폼/도구를 제시합니다.
- Analysis: 다양한 도메인에 걸친 model-based 및 model-free RL 애플리케이션에서 물리 정보가 특정 RL 접근 방식에 어떻게 통합되는지, 어떤 물리 프로세스가 모델링/통합되는지, 어떤 네트워크 아키텍처 또는 증강이 사용되는지 상세히 분석합니다.
- Open Problems: 현재 직면한 과제, 미해결 연구 질문 및 향후 연구 방향에 대한 관점을 제시합니다.
PIML: An Overview
물리 정보를 활용한 기계 학습 개요
PIML은 수학적 물리 모델과 관측 데이터를 학습 과정에 통합하여, 불완전하고 불확실하며 고차원적인 복잡한 시나리오에서도 물리적으로 일관된 솔루션을 찾는 것을 목표로 합니다. 물리 지식을 ML 모델에 추가하는 것은 물리/과학적 일관성 보장, 데이터 효율성 증가, 학습 과정 가속화, 일반화 능력 향상, 투명성/해석 가능성 증진과 같은 이점을 제공합니다. 물리 지식을 통합하는 세 가지 주요 전략은 다음과 같습니다.
- Observational bias: 물리적 원리를 반영하는 multi-modal 데이터를 사용하여 DNN을 학습시킵니다. 관측, 시뮬레이션, 물리 방정식 생성 데이터, 지도, 추출된 물리 데이터 등 다양한 소스의 데이터를 활용합니다.
- Learning bias: 손실 함수에 물리 기반의 페널티 항을 추가하여 사전 지식을 강화하는 방식입니다. PINN(Physics-Informed Neural Networks)은 PDE를 신경망의 손실 함수에 포함시키는 대표적인 예입니다.
- Inductive biases: custom neural network 구조를 통해 물리 원리를 ‘하드’ 제약 조건으로 통합하는 방식입니다. Hamiltonian NN, Lagrangian Neural Networks (LNNs) 등이 있습니다.
PIRL: Fundamentals, Taxonomy and Examples
물리 정보를 활용한 강화 학습: 기본, 분류 및 예시
RL 기본 (RL fundamentals)
RL은 MDP (Markov Decision Process) 프레임워크를 따르는 순차적 의사 결정 문제를 해결합니다. 에이전트(agent)와 환경(environment)이 상호 작용하며, 에이전트는 상태(s_t)를 관찰하고 행동(a_t)을 선택하며, 환경은 다음 상태(s_{t+1})와 보상(r_t)을 제공합니다. 목표는 누적 보상을 최대화하는 정책 \pi_\phi(a_t|s_t)의 매개변수 \phi를 찾는 것입니다. MDP는 튜플 (S, A, R, P, \gamma)로 표현되며, S는 상태 공간, A는 액션 공간, R은 보상 함수, P(s_{t+1}|s_t, a_t)는 환경 모델(전이 확률), \gamma \in [0, 1]는 할인 계수입니다. 목표 함수는 다음과 같습니다. J(\phi) = \mathbb{E}_{\tau \sim p_\phi(\tau)} \left[ \sum_{t=1}^T \gamma^{t-1} R(a_t, s_{t+1}) \right] 여기서 \tau는 에피소드의 상태-액션 시퀀스입니다. RL 알고리즘은 model-free (환경 모델 없이 학습)와 model-based (환경 모델을 사용하여 계획/학습)로 나눌 수 있습니다. 또한, online (최신 정책으로 수집한 데이터 사용), off-policy (경험 리플레이 버퍼의 데이터 사용), offline (고정된 데이터셋 사용)으로 분류됩니다.
PIRL 소개 (PIRL: Introduction)
PIRL은 물리 구조, 사전 지식(priors), 실제 물리 변수를 정책 학습 또는 최적화 과정에 통합하는 개념입니다. 이는 RL 알고리즘의 효율성, 샘플 효율성, 훈련 가속화에 기여합니다.
PIRL 분류 체계 (PIRL Taxonomy)
이 논문은 물리 정보 유형, 물리 정보를 통합하는 PIRL 방법, 그리고 RL 파이프라인의 세 가지 축을 중심으로 PIRL 분류 체계를 제시합니다.
- Physics information (types): representation of physics priors
- Differential and algebraic equations (DAE): PDE/ODE, 경계 조건(BC) 등 시스템 동역학 표현 (예: PINN).
- Barrier certificate and physical constraints (BPC): CLF, BF, CBF/CBC 등 안전 제약 조건 (예: 안전 중요 애플리케이션의 탐색 규제).
- Physics parameters, primitives and physical variables (PPV): 환경/시스템에서 추출/도출된 물리 값 (예: jam-avoiding distance, dynamic movement primitives).
- Offline data and representation (ODR): 시뮬레이터 기반 학습 개선을 위한 오프라인 데이터 또는 물리적으로 관련된 저차원 표현 학습.
- Physics simulator and model (PS): RL 알고리즘의 테스트베드 또는 물리적 정확성을 부여하기 위한 시뮬레이터 활용 (예: MBRL에서 시스템 모델 학습).
- Physical properties (PPR): 시스템 형태, 대칭 등 기본적인 물리 구조/속성 지식.
- PIRL methods: physics prior augmentations to RL
- State design: 관찰된 상태 공간 수정/확장 (예: 상태 융합, 특징 추출).
- Action regulation: 액션 값에 제약 조건 부과 (예: 안전 필터).
- Reward design: 효과적인 보상 설계 또는 보상 함수 증강.
- Augment policy or value N/W: 정책 또는 가치 함수의 업데이트 규칙, 손실, 구조 변경.
- Augment simulator or model: 기초 물리 지식 통합을 통한 시뮬레이터/모델 개선.
- RL Pipeline
- Problem Representation: 실제 문제를 MDP로 모델링 (상태, 액션, 보상 정의).
- Learning strategy: 에이전트-환경 상호 작용 방식, 학습 아키텍처, 알고리즘 선택 결정.
- Network design: 정책/가치 네트워크의 세부 구조 설계.
- Training: 네트워크 학습 (Sim-to-real 등 훈련 증강 포함).
- Trained policy deployment: 훈련된 정책 배포.
추가 분류 (Further categorization)
이 논문은 추가적으로 두 가지 범주를 사용하여 PIRL 구현을 설명합니다.
- Bias: PIML에서 사용되는 bias 개념(Observational, Learning, Inductive)과 PIRL 접근 방식의 관계를 분석합니다.
- Learning architecture: 물리 정보 통합을 위해 전통적인 RL 학습 아키텍처에 도입된 변경 사항에 따라 분류합니다.
- Safety filter: 안전 제약 조건을 보장하기 위해 에이전트의 액션을 조절하는 모듈 포함.
- PI reward: 보상 함수를 물리 정보로 수정.
- Residual learning: 물리 정보 기반 제어기와 데이터 기반 정책을 결합.
- Physics embedded network: 정책 또는 가치 함수 네트워크에 시스템 동역학 등 물리 정보 직접 통합.
- Differentiable simulator: 손실 기울기를 제어 액션에 대해 직접 계산할 수 있는 미분 가능한 물리 시뮬레이터 사용.
- Sim-to-Real: 시뮬레이터에서 학습 후 실제 환경으로 전이.
- Physics variable: 물리 매개변수, 변수, 프리미티브를 상태/보상 등에 추가.
- Hierarchical RL: 계층적 또는 커리큘럼 학습 설정에서 물리 정보를 통합.
- Data augmentation: 입력 상태를 저차원 표현 등으로 대체/증강하여 물리적으로 관련된 특징 도출.
- PI model identification: MBRL 설정에서 물리 정보를 모델 식별 과정에 통합.
PIRL: Review and Analysis
Algorithmic review: 위에 제시된 PIRL 방법 및 학습 아키텍처 범주를 기반으로 연구들을 그룹화하여 논의합니다. 예를 들어, State design에서는 CAV 제어에서의 물리 기반 상태 융합, Adaptive cruise control에서의 jam-avoiding distance 활용 등이 논의됩니다. Action regulation에서는 안전 중요 시스템의 CBF/CBC를 활용한 액션 제약이 강조되며, B_\epsilon(x)와 Lie derivative \mathcal{L}_f(x, u_{RL}) B_\epsilon(x)를 이용한 안전 조건이 언급됩니다. Reward design에서는 로봇 보행, 에너지 관리, 유체역학 등 다양한 분야에서 물리 기반 보상 함수 설계 사례가 제시됩니다. Augment simulator or model에서는 LNN을 사용한 시스템 모델 학습, sim-to-real 전이 개선을 위한 시뮬레이터 증강, 미분 가능한 시뮬레이터 사용 등이 포함됩니다. Augment policy and/or value N/W에서는 신경망 정책에 동적 시스템을 미분 가능한 레이어로 통합하는 Neural Dynamic Policies (NDP), 가치 함수를 HJB PDE를 푸는 PINN으로 취급하는 접근 방식 등이 소개됩니다.
Simulation/ evaluation benchmarks: 연구에서 사용된 다양한 시뮬레이터 및 평가 환경을 OpenAI Gym, MuJoCo, Pybullet, Deep mind control suite와 같은 표준 벤치마크와 SUMO, CARLA, IEEE distribution system benchmarks 같은 도메인별 플랫폼, 그리고 다수의 맞춤형 환경으로 분류하여 제시합니다.
Analysis:
- 연구 동향 및 통계: 가장 많이 사용되는 RL 알고리즘은 PPO이며, 그 뒤를 DDPG, SAC 등이 잇습니다. 물리 정보 유형으로는 물리 시뮬레이터, 시스템 모델, 배리어 인증서/물리 제약이 가장 흔하게 사용됩니다. 학습 아키텍처 중 PI reward와 safety filter는 주로 learning bias를 통해, physics embedded network는 inductive bias를 통해 물리를 통합합니다. 애플리케이션 도메인의 85% 가량이 제어 또는 정책 설계와 관련 있으며, 그 중 Miscellaneous control, Safe control and exploration, Dynamic control이 주를 이룹니다.
- RL 해결 과제: PIRL은 다음과 같은 RL 과제 해결에 기여합니다. Sample efficiency (시뮬레이터/모델 증강), Curse of dimensionality (물리 관련 저차원 표현 학습), Safety exploration (CBF/CLF 등 제어 이론 활용), Partial observability (상태 증강/융합), Under-defined reward function (물리 기반 보상 설계/증강).
미해결 과제 및 연구 방향 (Open Challenges and Research Directions)
- High Dimensional Spaces: 고차원 공간에서 물리적으로 관련된 정보성이 풍부한 저차원 표현을 학습하는 것이 여전히 과제입니다.
- Safety in Complex and Uncertain Environments: 복잡하고 불확실한 환경에서 model-agnostic하며 일반화 가능한 안전한 탐색 및 제어 접근 방식 개발이 필요합니다. 데이터 기반 모델 학습에 물리를 통합하는 일반화된 접근 방식도 중요합니다.
- Choice of physics prior: 문제에 적합한 물리 사전 지식을 선택하는 것은 어렵고 도메인별 전문 지식이 필요합니다. 새로운 물리적 태스크를 다룰 수 있는 포괄적인 프레임워크 구축이 필요합니다.
- Evaluation and bench-marking platform: PIRL 연구를 위한 포괄적인 벤치마킹 및 평가 환경이 부족하여 새로운 방법론의 비교 및 평가가 어렵습니다. 도메인별로 맞춤화된 환경에 의존하는 경향이 있습니다.
결론 (Conclusions): 본 논문은 PIRL 패러다임을 소개하고, 물리 사전 지식 유형 및 물리 정보 통합 방식(RL 방법)에 기반한 분류 체계를 제시합니다. 또한, 학습 아키텍처 및 bias에 따른 추가 분류를 통해 PIRL 구현을 더 잘 이해할 수 있도록 돕습니다. 최신 문헌을 검토하고, 물리 정보가 RL 파이프라인의 다양한 단계에 어떻게 통합되는지 분석하며, 사용된 벤치마크를 요약합니다. 마지막으로, 현재 PIRL 연구의 한계점과 미해결 과제를 논의하며 향후 연구 방향을 제시합니다. PIRL은 물리적 타당성, 정밀도, 데이터 효율성, 실제 환경 적용 가능성을 높여 RL 알고리즘을 향상시킬 잠재력이 있습니다.