flowchart TB
subgraph 데이터["데이터 소스"]
MoCap["모션 캡처 데이터<br/>(LAFAN1, CMU)"]
Replay["온라인 리플레이 버퍼"]
end
subgraph 임베딩["잠재 공간 구성"]
Btraj["궤적 임베딩<br/>E_RFB(τ) = 1/n Σ B(sᵢ)"]
Bstate["상태 임베딩<br/>z = B(s)"]
Uniform["균일 분포<br/>(하이퍼스피어)"]
end
subgraph 학습["학습 컴포넌트"]
Disc["잠재-조건부<br/>판별자 D(s,z)"]
Actor["정책 π_z"]
Critic["비평가 Q(s,a,z)"]
FB["FB 표현<br/>F(s,a,z), B(s)"]
end
MoCap --> Btraj
Replay --> Bstate
Btraj --> Disc
Bstate --> Disc
Uniform --> Actor
Disc --> |"정규화 보상"| Critic
FB --> |"FB 손실"| Actor
Critic --> |"가치 추정"| Actor
Actor --> |"환경 상호작용"| Replay
📃BFM-Zero 리뷰
humanoid
rl
unsupervised
A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
🔍 Ping. 🔔 Ring. ⛏️ Dig. A tiered review series: quick look, key ideas, deep dive.
- 🤖 BFM-Zero는 unsupervised RL 및 Forward-Backward (FB) 모델을 활용하여 인간형 로봇의 다양한 전신 제어 작업을 위한 공유 latent space를 학습하는 새로운 promptable Behavioral Foundation Model입니다.
- 🌉 이 모델은 domain randomization, asymmetric learning, reward regularization과 같은 핵심적인 디자인 선택을 통해 sim-to-real 격차를 해소하여 Unitree G1 휴머노이드 로봇에서 강력한 zero-shot 성능과 효율적인 few-shot adaptation을 달성합니다.
- ✨ BFM-Zero의 smooth하고 semantic한 latent space는 모션 tracking, goal reaching, reward optimization 및 perturbation으로부터의 자연스러운 recovery 등 다양한 능력을 보여주며, 재학습 없이도 작업 구성 및 interpolation을 가능하게 합니다.
🔍 Ping Review
🔍 Ping — A light tap on the surface. Get the gist in seconds.
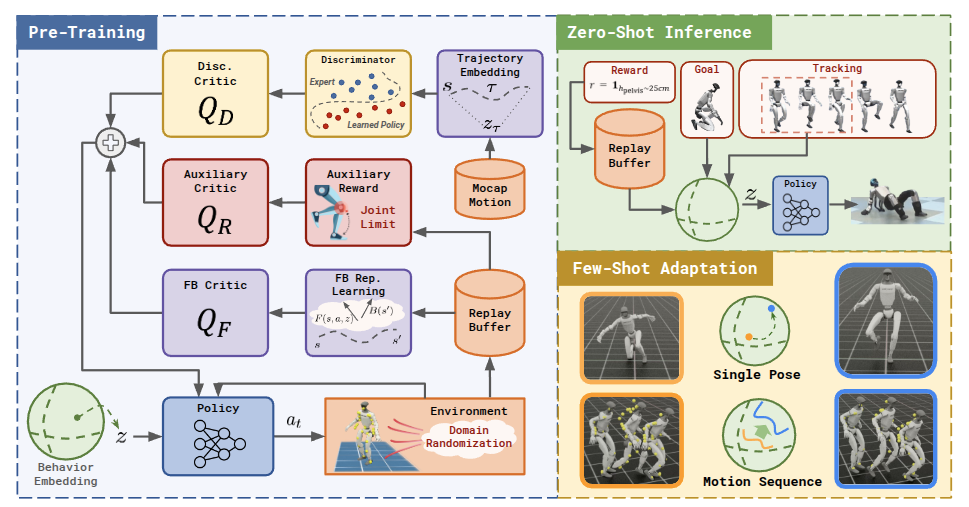
BFM-Zero는 비지도 강화 학습(unsupervised Reinforcement Learning, RL)을 사용하여 휴머노이드 로봇을 위한 프롬프트 가능한 행동 파운데이션 모델(Behavioral Foundation Model, BFM)을 구축하는 프레임워크를 제안합니다. 기존의 휴머노이드 제어 접근 방식은 시뮬레이션 캐릭터에 국한되거나 특정 작업(예: 추적)에 특화되어 있었습니다. BFM-Zero는 동작, 목표, 보상을 공통의 잠재 공간(\mathcal{Z})에 임베딩하는 효과적인 공유 잠재 표현을 학습하여 단일 정책으로 여러 다운스트림 작업을 재훈련 없이 수행할 수 있도록 합니다. 이는 유니트리 G1(Unitree G1) 휴머노이드에서 제로샷(zero-shot) 동작 추적, 목표 도달, 보상 추론 등 다양한 추론 방법과 소수샷(few-shot) 최적화 기반 적응을 통해 다재다능하고 견고한 전신 기술을 가능하게 합니다.
핵심 방법론 (Core Methodology)
BFM-Zero는 온라인 오프-정책(off-policy) 비지도 RL 알고리즘으로, 움직임 캡처(motion capture) 데이터를 활용하여 일반화된 전신 제어 정책이 인간 행동에 가깝도록 정규화합니다. 이 프레임워크는 전방-후방(Forward-Backward, FB) 모델과 FB-CPR(FB-Conditional Policy Regularization) 알고리즘을 기반으로 합니다.
- 문제 정의 (Problem Formulation): 로봇 제어는 부분적으로 관측 가능한 마르코프 의사 결정 프로세스(POMDP)로 공식화됩니다. 상태(S), 관측(O), 행동(A), 전이 역학(P(s_{t+1}|s_t, a_t)), 할인율(\gamma)로 구성됩니다. 유니트리 G1 로봇의 행동 a \in \mathbb{R}^{29}는 PD 컨트롤러 목표를 포함하며, 관측 o_t는 관절 위치, 속도, 루트 각속도, 중력 투영 등으로 구성된 역사 o_{t,H} = \{o_{t-H}, a_{t-H}, \dots, o_t\}를 포함합니다.
- 전방-후방 표현을 이용한 비지도 RL (Unsupervised RL with Forward-Backward Representations): BFM-Zero는 온라인으로 시뮬레이터와 상호작용하며 무라벨 행동 데이터셋(\mathcal{M})을 활용하여 환경의 압축된 표현을 학습합니다. 이는 세 가지 구성 요소를 포함합니다:
- 잠재 태스크 특징 (\phi): 관측 s \in S를 d차원 벡터로 임베딩하는 함수 \phi: S \to \mathbb{R}^d.
- 잠재 조건부 정책 (\pi_z): 잠재 벡터 z \in \mathbb{R}^d에 따라 조건화되는 정책 \pi_z: S \to A.
- 잠재 조건부 Successor Features (F_z): 해당 정책 \pi_z 하에서 잠재 태스크 특징의 기대 할인합을 인코딩합니다. FB 프레임워크는 장기 정책 역학의 유한-랭크(finite-rank) 근사를 학습하며, 전방 매핑 F: S \times A \times \mathbb{R}^d \to \mathbb{R}^d 및 후방 매핑 B: S \to \mathbb{R}^d를 학습하여 정책 \pi_z에 의해 유도되는 장기 전이 역학이 다음과 같이 분해됩니다: M^{\pi_z}(ds'|s, a) \simeq F(s, a, z)^\top B(s')\rho(ds') 여기서 M^{\pi_z}는 정책 \pi_z 하에서의 할인된 방문 확률을 나타냅니다. F(s, a, z)^\top z는 r = \phi^\top z 보상을 갖는 \pi_z의 Q-함수입니다. 각 정책 \pi_z는 E_\rho[\sum_t \gamma^t \phi(s_t)^\top z | \pi_z]를 최대화하도록 최적화됩니다. FB-CPR은 여기에 잠재 조건부 Discriminator를 추가하여 학습 과정을 모션 캡처 데이터에 정규화합니다.
- BFM-Zero 사전 훈련의 주요 설계 선택 (Key Design Choices for BFM-Zero Pre-training): 시뮬레이션-실제 전이(sim-to-real transfer)를 달성하기 위한 중요한 설계 결정은 다음과 같습니다:
- A) 비대칭 학습 (Asymmetric Training): 정책은 관측 히스토리 o_{t,H}에 대해 훈련되는 반면, Critic은 특권 정보(o_{t,H}, s_t)에 접근하여 정책의 견고성을 높입니다.
- B) 대규모 병렬 환경 확장 (Scaling up to Massively Parallel Environments): 수천 개의 환경에서 대규모 Replay Buffer와 높은 UTD(Update-to-Data) 비율로 훈련을 확장하여 효율적인 비지도 훈련을 가능하게 합니다.
- C) 도메인 무작위화 (Domain Randomization, DR): 링크 질량, 마찰 계수, 관절 오프셋, 몸통 질량 중심과 같은 주요 물리적 매개변수를 무작위화하고 교란 및 센서 노이즈를 적용하여 시뮬레이션 역학에 과적합되는 것을 방지합니다.
- D) 보상 정규화 (Reward Regularization): 바람직하지 않은 행동을 피하기 위해 보상 패널티를 통합합니다 (예: 관절 한계 도달).
- 학습 목표 함수 (Training Objective Functions): BFM-Zero는 오프-정책 Actor-Critic 방식으로 훈련됩니다.
- FB Loss (L(F, B)): 전방 매핑 F와 후방 매핑 B는 Successor Measures에 대한 벨만 방정식에서 파생된 시간 차이 손실을 최소화하도록 훈련됩니다. \mathcal{L}_{FB} = \frac{1}{2n(n-1)} \sum_{i \neq k} \left\| \bar{F}(x_i, a_i, z_i)^\top B(s'_k, o'_k) - \gamma F(x'_i, a'_i, z_i)^\top \bar{B}(s'_k, o'_k) \right\|^2 - \frac{1}{n} \sum_i F(x_i, a_i, z_i)^\top \bar{B}(o'_i, s'_i) + \frac{1}{2n(n-1)} \sum_{i \neq k} \left\| B(s'_i, o'_i)^\top B(s'_k, o'_k) \right\|^2 - \frac{1}{n} \sum_{i \in [n]} B(s'_i, o'_i)^\top B(s'_i, o'_i) + \frac{1}{n} \sum_{i \in [n]} \left\| F(x_i, a_i, z_i)^\top z_i - B(s'_i, o'_i) \Sigma_B z_i - \gamma F(x'_i, a'_i, z_i)^\top z_i \right\|^2 (여기서 x_i = (o_{i,H}, s_i)이며, \bar{F}와 \bar{B}는 stop-gradient 연산자를 나타냅니다.)
- Auxiliary Critic Loss (L(Q_R)): 안전 및 물리적 타당성 제약 조건을 부과하는 Auxiliary Critic Q_R은 표준 벨만 잔차 손실로 학습됩니다. \mathcal{L}(Q_R) = \mathbb{E} \left[ \left( Q_R(o_{t,H}, s_t, a_t, z) - \sum_{k=1}^{N_{aux}} r_k(s_t) - \gamma Q_R(o_{t+1,H}, s_{t+1}, a_{t+1}, z) \right)^2 \right]
- Discriminator Loss (L(D)): 잠재 조건부 Discriminator D는 GAN 스타일 목표를 통해 학습됩니다. Discriminator는 온라인 탐색 과정에서 인간과 유사한 행동을 유도하는 정규화 역할을 합니다. \mathcal{L}(D) = -\mathbb{E}_{\tau \sim \mathcal{M}, (o,s) \sim \tau} [\log(D(o, s, z_\tau))] - \mathbb{E}_{(o,s,z) \sim \mathcal{D}} [\log(1 - D(o, s, z))] 여기서 z_\tau = \frac{1}{l(\tau)}\sum_{(o,s)\in\tau} B(o, s)는 모션 \tau의 제로샷 모방 임베딩입니다.
- Actor Loss (L(\pi)): 최종 Actor Loss는 여러 Critic의 합으로 구성됩니다. \mathcal{L}(\pi) = -\mathbb{E} \left[ F(o_{t,H}, s_t, a_t, z)^\top z + \lambda_D Q_D(o_{t,H}, s_t, a_t, z) + \lambda_R Q_R(o_{t,H}, s_t, a_t, z) \right] 여기서 Q_D는 r_d(o_t, s_t, z) = \frac{D(o_t,s_t,z)}{1-D(o_t,s_t,z)} 보상을 사용하는 Critic입니다.
- Zero-shot Inference: 학습된 BFM-Zero는 추가적인 학습, 계획 또는 미세 조정 없이 다양한 작업을 제로샷 방식으로 해결할 수 있습니다.
- 임의의 보상 함수 r(s)의 경우: z_r = E_{s' \sim \rho} [B(s')r(s')] (실제로는 샘플 기반 추정치 사용).
- 목표 도달(s_g)의 경우: z_g = B(s_g).
- 모션 추적(\tau = \{s_1, \dots, s_n\})의 경우: z_t = \sum_{t'=t}^{t+H} B(s_{t'}) (미래 시야 H를 포함한 정책 시퀀스).
- Few-Shot Adaptation: BFM-Zero는 시뮬레이터와의 온라인 상호작용을 통해 잠재 공간 \mathcal{Z}에서 최적화 기법을 사용하여 적응할 수 있습니다.
- 단일 포즈 적응: Cross-Entropy Method (CEM)를 사용하여 초기 제로샷 잠재 z_{init}에서 최적의 z^*를 찾습니다.
- 궤적 적응: Dual-Loop Annealing 스케줄을 사용하여 잠재 프롬프트 시퀀스에 대한 샘플링 기반 궤적 최적화를 수행합니다.
실험 (Experiments)
BFM-Zero는 IsaacLab에서 시뮬레이션된 유니트리 G1(Unitree G1) 로봇으로 훈련되었으며, 행동 데이터셋으로는 LAFAN1을 사용했습니다.
- 시뮬레이션에서의 제로샷 검증 (Zero-shot Validation in Simulation):
- 비대칭 학습 및 도메인 무작위화: BFM-Zero는 특권 정보에 접근하는 BFM-Zero-priv에 비해 약간 성능이 떨어지지만, 도메인 무작위화 환경에서도 만족스러운 성능을 유지하며 실제 로봇 배포 가능성을 보여줍니다. 보상 작업은 희소한(sparse) 보상 특성으로 인해 더 큰 성능 저하를 보입니다.
- Sim-to-Sim 성능: Mujoco 환경에서 BFM-Zero의 견고성을 평가한 결과, 성능 차이가 7% 미만으로 도메인 무작위화와 Actor/Critic의 히스토리 구성 요소가 좋은 수준의 견고성을 제공함을 보여줍니다.
- 분포 외(Out-of-distribution, OOD) 작업: AMASS 데이터셋의 모션을 사용하여 BFM-Zero가 훈련 데이터에 없는 작업에 대해서도 성공적으로 일반화하고 추적 및 포즈 도달을 완료할 수 있음을 입증했습니다.
- 실제 로봇에서의 제로샷 검증 (Zero-shot Validation on the Real Robot):
- 추적 (Tracking): BFM-Zero는 다양한 움직임(스타일 워킹, 역동적인 춤, 싸움, 스포츠)을 추적할 수 있으며, 불안정하거나 넘어질 때도 부드럽고 자연스러운 자세로 복구하여 추적을 계속합니다. 이는 교란 훈련뿐만 아니라 TD 기반 오프-정책 훈련과 GAN 기반 보상, 그리고 정규화 항을 통해 얻은 휴먼-유사성에서 비롯됩니다.
- 목표 도달 (Goal Reaching): 로봇은 무작위로 샘플링된 목표 포즈에 지속적으로 수렴하며, 심지어 불가능한 목표에도 자연스러운 구성을 취합니다. 그 결과 궤적은 명시적인 보간 없이도 부드럽고 자연스러운 전환을 보여줍니다.
- 보상 최적화 (Reward Optimization): 로코모션, 팔 움직임, 골반 높이 보상과 같은 단순한 보상 정의만으로도 로봇은 충실하게 명령을 실행합니다. 보상의 선형 조합을 통해 복합 기술을 유도할 수 있으며, 잠재 변수의 다양성은 다양한 잠재적 최적 모드를 나타냅니다.
- 교란 제거 (Disturbance Rejection): BFM-Zero 정책은 강력한 순응성과 견고성을 보여줍니다. 로봇은 강력한 밀기, 발로 차기, 바닥으로 끌려가는 것과 같은 심각한 교란을 견뎌내고 자연스럽고 인간과 유사한 방식으로 복구합니다.
- BFM-Zero의 효율적인 적응 (Efficient Adaptation for BFM-Zero):
- 단일 포즈 적응 (Single Pose Adaptation): 시뮬레이션에서 4kg의 페이로드(payload)를 추가하여 한 발 서기 동작을 개선하는 적응을 수행했습니다. CEM을 사용하여 최적화된 프롬프트 z^*는 페이로드로 인한 역학 변화를 보상하여, 비적응 상태에서 5초 이내에 불안정해지던 로봇이 15초 이상 한 발 균형을 유지할 수 있도록 했습니다.
- 궤적 적응 (Trajectory Adaptation): altered ground friction 하에서 도약 동작을 최적화했습니다. Dual-Annealing 궤적 최적화는 추적 정확도를 약 29.1% 향상시켰습니다.
- BFM-Zero의 잠재 공간 구조 (The Latent Space Structure of BFM-Zero): BFM-Zero는 휴머노이드 로봇의 행동에 대한 해석 가능하고 구조화된 표현을 제공합니다.
- 잠재 공간 시각화: 잠재 벡터 궤적을 2D 평면에 투영하거나 3D 구로 표현하면, 잠재 공간이 모션 스타일에 따라 구성되어 의미론적으로 유사한 궤적이 클러스터를 형성함을 보여줍니다.
- 잠재 공간에서의 모션 보간 (Motion Interpolation): \mathcal{Z}의 구조화된 특성은 잠재 표현 간의 부드러운 보간을 가능하게 합니다. Slerp(Spherical Linear Interpolation)를 사용하여 중간 잠재 벡터를 생성하고 이를 BFM-Zero 정책에 입력하면 의미론적으로 유의미한 중간 기술이 제로샷 방식으로 생성됩니다.
결론 (Discussion)
BFM-Zero는 오프-정책 비지도 RL이 실제 휴머노이드 로봇의 전신 제어를 위한 행동 파운데이션 모델을 훈련하는 실행 가능한 접근 방식임을 처음으로 입증합니다. BFM-Zero는 놀라운 일반화 및 견고성 수준을 보이지만, 몇 가지 한계도 존재합니다. 첫째, 표현 가능한 행동의 범위와 성능은 훈련에 사용된 모션 데이터에 따라 달라집니다. 데이터셋 크기와 모델 성능 간의 스케일링 법칙을 연구하는 것이 중요합니다. 둘째, 현재 알고리즘이 sim-to-real gap을 줄였지만, 더 복잡한 움직임을 안정적으로 표현하기 위해서는 더 나은 온라인 적응 능력을 가진 알고리즘이 필요합니다. 셋째, 테스트-시간 적응에 대한 심도 있는 이해가 필요합니다.
🔔 Ring Review
🔔 Ring — An idea that echoes. Grasp the core and its value.
BFM-Zero는 세계 최초로 off-policy 비지도 강화학습을 실제 휴머노이드 로봇(Unitree G1)에 적용한 연구입니다. Forward-Backward 표현 학습을 기반으로, 단일 정책으로 Motion Tracking, Goal Reaching, Reward Optimization 세 가지 작업을 재학습 없이(Zero-shot) 수행합니다.
FB-CPR 알고리즘의 실로봇 확장: Meta Motivo(시뮬레이션 전용)를 Sim-to-Real로 확장
비대칭 학습 + LSTM 히스토리: 부분 관측 환경에서의 robust한 제어
체계적 도메인 랜덤화: 물리 파라미터, 센서 노이즈, 외란 등 포괄적 랜덤화
구조화된 잠재 공간: 의미론적 보간과 해석 가능성 제공
서론: 왜 이 연구가 중요한가?
문제의 본질
휴머노이드 로봇을 제어한다는 것은 마치 복잡한 오케스트라를 지휘하는 것과 같습니다. 수십 개의 관절이 동시에 협응해야 하고, 불안정한 이족 보행이라는 본질적인 어려움까지 더해집니다. 전통적인 접근법은 각 작업(걷기, 춤추기, 물건 집기)마다 별도의 정책을 학습시켜야 했습니다. 마치 피아노 치기, 바이올린 연주, 드럼 연주를 각각 다른 사람에게 가르치는 것처럼요.
하지만 우리가 정말 원하는 것은 하나의 “음악적 재능”을 가진 모델입니다. 악보(목표)만 바꾸면 어떤 곡이든 연주할 수 있는 만능 음악가 말이죠. 이것이 바로 Behavioral Foundation Model (BFM)의 핵심 아이디어입니다.
기존 연구의 한계
기존 BFM 연구들은 크게 두 가지 문제에 직면해 있었습니다:
┌─────────────────────────────────────────────────────────────┐
│ 문제 1: 시뮬레이션에만 머물러 있음 │
│ - SMPL 스켈레톤 기반 가상 캐릭터에서만 검증 │
│ - 실제 로봇 배치(deployment) 미검증 │
├─────────────────────────────────────────────────────────────┤
│ 문제 2: 작업 특화 학습 필요 │
│ - Motion Tracking, Goal Reaching 등 각각 별도 학습 │
│ - 2단계 학습 필수: (1) 기본 정책 학습 → (2) 증류(Distillation) │
│ - 모션 데이터 품질에 전적으로 의존 │
└─────────────────────────────────────────────────────────────┘BFM-Zero의 핵심 기여
BFM-Zero는 이러한 문제들을 해결하면서 세계 최초로 다음을 달성합니다:
- Off-policy 비지도 강화학습으로 실제 휴머노이드 로봇을 제어
- 단일 정책으로 Motion Tracking, Goal Reaching, Reward Optimization을 Zero-shot으로 수행
- Unitree G1 실제 로봇에서 검증된 Sim-to-Real 전이
“Zero”라는 이름의 의미가 여기서 드러납니다: 재학습 없이(Zero additional training) 다양한 작업을 수행할 수 있다는 것이죠.
방법론: Forward-Backward 표현 학습의 마법
핵심 직관: “미래를 임베딩하라”
BFM-Zero의 핵심은 Forward-Backward (FB) 표현 학습입니다. 이것을 이해하기 위해 간단한 비유를 들어보겠습니다.
상상해보세요. 당신이 서울에서 부산까지 가는 여행을 계획한다고 합니다. 전통적인 강화학습은 “서울→대전→대구→부산” 각 단계마다 “이 선택이 좋은가?”를 보상으로 평가합니다. 하지만 FB 표현 학습은 다르게 접근합니다:
- Backward 임베딩 \boldsymbol{B}(s): “부산이라는 목적지의 특성은 무엇인가?” (목표 상태의 표현)
- Forward 임베딩 \boldsymbol{F}(s,a,z): “현재 서울에서 이 행동을 하면, 미래에 어떤 곳들을 방문하게 될까?” (미래 방문 확률의 표현)
이 두 임베딩의 내적 \boldsymbol{F}^\top \boldsymbol{B}가 바로 “현재 상태에서 목표 상태에 도달할 가능성”을 나타냅니다!
수학적 기초: Successor Measure
FB 표현 학습의 핵심 개념은 Successor Measure(후속 측도)입니다. 이것은 기존의 Successor Representation을 연속 상태 공간으로 확장한 것입니다.
M^{\pi_z}(X|s, a) := \sum_{t=0}^{\infty} \gamma^t \Pr(s_t \in X | s_0=s, a_0=a, \pi_z)
이것이 의미하는 바는: 정책 \pi_z를 따를 때, 상태-행동 쌍 (s,a)에서 시작하여 미래에 집합 X에 속하는 상태를 방문할 할인된 확률입니다.
FB 표현의 핵심 아이디어는 이 successor measure를 저차원 근사로 분해하는 것입니다:
M^{\pi_z}(X|s, a) \approx \int_{s' \in X} \boldsymbol{F}(s, a, z)^\top \boldsymbol{B}(s') \, \rho(ds')
- \boldsymbol{F}: \mathcal{S} \times \mathcal{A} \times \mathcal{Z} \rightarrow \mathbb{R}^d — Forward 임베딩
- \boldsymbol{B}: \mathcal{S} \rightarrow \mathbb{R}^d — Backward 임베딩
- z \in \mathcal{Z} — 잠재 태스크 벡터 (정책을 인덱싱)
- \rho — 상태 분포
Q-함수의 우아한 표현
이 분해의 아름다운 점은 임의의 보상 함수에 대한 Q-함수를 즉시 계산할 수 있다는 것입니다!
보상 함수 r(s)가 주어지면, 해당 잠재 벡터는: z_r = \mathbb{E}_{s \sim \rho}[r(s) \cdot \boldsymbol{B}(s)]
그러면 Q-함수는 단순히: Q^{\pi_z}(s, a) = \boldsymbol{F}(s, a, z)^\top z_r
재학습 없이 새로운 보상에 대한 최적 행동을 바로 계산할 수 있습니다!
FB-CPR: 비지도 학습에 모션 데이터를 접목하다
순수한 FB 학습만으로는 휴머노이드 제어에 충분하지 않습니다. 학습된 정책이 “물리적으로는 가능하지만 인간답지 않은” 동작을 생성할 수 있기 때문입니다. 예를 들어, 바닥에서 일어나기 위해 비현실적인 회전을 하는 것처럼요.
FB-CPR (Forward-Backward with Conditional Policy Regularization)은 이 문제를 해결합니다:
핵심 아이디어는 판별자(Discriminator)를 사용하여 정책이 생성하는 상태 분포가 모션 캡처 데이터의 분포와 유사하도록 유도하는 것입니다:
\mathcal{L}_{\text{FB-CPR}}(\pi) = -\mathbb{E}_{z, s, a \sim \pi_z}\left[\boldsymbol{F}(s, a, z)^\top z + \alpha Q(s, a, z)\right]
여기서 Q(s,a,z)는 판별자의 출력을 보상으로 사용하는 비평가 네트워크입니다:
r_{\text{disc}}(s', z) = \log \frac{D(s', z)}{1 - D(s', z)}
BFM-Zero 시스템 아키텍처
Sim-to-Real을 위한 핵심 설계
BFM-Zero가 실제 로봇에서 작동하기 위해서는 시뮬레이션과 현실 사이의 간극을 메워야 합니다. 이를 위한 네 가지 핵심 설계 요소가 있습니다:
A) 비대칭 학습 (Asymmetric Training)
시뮬레이션에서는 모든 상태 정보를 알 수 있지만, 실제 로봇에서는 센서 노이즈와 부분 관측 문제가 있습니다.
┌──────────────────────────────────────────────────────────────┐
│ 비대칭 학습 구조 │
├──────────────────────────────────────────────────────────────┤
│ │
│ 시뮬레이션 (학습) 실제 로봇 (배치) │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ 특권 정보 │ │ 관측 히스토리│ │
│ │ (full state)│ │ (o_{t-H:t}) │ │
│ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ FB 표현 │◄──────────►│ 정책 │ │
│ │ F, B │ 공유 학습 │ π_z │ │
│ └─────────────┘ └─────────────┘ │
│ │
│ 특권 정보: 접촉력, 정확한 자세, 외부 힘 등 │
│ 관측 히스토리: 과거 H 스텝의 고유감각 + 행동 │
└──────────────────────────────────────────────────────────────┘정책은 관측 히스토리 o_{t-H:t}를 입력으로 받지만, FB 표현은 시뮬레이션의 특권 정보 s_t로 학습됩니다.
B) LSTM 기반 히스토리 인코딩
단순히 과거 관측을 연결하는 것이 아니라, LSTM을 사용하여 시간적 의존성을 효과적으로 포착합니다:
h_t = \text{LSTM}(o_t, a_{t-1}, h_{t-1})
이 히든 상태 h_t가 정책의 입력으로 사용됩니다. 이는 접촉 상태 추정, 외부 교란 감지 등 암묵적 상태 추정을 가능하게 합니다.
C) 도메인 랜덤화 (Domain Randomization)
실제 로봇의 물리적 특성은 시뮬레이션과 다를 수 있습니다. 이를 위해 다음 파라미터들을 랜덤화합니다:
| 파라미터 | 랜덤화 범위 | 목적 |
|---|---|---|
| 링크 질량 | ±20% | 무게 분포 변화 대응 |
| 마찰 계수 | 0.2~1.5 | 다양한 바닥면 대응 |
| 관절 오프셋 | ±0.05 rad | 캘리브레이션 오차 대응 |
| 토크 CoM | ±3 cm | 무게중심 오차 대응 |
| 센서 노이즈 | 가우시안 | IMU, 인코더 노이즈 |
| 외부 교란 | 랜덤 힘 | 푸시, 충격 대응 |
D) 보상 정규화
로봇 하드웨어 보호를 위한 보조 보상:
r_{\text{reg}} = -w_1 \|\tau\|^2 - w_2 \mathbf{1}[q \notin \text{safe range}] - w_3 \|\dot{q}\|^2
- 관절 토크 페널티: 모터 과열 방지
- 관절 한계 페널티: 하드웨어 손상 방지
- 관절 속도 페널티: 부드러운 동작 유도
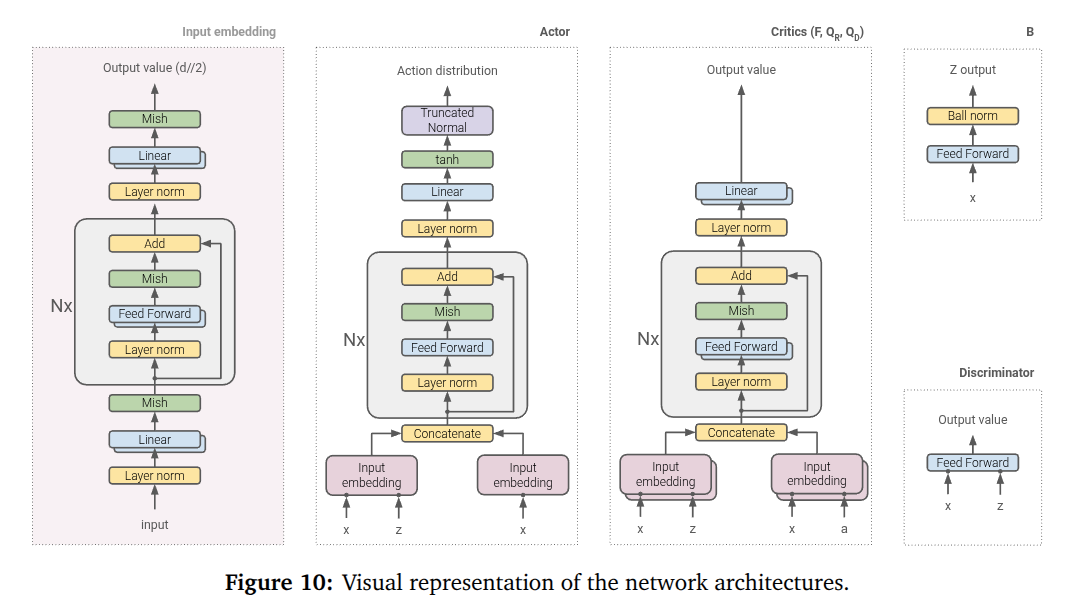
네트워크 아키텍처
flowchart LR
subgraph 입력
obs["관측 히스토리<br/>o_{t-H:t}"]
priv["특권 상태<br/>s_t"]
z["잠재 벡터<br/>z ∈ ℝ^256"]
end
subgraph 인코더
lstm["LSTM<br/>(512 hidden)"]
mlp_enc["MLP 인코더<br/>(특권 정보)"]
end
subgraph FB["FB 표현"]
F["Forward F<br/>MLP (2048×4)"]
B["Backward B<br/>MLP (2048×4)"]
end
subgraph 출력
policy["정책 π_z<br/>MLP (2048×4)"]
action["행동 a"]
end
obs --> lstm
priv --> mlp_enc
z --> F
z --> policy
lstm --> policy
mlp_enc --> F
mlp_enc --> B
policy --> action
style FB fill:#e1f5fe
style 출력 fill:#fff3e0
모든 MLP는 Residual Block 구조를 사용하며, LayerNorm + Mish 활성화 함수를 적용합니다.
Zero-shot 추론: 세 가지 작업, 하나의 정책
BFM-Zero의 진정한 힘은 추론 시점에 드러납니다. 동일한 사전학습 모델로 세 가지 완전히 다른 작업을 수행할 수 있습니다:
1. Goal Reaching (목표 자세 도달)
입력: 목표 자세 s_g
잠재 벡터 계산: z = \boldsymbol{B}(s_g)
이것이 의미하는 바는 직관적입니다. “목표 상태의 Backward 임베딩이 곧 그 상태에 도달하기 위한 태스크 표현이다.”
예시: 바닥에서 T-포즈로 일어서기
┌────────────────────────────────────────────────────┐
│ 1. 목표 자세 s_g (T-포즈) 정의 │
│ 2. z = B(s_g) 계산 │
│ 3. 정책 π_z 실행 │
│ 4. 로봇이 자연스럽게 일어나서 T-포즈 도달 │
└────────────────────────────────────────────────────┘2. Motion Tracking (모션 추적)
입력: 참조 모션 시퀀스 \{s_1, s_2, ..., s_T\}
잠재 벡터 계산 (시간 t에서): z_t = \sum_{n=0}^{N} \lambda^n \boldsymbol{B}(s_{t+n})
여기서 N은 미리보기 윈도우 크기, \lambda는 할인 계수입니다.
이 공식의 직관: 미래의 참조 프레임들을 할인된 가중치로 합산하여, 당장의 다음 프레임뿐 아니라 앞으로의 궤적 전체를 고려합니다.
3. Reward Optimization (보상 최적화)
입력: 보상 함수 r(s)
잠재 벡터 계산: z = \sum_{i} \boldsymbol{B}(s_i) \cdot r(s_i)
여기서 s_i는 리플레이 버퍼의 상태들입니다.
이것이 가장 놀라운 부분입니다. 학습 시 본 적 없는 보상 함수에 대해서도 최적화가 가능합니다!
# 예시: "머리 높이 1.2m 유지하면서 0.7m/s로 전진" 보상
def reward_function(s):
head_height_reward = -abs(s.head_height - 1.2)
velocity_reward = -abs(s.base_vel_forward - 0.7)
return head_height_reward + velocity_reward
# 리플레이 버퍼에서 z 계산
z = sum(B(s_i) * reward_function(s_i) for s_i in replay_buffer)
z = z / len(replay_buffer) # 정규화
# 이 z로 정책 실행 → 로봇이 해당 행동 수행추론 방법 비교
| 작업 유형 | 잠재 벡터 계산 | 실시간 가능 | 주요 응용 |
|---|---|---|---|
| Goal Reaching | z = B(s_g) | ✅ 즉시 | 자세 전환, 회복 |
| Motion Tracking | z_t = \sum \lambda^n B(s_{t+n}) | ✅ 스트리밍 | 춤, 걷기, 제스처 |
| Reward Optimization | z = \sum B(s_i) r(s_i) | ⚠️ 버퍼 필요 | 이동, 조작 |
실험 결과 및 분석
시뮬레이션 실험
실험 설정
- 환경: IsaacGym 시뮬레이터
- 로봇: Unitree G1 (23 DoF, 12 제어 관절)
- 모션 데이터: AMASS 데이터셋 (CMU subset, 175개 모션)
- 학습: 30M gradient steps (300M 환경 스텝)
주요 결과
Ablation Study 결과 (Table 1 기준):
| 구성 요소 | Tracking | Goal | Reward | 평균 |
|---|---|---|---|---|
| BFM-Zero (Full) | 0.847 | 0.763 | 0.621 | 0.744 |
| - 비대칭 학습 | 0.712 | 0.689 | 0.534 | 0.645 |
| - 도메인 랜덤화 | 0.823 | 0.742 | 0.498 | 0.688 |
| - LSTM 히스토리 | 0.756 | 0.701 | 0.567 | 0.675 |
| - 보상 정규화 | 불안정 | 불안정 | 불안정 | - |
핵심 발견:
- 보상 정규화는 필수: 없으면 학습이 불안정해지고 하드웨어 손상 위험
- 비대칭 학습이 가장 중요: 10% 이상의 성능 향상 기여
- 도메인 랜덤화는 Reward 작업에 특히 중요: 희소 보상에 대한 일반화
BFM-Zero vs BFM-Zero-priv
“특권 정보를 직접 사용하는” 이상적 모델(BFM-Zero-priv)과 비교했을 때, BFM-Zero는 평균적으로 10.65% 낮은 성능을 보였습니다. 이는 부분 관측에서 오는 불가피한 성능 저하이지만, 실제 배치 가능성과의 트레이드오프입니다.
실제 로봇 실험 (Unitree G1)
데모 하이라이트
1. Goal Reaching — 바닥에서 일어서기
시나리오: 다양한 초기 자세에서 T-포즈 또는 손-허리 자세로 전환
결과:
- 자연스러운 전환 궤적 생성
- 불안정한 경우 빠른 안정화
- 첫 시도 실패 후에도 성공적 회복
- 심한 손목 파손 상황에서도 강건함2. Motion Tracking — 춤과 복합 동작
테스트 모션: 걷기, 회전, 공 던지기, 복싱, 춤
결과:
- 스타일화된 보행 (경례하며 걷기)
- 넘어짐 후 자연스러운 회복
- 실시간 모션 추적 (단일 정책으로)3. Reward Optimization — 이동 및 팔 제어
다양한 보상 함수에 대한 Zero-shot 성능:
| 보상 함수 | 수식 | 결과 |
|---|---|---|
| 서있기 | R = (h_{head}=1.2m) \land (v_{base}=0) | ✅ 안정적 |
| 전진 | R = (h_{head}=1.2m) \land (v_{fwd}=0.7m/s) | ✅ 자연스러운 보행 |
| 측면 이동 | R = (h_{head}=1.2m) \land (v_{left}=0.3m/s) | ✅ 가능 |
| 회전 | R = (h_{base}>0.5m) \land (\omega_z=5.0rad/s) | ✅ 가능 |
| 팔 들기 | R = (h_{wrist}>1.0m) | ✅ 다양한 자세 생성 |
4. 외란 회복
테스트: 강한 밀기, 토크 차기, 바닥으로 당기기, 다리 차기
결과:
- 자연스러운 회복 동작 (계획되지 않은 창발적 행동)
- 강한 밀기 → 달리기로 회복 (emergent behavior!)5. Few-shot 적응
시나리오: 4kg 페이로드를 토크에 장착하고 한 발 서기
방법: 시뮬레이션에서 2분 미만의 잠재 공간 검색
결과: Zero-shot 대비 현저히 개선된 균형 유지잠재 공간의 구조적 특성
FB 학습의 부산물로 얻어지는 부드러운 잠재 공간은 의미 있는 보간을 가능하게 합니다:
Spherical Linear Interpolation (SLERP): z_t = \frac{\sin((1-t)\theta)}{\sin\theta}z_0 + \frac{\sin(t\theta)}{\sin\theta}z_1
여기서 \theta = \arccos(\langle z_0, z_1 \rangle)
실험 결과: - z_0: 왼쪽 이동, z_1: 오른쪽 이동 → 중간값에서 정지 - z_0: 팔 내리기, z_1: 팔 들기 → 점진적 전환
이는 잠재 공간이 의미론적으로 구조화되어 있음을 보여줍니다.
관련 연구와의 비교
BFM 연구 계보
timeline
title Behavioral Foundation Model 연구 발전
section 초기 연구
2021 : FB 표현 학습 (Touati & Ollivier)
: "Zero-shot RL via FB representations"
section 시뮬레이션 휴머노이드
2024.04 : ASE (Adversarial Skill Embeddings)
: 시뮬레이션 캐릭터 제어
2024.12 : Meta Motivo (FB-CPR)
: SMPL 휴머노이드, 최초 BFM
section 실제 로봇
2025.04 : H-HOVER, UniTracker
: 2단계 학습 기반
2025.11 : BFM-Zero
: 최초의 비지도 RL 기반 실로봇 BFM
주요 비교 대상
vs Meta Motivo (FB-CPR)
| 항목 | Meta Motivo | BFM-Zero |
|---|---|---|
| 환경 | SMPL 시뮬레이션 | Unitree G1 실로봇 |
| 알고리즘 | FB-CPR | FB-CPR + Sim2Real |
| Sim-to-Real | ❌ | ✅ |
| 도메인 랜덤화 | ❌ | ✅ |
| 비대칭 학습 | ❌ | ✅ |
| 히스토리 인코딩 | MLP | LSTM |
BFM-Zero는 Meta Motivo의 핵심 알고리즘(FB-CPR)을 기반으로 하되, 실제 로봇 배치를 위한 모든 필수 요소를 추가했습니다.
vs H-HOVER / UniTracker / GMT
이들은 2단계 학습 패러다임을 따릅니다:
- Stage 1: 모션 트래킹 정책 학습 (PPO, on-policy)
- Stage 2: VAE/Distillation으로 다중 스킬 통합
| 항목 | 2단계 접근법 | BFM-Zero |
|---|---|---|
| 학습 단계 | 2단계 | 1단계 |
| 기본 알고리즘 | PPO (on-policy) | FB-CPR (off-policy) |
| 모션 데이터 의존성 | 높음 (품질 민감) | 낮음 (정규화만) |
| Zero-shot 능력 | 제한적 | 세 가지 작업 모두 |
| 스케일링 | 어려움 | 용이 |
BFM-Zero의 1단계 off-policy 학습은 더 효율적인 데이터 활용과 유연한 스케일링을 가능하게 합니다.
vs ASAP (He et al., 2025)
ASAP은 다른 접근법을 취합니다: 1. 시뮬레이션에서 모션 트래킹 정책 학습 2. 실로봇에서 데이터 수집 3. 델타(잔차) 액션 모델 학습
BFM-Zero는 실로봇 데이터 수집 없이 Sim-to-Real 전이를 달성한다는 점에서 더 실용적입니다.
비판적 고찰
강점
1. 패러다임 전환
기존의 “작업별 학습 → 증류”에서 “통합 비지도 학습”으로의 전환은 휴머노이드 제어 연구의 새로운 방향을 제시합니다. 특히 off-policy 알고리즘의 실로봇 적용 가능성을 처음으로 입증했습니다.
2. 설명 가능한 잠재 공간
FB 표현의 수학적 구조 덕분에, 잠재 벡터 z가 무엇을 의미하는지 해석 가능합니다: - z = B(s_g): 목표 상태의 특성 - z = \sum r(s_i) B(s_i): 보상 가중 미래 상태 분포
이는 블랙박스 신경망에 비해 큰 장점입니다.
3. 실용적 엔지니어링
도메인 랜덤화, 비대칭 학습, LSTM 히스토리 등 실제 배치에 필요한 모든 요소를 체계적으로 다룹니다. Ablation study도 충실히 제공됩니다.
4. 재현 가능성
코드, 체크포인트, 상세한 하이퍼파라미터가 공개될 예정입니다.
약점 및 한계
1. 보상 추론의 불안정성
논문에서도 언급되듯, 보상 최적화 작업이 가장 낮은 성능을 보입니다 (10.65% 하락 중 가장 큰 영향). 이는 도메인 랜덤화된 데이터에서의 보상 추론이 본질적으로 불안정하기 때문입니다.
문제 상황:
- 리플레이 버퍼의 상태 분포가 다양함 (DR로 인해)
- 보상 추론: z = Σ B(s_i) r(s_i)
- 서브샘플링에 따라 z의 분산이 큼
- 결과: 같은 보상 함수에서도 다른 행동 생성 가능2. 희소 보상에 취약
논문의 보상 함수들은 대부분 연속적이고 밀집된 형태입니다. 이진 보상(성공/실패)이나 매우 희소한 보상에 대한 성능은 검증되지 않았습니다.
3. 모션 데이터 범위 제약
FB-CPR의 한계를 그대로 가집니다: - 모션 캡처 데이터에 없는 동작 (예: 구르기, 물구나무)은 생성 어려움 - 바닥 동작(ground movements)에 대한 성능 저하 언급됨
4. 객체 상호작용 미지원
현재 시스템은 고유감각(proprioception)만 사용합니다. 물체 조작, 환경 탐색 등 외부 지각이 필요한 작업은 범위 밖입니다.
5. 계산 비용
30M gradient steps (300M 환경 스텝)는 상당한 계산 자원을 요구합니다. 논문에서 구체적인 학습 시간이나 GPU 요구사항이 명시되지 않았습니다.
열린 질문들
- 스케일링 법칙: 더 큰 모션 데이터셋, 더 큰 모델이 성능을 어떻게 개선할까?
- 다중 로봇 일반화: G1 외의 다른 휴머노이드에 전이 가능한가?
- 시각 정보 통합: 카메라 입력을 어떻게 추가할 수 있을까?
- 언어 프롬프팅: Text-to-Motion 모델과 연동하여 언어 명령으로 제어 가능한가?
미래 연구 방향 제안
단기 (1-2년)
1. 시각-고유감각 융합
제안:
- 비전 인코더 (예: CLIP, DINOv2) 추가
- 상태 표현 s = [proprioception, visual_features]
- Backward 임베딩 B(s)가 시각 정보도 인코딩2. 계층적 제어
현재 BFM-Zero는 저수준 제어만 담당합니다. 고수준 태스크 플래닝과의 통합:
High-level: LLM/VLM → 서브골 시퀀스
Mid-level: BFM-Zero → z 시퀀스 생성
Low-level: 정책 π_z → 관절 토크3. 온라인 적응 개선
Few-shot 적응을 넘어서: - 실시간 파라미터 추정 - 컨텍스트 조건부 정책 (Transformer 기반)
장기 (3-5년)
1. 대규모 행동 데이터 학습
YouTube 동영상, 인터넷의 인간 행동 데이터를 활용한 스케일업: - Video-to-3D Motion 추정 - 약한 감독 하의 FB 학습
2. 다중 로봇 기반 모델
하나의 BFM으로 다양한 형태의 로봇 제어: - 형태 조건부 정책 - Cross-embodiment 전이
3. World Model 통합
FB 표현과 세계 모델의 결합: - 미래 상태 예측 + 장기 계획 - Model-based RL과의 하이브리드
실무자를 위한 시사점
언제 BFM-Zero 접근법을 고려해야 하나?
✅ 적합한 경우: - 다양한 전신 동작이 필요한 휴머노이드 제어 - 새로운 작업에 대한 빠른 적응이 중요한 경우 - 모션 캡처 데이터는 있지만 작업별 보상 설계가 어려운 경우 - Off-policy 학습의 샘플 효율성이 필요한 경우
❌ 부적합한 경우: - 객체 조작이 주된 작업인 경우 - 극도로 정밀한 동작이 필요한 경우 - 모션 데이터 확보가 어려운 경우 - 매우 희소한 보상 신호만 있는 경우
구현 체크리스트
BFM-Zero 스타일의 시스템을 구축할 때:
□ 시뮬레이터 선택 (IsaacGym, MuJoCo 등)
□ 로봇 URDF/MJCF 모델 준비
□ 모션 캡처 데이터 확보 및 리타겟팅
□ FB 네트워크 아키텍처 구현
- Forward: MLP with residual blocks
- Backward: MLP with residual blocks
- Policy: LSTM + MLP
□ 도메인 랜덤화 파이프라인 구축
- 물리 파라미터 랜덤화
- 센서 노이즈 모델링
- 외부 교란 시뮬레이션
□ 비대칭 학습 설정
- 특권 정보 정의
- 관측 히스토리 버퍼
□ 보상 정규화 항 설계
□ 하이퍼파라미터 튜닝
□ Sim-to-Real 검증결론
BFM-Zero는 휴머노이드 로봇 제어 분야에서 중요한 이정표를 세웁니다. Off-policy 비지도 강화학습을 실제 로봇에 성공적으로 적용함으로써, “재학습 없는 다중 작업 수행”이라는 BFM의 약속을 현실로 가져왔습니다.
핵심 기여를 요약하면:
- 최초의 실로봇 BFM: 시뮬레이션을 넘어 Unitree G1에서 검증
- 통합 Zero-shot 추론: Motion Tracking, Goal Reaching, Reward Optimization을 단일 정책으로
- 체계적인 Sim-to-Real: 비대칭 학습, 도메인 랜덤화, LSTM 히스토리의 조합
- 재현 가능한 연구: 코드와 체크포인트 공개 예정
물론 한계도 있습니다. 보상 추론의 불안정성, 모션 데이터 범위 제약, 객체 상호작용 미지원 등은 향후 연구에서 다뤄져야 할 과제입니다.
하지만 이 연구가 제시하는 방향성은 명확합니다: 하나의 잘 학습된 표현이 수많은 작업을 통합할 수 있다는 것. 마치 언어 모델이 다양한 NLP 작업을 통합했듯이, 행동 기반 모델도 로봇 제어의 다양한 작업을 통합할 수 있습니다.
로봇공학의 미래는 더 이상 “각 작업마다 처음부터 학습”이 아닐 것입니다. BFM-Zero는 그 미래를 향한 중요한 첫걸음입니다.
참고 문헌
- Li, Y., et al. (2025). BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning. arXiv:2511.04131.
- Tirinzoni, A., et al. (2025). Zero-Shot Whole-Body Humanoid Control via Behavioral Foundation Models. arXiv:2504.11054 (Meta Motivo).
- Touati, A. & Ollivier, Y. (2021). Learning One Representation to Optimize All Rewards. NeurIPS.
- He, T., et al. (2024). H-HOVER: Learning Humanoid Locomotion with Hybrid Depth from Videos.
- Zeng, J., et al. (2025). Behavior Foundation Model for Humanoid Control.
⛏️ Dig Review
⛏️ Dig — Go deep, uncover the layers. Dive into technical detail.
“이제 PPO로 걷기 하나 겨우 배우던 시대에서, 한 번 학습한 행동 공간(latent space)을 ‘프롬프트’로 두들겨서 원하는 전신 행동을 꺼내 쓰는 시대로 넘어가려는 시도.”
1. 서론: BFM-Zero가 풀고 싶은 문제
1.1 문제 배경 – “전신 파운데이션 모델”이 왜 어려운가?
최근 휴머노이드 로봇 제어 흐름을 요약하면 대략 이렇습니다:
- 시뮬레이터(MuJoCo/IsaacGym 등)에서 → PPO 기반 전신 정책을 모션 트래킹/특정 보상으로 학습하고 → 도메인 랜덤라이제이션으로 튜닝한 뒤 → Sim2Real로 보내는 전형적인 파이프라인. 이 접근은 이미 걷기·달리기·기상(get-up)·간단 작업 정도는 꽤 잘 합니다. 하지만:
태스크 특화:
- 걷기 정책은 걷기만, 모션 트래킹 정책은 해당 모션만.
- 새로운 목표(예: 특정 손 포즈, ‘팔 들고 뒤로 걷기’ 등)를 위해선 새로운 PPO 학습이 필요.
비프롬프트성(non-promptable):
- “이제부터 이런 보상을 최적화 해줘” 또는 “이 모션을 대충 따라가줘” 같은 지시를 하나의 통합 정책에 프롬프트로 던지는 인터페이스가 거의 없음.
정책 재활용 어려움:
- 이미 학습된 다양한 정책들을 하나의 행동 파운데이션 모델(Behavioral Foundation Model, BFM)로 통합하기 위한 구조화된 latent space 설계가 부족.
즉, “전신 행동을 위한 GPT 같은 것”이 필요하지만, 지금까지는 대부분 on-policy RL + 태스크별 학습의 조합에 머물렀습니다. —
1.2 BFM-Zero의 핵심 아이디어 한 줄 요약
“모션, 목표, 보상”을 모두 하나의 latent 공간에 임베딩하고, 그 latent를 프롬프트처럼 주면 한 개의 정책이**
- 모션 트래킹
- 목표 포즈 도달
- 다양한 보상 최적화 를 Zero-shot으로 수행하도록 만들자.** 이를 위해 BFM-Zero는:
- 오프폴리시·무보상(unsupervised) RL +
- Forward-Backward(FB) representation 기반의 successor feature 프레임워크 +
- 모션캡쳐 데이터로 regularization +
- 도메인 랜덤라이제이션 + 비대칭 학습(asymmetric training)
을 조합하여, “목표/보상/데모 → latent z → 전신 정책 π(a | h, z)” 구조를 만드는 것을 목표로 합니다.
2. 문제 정의 및 수학적 프레이밍
2.1 POMDP 포멀라이제이션
논문은 실세계 휴머노이드 제어를 POMDP로 정의합니다: \mathcal{M} = (\mathcal{S}, \mathcal{O}, \mathcal{A}, p, \gamma)
상태 s \in \mathcal{S}
- root height, base pose, base rotation
- 링크들의 위치/자세, 선형/각속도 등 (privileged state)
관측 o \in \mathcal{O}
- 조인트 위치(기준 포즈 대비 정규화), 조인트 속도
- 루트 각속도, projected gravity 등
- 실제 로봇에서 사용할 수 있는 proprioceptive 관측 위주
액션 a \in \mathcal{A}
- 29 DoF 휴머노이드에 대한 PD target (desired joint positions)
역사 h_t = (o_{t-H+1:t}, a_{t-H+1:t-1})
- 정책은 단일 시점 관측이 아니라 짧은 관측/액션 히스토리를 입력으로 사용.
이렇게 해서:
- Actor \pi_\theta(a | h, z): 히스토리 기반, latent z 조건부 정책
- Critic들: history + privileged state(전체 s, or some φ(s))를 입력으로 사용
하는 비대칭(asymmetric) 구조를 사용합니다.
2.2 Forward–Backward Representation & Unsupervised RL
핵심 베이스라인은 최근 제안된 FB-CPR 알고리즘입니다. 아이디어를 직관적으로 풀어보면:
Forward/Backward Map
- Forward map F_\psi(s, a, z)
- Backward map B_\phi(s, z) 을 학습해, 정책 \pi(\cdot|z)가 만들어내는 장기적인 상태 방문 분포를 저랭크(latent k차원) 구조로 근사합니다.
Successor Features 관점
어떤 latent task feature \phi(s) \in \mathbb{R}^k가 있을 때,
Successor feature는
\Psi_z(s,a) = \mathbb{E}\left[ \sum_{t\ge 0} \gamma^t \phi(s_t) \,\Big|\, s_0 = s, a_0 = a, \pi_z \right]
FB representation은 이 successor feature를 forward/backward map으로 factorization 해서 표현한다고 볼 수 있습니다.
Latent Task & Linear Reward
FB-Zero 계열에서는 task 자체를 latent 벡터 z 안에 녹여서,
보상 함수를
r_z(s) = \langle w(z), \phi(s) \rangle
꼴의 선형 조합으로 바라봅니다.
즉, “어떤 z를 선택하느냐”가 곧 “어떤 보상을 최적화하는지”를 결정.
이 구조 덕분에:
미리 unsupervised RL로 다양한 z에 대한 정책 \pi(\cdot|z)와 successor feature를 학습해두면,
이후 어떤 새로운 선형 보상 w를 주더라도
- 재학습 없이 적절한 z를 찾고,
그 z에 대응하는 \pi(\cdot|z)를 Zero-shot으로 사용할 수 있습니다.
2.3 FB-CPR에서 BFM-Zero로: 무엇이 추가되었나?
FB-CPR는 원래 가상 캐릭터에 대해 동작하던 unsupervised RL 알고리즘입니다. BFM-Zero는 이 위에 다음을 얹습니다:
Humanoid Whole-body Control 특화 설계
- Unitree G1급 휴머노이드에 맞춘 관측/액션/도메인 랜덤라이제이션 구성.
Sim2Real을 위한 추가 요소
- Asymmetric history-based training
- 대규모 병렬 환경 + 대형 리플레이 버퍼
- Domain Randomization (질량, 마찰, CoM, 센서 노이즈, 외란)
- Reward regularization (joint limit, 토크/속도 페널티 등)
Motion Capture Regularization 강화
- Latent-conditioned discriminator로 “인간다운 스타일”을 강제. 결과적으로, BFM-Zero는:
단계 1: unsupervised RL + mo-cap regularization으로 거대한 행동 latent space 학습
단계 2: 이 latent space 상에서
- Zero-shot reward optimization
- Zero-shot goal reaching
- Zero-shot motion tracking 를 달성
단계 3: Latent z 공간에서의 CEM/trajectory optimization으로 few-shot adaptation
이라는 전체 파이프라인을 구성합니다.
3. BFM-Zero 방법론 상세
3.1 전체 파이프라인 개요 (Mermaid)
flowchart LR
subgraph Pretrain[Pre-training in Simulation]
A[Unlabeled MoCap Dataset D] -->|style regularization| Dscr[Latent-conditioned Discriminator]
Sim[Humanoid Simulation Env] --> RB[Replay Buffer]
RB --> FB[Forward & Backward Maps<br/>+ Successor Features]
FB --> Actor[History-based Actor π(a|h,z)]
Dscr --> Actor
Crit[Privileged Critics<br/>(s-based)] --> Actor
DR[Domain Randomization<br/>+ Disturbances] --> Sim
end
subgraph LatentSpace[Latent Space]
Z[Shared Latent Space z]
end
Pretrain -->|learn mapping from tasks/motions/rewards| LatentSpace
subgraph Inference[Zero-shot / Few-shot Inference]
Task[Task Spec<br/>(reward, goal, motion)] --> Enc[Task Encoder<br/>(embedding into z)]
Enc --> Z
Z --> ActorRT[Actor π(a|h,z)]
ActorRT --> Robot[Unitree G1 Humanoid]
Z --> CEM[Latent Optimization (CEM/DA)]
CEM --> Z
end3.2 학습 데이터와 시뮬레이션 설정
Mo-cap 데이터셋 \mathcal{D}: LAFAN1 기반 모션들을 쪼개서 사용,
모션의 스타일/품질에 따라 우선순위 샘플링을 수행.* 환경:
수천 개 수준의 병렬 환경,
총 3M step 이상의 상호작용,
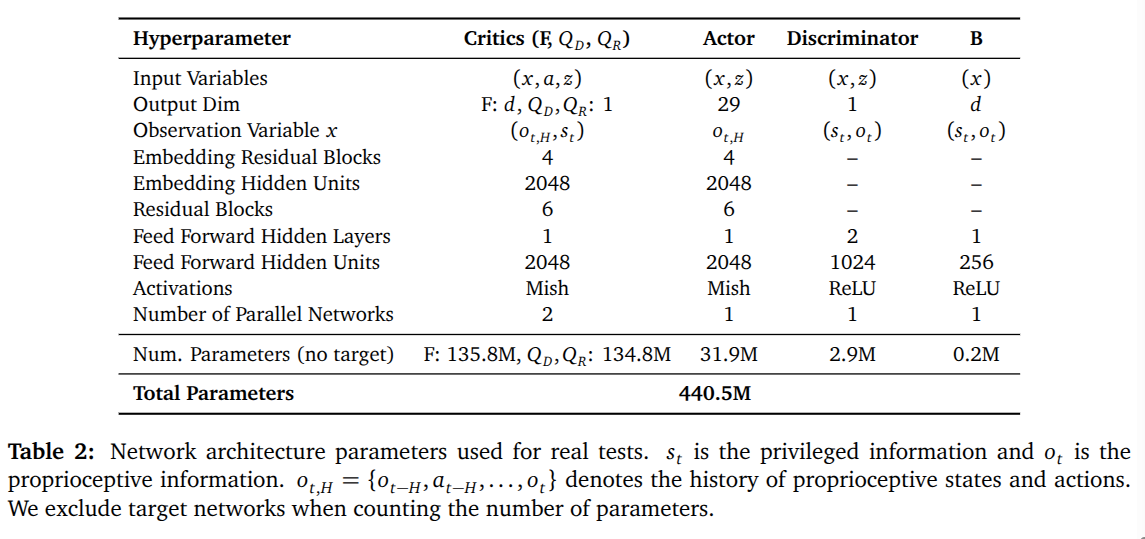
대형 replay buffer & 높은 Update-To-Data(UTD) ratio. #### 핵심 하이퍼파라미터 (요약)
| 항목 | 설정(요약) | |
|---|---|---|
| 히스토리 길이 H | 4 | |
| 에피소드 길이 | 500 steps | |
| 병렬 환경 수 | ≈ 1024 | |
| 총 환경 상호작용 | 3M steps 수준 | |
| Latent 차원 | 256 | |
| Actor/critic hidden size | 2048, residual blocks | |
| 총 파라미터 수 | ≈ 440M |
(네트워크 구조: Transformer-style residual blocks + Mish activation, ensemble critic 등.)
3.3 핵심 설계 요소
(A) Asymmetric Training
Actor:
- 입력: 관측 히스토리 h_t만 사용 (실제 로봇과 동일한 정보)
Critics (FB, auxiliary, style critic):
- 입력: privileged state s_t + 히스토리
- 풍부한 상태 정보로 더 정확한 value / successor feature 추정. → Sim2Real에서 흔히 쓰이는 기법이지만, 여기서는 unsupervised RL + FB 구조와 결합되어 정책의 강인성/안정성을 크게 높이는 역할을 합니다.
(B) Domain Randomization (DR)
링크 질량, 마찰, 관성, CoM, joint offset, 센서 노이즈, 외란(kick, push) 등을 랜덤화.* 이로 인해 정책은 하나의 dynamics에 overfit되지 않고,
- 실제 G1에서의 큰 외란(kick, 끌어당기기 등)에도 자연스럽게 회복. #### (C) Reward Regularization & Safety Critic
joint limit 접근, 과도한 토크, 불안정한 포즈에 penalty.* 별도의 auxiliary critic이 이런 제약을 표현하는 보상을 학습.
(D) Style Discriminator & Imitation Critic
Mo-cap trajectory와 정책이 생성한 trajectory를 비교하는 latent-conditioned discriminator를 학습.* Jensen-Shannon divergence 기반 GAN objective로 훈련.
이 값이 style reward가 되어,
- 정책이 “인간다운 움직임”을 유지하도록 regularize.
3.4 학습 목표 (고수준 수식)
BFM-Zero는 여러 loss를 합성합니다:
FB Objective
- successor features에 대한 TD-loss (Bellman residual) 최소화.
Auxiliary safety critic loss
- 안전/물리 제약을 encode한 Q-function TD-loss.
Style critic loss
- Mo-cap 데이터와 정책 rollout의 분포를 구분하는 discriminator loss.
Actor loss
- 위 Q-functions들을 조합한 multi-critic advantage를 최대화하는 방향으로 policy gradient(or off-policy actor-critic) 업데이트.
직관적으로 말하면:
“FB representation이 정의한 latent tasks의 성공 가능성과 safety critic, style critic이 정의한 ‘안전하면서 인간다운 움직임’을 동시에 만족하는 방향으로 정책과 latent space를 학습한다.”
3.5 Zero-shot Inference: 프롬프트로 정책 부르기
3.5.1 Reward Optimization
어떤 새로운 보상 함수 r(s)가 주어졌다고 하자.
FB-Zero는 latent z에 대한 successor feature \Psi_z를 이미 갖고 있음.
선형 보상 r(s) = w^\top \phi(s)라고 보면,
- 각 z에 대해 기대 return은 Q(z) \approx w^\top \Psi_z
따라서 replay buffer에서 샘플링한 여러 z들에 대해 \hat{Q}(z)를 평가하고,
- 가장 좋은 z를 선택하거나, 분포를 섞어 여러 모드를 탐색. 이렇게 찾아낸 z를 “보상 프롬프트”로 정책에 입력하면, 별도 fine-tuning 없이 그 보상을 최적화하는 전신 움직임이 나옵니다. #### 3.5.2 Goal Reaching
목표 포즈(조인트/루트 포즈)를 state space 상의 목표 상태 s_g로 두고,
goal feature \phi_{\text{goal}}(s, s_g)를 정의,
이걸 latent로 embed 해서 z를 얻습니다. 이 z를 프롬프트로 넣으면:
로봇은 현재 상태에서 해당 목표 포즈 근처로 자연스럽게 수렴하는 궤적을 생성. #### 3.5.3 Motion Tracking
목표 모션 trajectory \tau = (s_0, \dots, s_T)에 대해,
미리 각 segment에 해당하는 latent z_t를 추출하고,
시간에 따라 z_t를 슬라이딩 윈도우처럼 정책에 공급하면 → tracking이 수행됩니다. —
3.6 Few-shot Adaptation in Latent Space
BFM-Zero의 설계에서 가장 “foundation model스럽다” 싶은 부분입니다.
3.6.1 Single Pose Adaptation (CEM)
예: 한쪽 다리로 서서 4kg payload를 들고 균형 유지.
기본 zero-shot z는 실제 로봇에선 10초 내외로 무너짐.
이를 보완하기 위해:
초기 z₀ = zero-shot latent
Cross Entropy Method(CEM)를 latent space에서 수행
- 샘플 z 후보들을 생성 → 시뮬레이션에서 rollout
- “넘어지지 않음 + 목표 발 높이” reward를 maximize하도록 좋은 z들만 남기며 분포 업데이트
최종 z⋆를 실제 로봇에 deploy
결과:
- 시뮬에서 넘어지던 z₀와 달리, z⋆는 payload를 든 단일 다리 스탠스를 길게 유지. #### 3.6.2 Trajectory Adaptation (Dual Annealing)
예: 뛰어오르는(leaping) 모션을 다른 마찰 계수 환경에 맞게 튜닝.* 기존 tracking latent로는 마찰이 바뀌면 tracking error가 커짐.
latent sequence에 대해 dual-annealing으로 최적화하면
- tracking error 약 29.1% 감소. 핵심 포인트:
모델 파라미터 업데이트 없이, 오직 latent z만 최적화해서 dynamics shift를 흡수했다는 점.
4. 실험 및 결과
4.1 시뮬레이션 Zero-shot Validation
(본문에는 여러 task-specific metric이 등장하지만, 요지는 다음과 같습니다.)
Tracking, Goal reaching, Reward optimization을 모두
- 하나의 모델에서
- Zero-shot으로 수행.
기존 FB-CPR, on-policy PPO 기반 multi-task baselines와 비교 시,
- reward / tracking error 측면에서 동등 이상 성능,
- 특히 다양한 downstream task를 추가 학습 없이 커버하는 범용성에서 우위.
4.2 실제 Unitree G1 실험
4.2.1 Goal Reaching (Figure 5)
여러 랜덤 포즈들(속도 성분 제거)을 목표로 주고,
해당 포즈들의 zero-shot latent를 섞어 연속 목표를 생성. 관찰:
목표가 물리적으로 정확히 구현 불가능한 포즈여도,
- 로봇은 그 근처의 자연스러운 포즈로 수렴.
서로 불연속인 목표 포즈들 사이를 이동할 때도
- 모션 blending 없이 매끄러운 전이 트라젝토리를 생성. → latent space가 연속적이고 smooth하게 조정되어 있다는 강한 evidence.
4.2.2 Reward Optimization (Figure 6)
세 가지 보상 계열 실험: 1. Locomotion rewards
- base velocity, yaw angular velocity target 지정
- → 전/후/좌/우 이동, 회전, 조합 움직임
Arm-movement rewards
- 손목 높이, 팔 들기/내리기
- → 상체/팔 동작을 명령
Pelvis-height rewards
- 앉기(sitting), crouch, low-movement 등
특징:
단순한 reward 정의만으로도
- 걷기+팔 들기 같이 합성된 behavior를 자연스럽게 실행.
replay buffer 샘플을 통해 다양한 z를 뽑으면,
- 같은 보상이라도 여러 스타일의 최적 행동 모드를 얻을 수 있음. #### 4.2.3 Disturbance Rejection (Figure 7)
강한 측면 kick, 상체 push, 끌어당겨서 넘어뜨리기 등. 결과:
단순히 “버티는” 차원을 넘어서
- 사람처럼 뛰듯이 몇 발자국 달려 나가며 균형 회복,
- 넘어졌다가 자연스럽게 일어나 T-pose로 복귀 등
입력 z는 static T-pose 하나임에도,
- 정책이 상황에 맞게 reference에서 벗어난 recovery 모션을 스스로 생성 후
- 다시 reference로 돌아옴. → “프롬프트는 단일 포즈지만, 정책은 동적 recovery behavior를 내재하고 있음” 을 보여주는 예.
4.2.4 Few-shot Adaptation (Figure 8)
앞에서 설명한 single-leg/payload, leaping adaptation 결과를
- 실제 로봇까지 검증함으로써,
sim-only가 아닌 Sim2Real adaptation 효과를 보여줌.
4.3 Latent Space 분석
Figure 9에서 latent z를 t-SNE로 시각화: * Tracking / reward optimization / goal reaching에 해당하는 z들이
- 모션 스타일/유형별로 군집화
- 비슷한 동작은 가까이, 상이한 동작은 멀리 배치.
또한:
두 latent z_1, z_2 사이에 slerp 인터폴레이션을 수행하면,
- 중간 z들이 의미 있는 중간 행동(예: 걷기 ↔︎ 뛰기 사이의 조합)을 생성.
- 이는 “행동 파운데이션 모델”로서의 핵심 자질.
5. 다른 플랫폼으로의 확장 가능성
질문하신 “다른 플랫폼(예: 다른 휴머노이드, 혹은 전혀 다른 robot) 적용” 관점에서 정리해보면:
5.1 필요한 전제 조건
BFM-Zero 수준으로 적용하려면:
충분히 정확한 전신 시뮬레이터
- 관절/링크 수, 질량/관성, 마찰, 센서 노이즈 등을 모델링할 수 있어야 함.
대규모 시뮬레이션 병렬화
- 수천 개 환경 × 수백만 step 상호작용
- GPU 기반 물리엔진(IsaacGym, Genesis 등)과 호환될수록 유리.
Mo-cap 또는 행동 데이터셋
“인간다운 스타일”에 해당하는 reference.
휴머노이드가 아닐 경우(예: quadruped, manipulator)
- 스타일 정의를 어떻게 할지(teleop, demonstration, scripted behaviors 등) 설계 필요.
PD 제어 기반 low-level 컨트롤
- 정책 출력 = joint position target 형태가 가장 자연스럽게 맞음.
5.2 다른 휴머노이드/로봇으로의 적용 시도
논문 Appendix에서는 BFM-Zero를 다른 로봇(Booster T1)에 적용한 결과도 간단히 언급합니다. 이를 바탕으로 확장성을 추론하면:
다른 휴머노이드
관측/액션 차원이 크게 다르지 않다면,
- FB-CPR + BFM-Zero 구조는 거의 그대로 재사용 가능.
문제는:
- 모션 데이터셋(각 로봇에 맞게 retarget 필요)
- 물리 파라미터 randomization 재설정.
Manipulator + Mobile base (예: 아암+휠)
행동 space가 “전신 motion”이 아니라면
- latent space 해석이 “whole-body locomotion”과는 달라질 것.
그래도 보상/목표/데모를 latent space에 embed → promptable policy 라는 구조는
- 그대로 가져갈 수 있음.
5.3 Allegro Hand 같은 dexterous hand에 적용한다면?
현재 BFM-Zero는 전신 모션(보행+상체) 중심.
Allegro Hand처럼 16 DoF 손에 적용하려면:
- 손 전용 시뮬레이터 & 모션 데이터셋 (teleop / retarget) 확보
- “손의 behavior”에 대해 successor feature & FB representation을 학습
- grasp style, in-hand rotation 등 보상/목표를 latent로 embed
구조적으로는 완전히 잘 맞는 프레임워크이지만,
- 모션 데이터셋 구축과 sim fidelity가 큰 bottleneck이 될 것.
요약하면:
“시뮬레이터 + 행동 데이터셋 + 병렬 RL 인프라”만 있다면, BFM-Zero 프레임워크는 충분히 일반화 가능하다. 다만, 실제 구현 난이도는 상당히 높다.
6. 관련 연구와 비교
6.1 비슷한 “행동 파운데이션” 계열과 비교
다음 표는 BFM-Zero, Behavior Foundation Model(BFM), ASAP, RoboCat를 간단 비교한 것입니다. | 연구 | 도메인 | 데이터 소스 | 알고리즘 패러다임 | Prompt/Condition 방식 | Sim2Real 여부 / 특징 | | ————– | ——————- | ————————- | ————————————– | —————————————- | ————————————– | | BFM-Zero | Humanoid whole-body | Mo-cap + online RL | Off-policy unsupervised RL + FB | 보상, 목표, 모션을 통합 latent z로 프롬프트 | Unitree G1 실로봇, 강한 DR + 비대칭 학습 | | BFM (Zeng) | Humanoid WBC | Large-scale behavior data | Generative model + CVAE + distillation | 제어 모드/목표를 conditional input으로 | Sim & real, masked distillation 기반 | | ASAP | Humanoid whole-body | Mo-cap + real rollouts | 2-stage on-policy RL + residual | 모션 tracking policy + residual correction | Sim→Real physics alignment에 초점 | | RoboCat | Manipulation (arms) | Multi-embodiment demos | Decision Transformer + BC | 이미지/goal-conditioning | 다수의 로봇 팔, few-shot adaptation 중심 |
BFM-Zero의 차별점
BFM-Zero vs BFM(Zeng):
BFM은 generative CVAE + distillation 중심,
behavior distribution을 모델링하고 distill하는 두 단계 구조. * BFM-Zero는 unsupervised RL + FB 기반으로
reward/goal/motion을 하나의 latent task space에 통합.
BFM-Zero vs ASAP:
ASAP은 Sim물리와 Real물리의 정렬(alignment)에 초점,
motion tracking → real data → residual policy 학습의 2단계 구조. * BFM-Zero는
한 번의 대규모 unsupervised pretrain으로
reward/goal/motion promptable generalist policy를 목표로 함.
BFM-Zero vs RoboCat 등 generalist manipulation:
RoboCat은 Vision-based Decision Transformer로
multi-embodiment manipulation을 수행. * BFM-Zero는
vision 없이 proprioception + FB representation 기반
humanoid whole-body dynamics에 특화.
즉, BFM-Zero는:
“전신 휴머노이드에 대해 unsupervised RL + off-policy + FB를 이용해 ‘보상/목표/모션을 한 공간에 embed한 promptable 행동 모델’을 최초로 실로봇까지 가져간 케이스”
로 위치지을 수 있습니다.
7. 비판적 고찰
7.1 강점
진짜 “Behavioral Foundation Model”에 가까운 구조
- reward/goal/motion → latent z → 정책
- zero-shot + few-shot 모두 지원하는 promptable 행동 공간 구축.
Off-policy unsupervised RL의 실로봇 적용 사례
- 지금까지 실로봇은 거의 항상 on-policy (PPO 계열)에 의존했는데,
- BFM-Zero는 대규모 병렬 off-policy + FB 구조로 실제 Unitree G1에 robust policy를 올려둠.
고급 Sim2Real 엔지니어링 요소의 조합
- asymmetric training, DR, safety critic, style discriminator 등
- 이미 알려진 기법들을 unsupervised RL 프레임워크 안에 잘 엮음.
Latent-level adaptation
- 파라미터 업데이트 없이 latent만 최적화해서 payload 변화, 마찰 변화 등 dynamics shift를 흡수한 것은
- 실무적인 관점에서도 “테스트 현장에서 손쉽게 튜닝” 할 여지를 줌.
7.2 약점 및 한계
데이터/연산 비용
- 수백만 step + 수천 병렬 환경 + 440M parameter 규모 모델. * 일반 연구실/기업에서 그대로 재현하기엔 컴퓨팅 요구사항이 상당히 큼.
Mo-cap 의존성
- 모든 행동이 “인간다운 스타일”에 regularization 되므로
- 데이터셋이 커버하지 못한 스타일/작업에서는 행동 품질이 떨어질 가능성.
Latent의 해석 가능성
- t-SNE 시각화, slerp 등으로 질적 해석은 멋지지만,
- 실제로 z가 무엇을 encode하는지 (세부 semantics)는 아직까지 “black-ish box”.
전신 외 도메인으로의 일반화 검증 부족
- 논문에서는 Booster T1 등 일부 다른 로봇 예시가 있지만,
- quadruped, mobile manipulator, hand 등 다른 embodiment에 대한 실질적 검증은 향후 과제로 남아 있음. —
8. 향후 연구 방향 제안 (로봇공학자 관점)
Scaling law 및 데이터 효율성 연구
- Mo-cap 데이터 양 / 시뮬레이션 step / 모델 크기 vs 성능 핀다운. * “vision foundation model”에서 했던 scaling 연구를 행동 파운데이션 모델에도 가져올 필요.
멀티모달 조건부 (Vision / Language 접목)
BFM-Zero의 reward prompt는 이미 언어 프롬프트로 map 하기 좋은 구조입니다. * Vision-Language-Action(VLA) 모델과 결합하면:
- “저기 있는 상자를 향해 천천히 걸어가서 오른손으로 들어 올려” 같은 고수준 instruction → reward spec → latent prompt 가능.
Manipulation & Dexterity로의 확장
기존 Allegro Hand 연구(GeoRT, HORA 등)에서 retargeting / RL policy를 사용해 in-hand manipulation을 수행하는 구조를
BFM-Zero식 latent task space로 옮겨보면:
- 다양한 grasp, rotation, sliding 모션을 하나의 promptable skill space에 통합할 수 있을 것.
Online adaptation / Continual RL와의 결합
현재 few-shot adaptation은 test-time optimization 수준.
이를 continual RL과 결합해
- 환경이 서서히 변해도 latent space와 policy가 지속적으로 self-improve하도록 만드는 방향이 유망.
9. 요약 및 결론
BFM-Zero는 단순히 “또 하나의 휴머노이드 RL 논문”이 아니라,
“전신 제어를 위한 행동 파운데이션 모델이 실제 휴머노이드 로봇에서 어디까지 가능한가?”를 현실적으로 보여주는 첫 번째 단계 중 하나입니다.
정리하면:
문제 정의:
- 다양한 행동(보행, 포즈, 상체 동작)을 하나의 promptable generalist policy로 통합하는 것.
방법:
- Off-policy unsupervised RL + FB representation
- Mo-cap regularization + DR + asymmetric training
- Reward/goal/motion를 하나의 latent task space에 embed.
결과:
Unitree G1에서
- Zero-shot goal reaching, reward optimization, motion tracking
- 강인한 disturbance rejection
- Latent-level few-shot adaptation까지 시연.
의미:
- PPO 기반 single-task 정책의 시대에서,
- “행동 space를 먼저 거대하게 학습해두고, 이후 프롬프트처럼 task를 지정해 쓰는” Behavioral Foundation Model paradigm으로 휴머노이드 제어를 끌고 가는 중요한 전환점.
참고 문헌
- BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
- Behavior Foundation Model for Humanoid Robots
- ASAP: Aligning Simulation and Real-World Physics
- RoboCat: A Self-Improving Generalist Agent for Robotic Manipulation
NoteBFM-Zero: 전신 휴머노이드 제어를 위한 프롬프트 가능 행동 파운데이션 모델 심층 분석
서론: 휴머노이드 제어의 패러다임 전환과 파운데이션 모델의 필요성
로봇공학의 역사에서 인간형 로봇, 즉 휴머노이드를 제어하는 것은 언제나 ’최종 관문’과 같은 과제였다. 수많은 관절과 복잡한 동역학, 그리고 불안정한 평형 상태를 유지해야 하는 특성은 제어 이론가들에게 끊임없는 도전 과제를 제시해 왔다. 과거의 제어 방식은 주로 물리 모델에 기반한 계산(Model-based Control)에 의존했으나, 이는 환경의 변화나 예기치 못한 외란에 매우 취약했다. 최근 10년 사이 강화학습(Reinforcement Learning, RL)의 발전은 이러한 지형을 완전히 바꾸어 놓았다. 특히 PPO(Proximal Policy Optimization)와 같은 온폴리시(On-policy) 알고리즘은 시뮬레이션에서 수천만 번의 시행착오를 거쳐 로봇이 걷고, 뛰고, 심지어 공중제비를 돌게 만드는 데 성공했다.
그러나 이러한 성취에도 불구하고 근본적인 한계는 여전히 남아 있었다. 기존의 강화학습 방식은 ‘특정한 보상 함수’에 종속된 ’단일 작업’ 전문가를 양산하는 데 그쳤기 때문이다. 예를 들어, 특정 모션 캡처 데이터를 따라하도록 학습된 로봇은 그 동작 이외의 새로운 요구 사항이 주어지면 아무것도 할 수 없게 된다. 새로운 작업을 시키려면 다시 보상 함수를 설계하고 처음부터 학습을 시작해야 한다. 이는 인간이 하나의 기본 체력을 바탕으로 축구, 농구, 춤을 빠르게 배우는 것과는 대조적이다.
이러한 배경에서 등장한 개념이 바로 ’행동 파운데이션 모델(Behavioral Foundation Models, BFMs)’이다. 언어 모델이 거대한 텍스트 데이터를 통해 언어의 구조를 익히고 어떤 질문에도 답할 수 있는 능력을 갖추는 것처럼, 로봇에게도 전신 움직임의 근본적인 ’문법’을 가르치려는 시도이다. BFM-Zero는 바로 이 지점에서 혁신적인 해법을 제시한다. 이 모델은 비지도 강화학습(Unsupervised RL)을 통해 로봇의 모든 가능한 행동을 하나의 정교한 잠재 공간(Latent Space)에 매핑한다. 이 보고서는 BFM-Zero가 어떻게 재학습 없이(Zero-shot) 다양한 작업을 수행할 수 있는지, 그리고 그 이면에 숨겨진 수학적 직관과 공학적 설계를 심층적으로 분석한다.
방법론: 행동의 지도를 그리는 전방-후방 표현형의 수학적 직관
BFM-Zero의 핵심 메커니즘을 이해하기 위해서는 먼저 ’전방-후방(Forward-Backward, FB) 표현형’이라는 수학적 도구에 주목해야 한다. 이를 아주 직관적으로 설명하자면, 우리가 낯선 도시에 도착해 지도를 만드는 과정과 비슷하다. 기존의 강화학습이 “집에서 도서관까지 가는 가장 빠른 길”만을 외우는 것이라면, FB 표현형은 “도시의 모든 도로가 어떻게 연결되어 있는지”를 파악하여 지도 자체를 그리는 작업이다.
계승 측도와 가치 함수의 분해
일반적인 마르코프 결정 과정(MDP)에서 가치 함수 Q(s, a)는 현재 상태 s에서 행동 a를 취했을 때 기대되는 미래 보상의 합이다. BFM-Zero는 이 가치 함수를 보상(Reward)과 동역학(Dynamics)으로 완전히 분리한다. 이를 가능하게 하는 것이 ‘계승 측도(Successor Measure)’ M^\pi(X|s, a)이다. 이는 정책 \pi를 따를 때 미래에 상태 집합 X에 방문하게 될 할인된 확률 분포를 의미한다.
FB 표현형은 이 계승 측도를 두 개의 저차원 벡터의 내적으로 근사한다:
M^\pi(X|s, a) \approx \int_{s' \in X} F(s, a, z)^\top B(s') \rho(ds')
여기서 F(s, a, z)는 전방 표현형(Forward Representation)으로, 현재 상태와 행동이 미래에 어떤 ’잠재적 방향’으로 나아갈지를 나타낸다. 반면 B(s')는 후방 표현형(Backward Representation)으로, 특정 상태 s'가 도달하기 위해 어떤 ’특징’을 가져야 하는지를 나타낸다. 이 분해가 놀라운 이유는, 어떤 보상 함수 r(s)가 주어지더라도 가치 함수를 다음과 같이 단순히 계산할 수 있기 때문이다:
Q^\pi_r(s, a) = F(s, a, z)^\top z \quad \text{where} \quad z = E_{s \sim \rho}[B(s)r(s)]
즉, 로봇은 보상이 무엇인지 미리 알 필요 없이 세상의 이치(동역학)를 전방 표현형으로 익히고, 보상이 주어지는 순간 그것을 잠재 벡터 z로 변환하여 즉시 최적의 행동을 찾아낸다. 이것이 바로 BFM-Zero가 ‘제로샷(Zero-shot)’ 성능을 낼 수 있는 근본적인 이유이다.
FB-CPR: 인간다운 움직임을 위한 가이드라인
단순히 물리적인 움직임만 배우게 하면 휴머노이드는 기괴하게 관절을 꺾거나 비효율적으로 움직일 수 있다. BFM-Zero는 이를 방지하기 위해 FB-CPR(Conditional Policy Regularization) 기법을 도입한다. 이는 모션 캡처 데이터셋을 활용하여 로봇의 탐색 범위를 ‘인간다운 동작’ 근처로 한정하는 역할을 한다.
연구팀은 GAN(Generative Adversarial Network) 스타일의 판별기(Discriminator)를 사용하여 로봇의 현재 정책이 생성하는 상태-잠재 변수 분포와 실제 인간의 모션 데이터 분포를 비교한다. 판별기는 로봇의 움직임이 인간 데이터셋에 있는 것인지 아닌지를 판별하고, 로봇은 판별기를 속이기 위해 더욱 자연스러운 동작을 취하도록 학습된다. 이 과정은 비지도 학습임에도 불구하고 로봇이 매우 안정적이고 미학적으로도 우수한 전신 기술을 습득하게 만든다.
| 구성 요소 | 역할 | 상세 내용 |
|---|---|---|
| 전방망 (F-net) | 미래 예측 | 상태 s와 행동 a에서 잠재 벡터 z에 따른 결과 예측 |
| 후방망 (B-net) | 상태 특징 추출 | 임의의 상태 s'를 잠재 공간으로 임베딩 |
| 정책망 (\pi_z) | 행동 결정 | 현재 s와 주어진 z에 대해 가치 함수를 최대화하는 a 선택 |
| 판별기 (D) | 행동 규제 | 로봇의 움직임을 실제 인간 모션 데이터와 유사하게 유지 |
graph TD
subgraph Pre-training_Algorithm
Data --> Disc
State --> FNet[Forward Network F]
Action[Action a] --> FNet
Latent[Latent z] --> FNet
FNet --> TD
BNet --> TD
Disc --> Policy[Policy pi_z]
TD --> Policy
end
subgraph Inference_Pipeline
Goal --> Encoder[Inference Formula]
Encoder --> TargetZ
TargetZ --> Policy
Policy --> Control[Unitree G1 Actuators]
end
Sim-to-Real: 시뮬레이션의 지혜를 현실의 감각으로
시뮬레이션에서 아무리 잘 걷는 로봇이라도 현실의 거친 바닥과 센서 노이즈 앞에서는 무너지기 쉽다. BFM-Zero는 이 간극을 메우기 위해 세 가지 핵심 공학적 설계를 도입했다.
Asymmetric History-Dependent Training
시뮬레이션의 비평가(Critic)는 로봇의 정확한 질량 중심, 관절 마찰력, 지면 반력 등 ’특권 정보(Privileged Information)’를 모두 알고 있다. 하지만 실제 로봇의 정책(Policy)은 오직 관절 각도와 자이로스코프 같은 ’가시적 상태(Observable State)’에만 의존해야 한다.
BFM-Zero는 이 정보의 불균형을 해결하기 위해 정책망에 ’역사(History)’를 주입한다. 즉, 단순히 현재 상태뿐만 아니라 과거 H 스텝 동안의 관측값과 행동 기록을 입력으로 받는다. 이는 로봇이 명시적인 물리 파라미터를 알지 못하더라도, 과거의 움직임 패턴을 통해 “지금 내 발 밑이 미끄럽구나” 혹은 “내 등에 무거운 짐이 실렸구나”라는 사실을 내부적으로 추론(Implicit Inference)하게 만든다.
Domain Randomization & Auxiliary Rewards
연구팀은 학습 과정에서 로봇의 질량, 링크의 길이, 마찰 계수 등을 무작위로 변경하는 도메인 랜덤화(DR)를 적용했다. 이는 로봇이 특정 환경에 과적합(Overfitting)되지 않고 보편적인 물리 법칙에 적응하도록 돕는다. 또한, 현실 세계의 안전을 위해 관절 범위를 벗어나지 않게 하거나 급격한 토크 변화를 억제하는 ‘보조 보상(Auxiliary Rewards)’을 추가했다. 흥미로운 점은 이러한 보조 보상이 비지도 학습의 본질을 해치지 않으면서도 실제 하드웨어 운영에 필수적인 ’안전 펜스’ 역할을 한다는 것이다.
| 파라미터 유형 | 가시적 상태 (Proprioception) | 특권 정보 (Privileged Info) |
|---|---|---|
| 관절 데이터 | q_t, \dot{q}_t (위치, 속도) | 모든 링크의 질량 중심 위치 |
| 루트 데이터 | \omega_{root}, g_t (각속도, 중력) | 루트 선속도, 지면과의 거리 |
| 외부 환경 | 과거 행동 기록 a_{t-H:t-1} | 마찰 계수, 경사도, 외부 섭동력 |
| 데이터 차원 | 64차원 (단일 시점 기준) | 463차원 (특권 정보 포함) |
실험 및 결과 분석: Unitree G1에서의 실증적 성과
BFM-Zero의 성능은 Unitree G1 휴머노이드를 통해 검증되었다. Unitree G1은 23개에서 최대 43개의 자유도를 가진 고성능 로봇으로, 전신 제어의 난이도가 매우 높다.
제로샷 작업 수행 (Zero-shot Performance)
학습이 끝난 후, 연구진은 로봇에게 한 번도 가르쳐주지 않은 세 가지 유형의 작업을 즉석에서 명령(Prompting)했다.
- 목표 도달 (Goal Reaching): 로봇에게 특정 정지 자세 s_g를 주면, 정책은 z = B(s_g)를 통해 현재 위치에서 해당 자세로 부드럽게 전이한다. 이는 마치 숙련된 무용수가 어떤 포즈를 요구받았을 때 몸의 균형을 유지하며 우아하게 그 자세를 취하는 것과 같다.
- 동작 추종 (Motion Tracking): 연속적인 모션 캡처 데이터를 입력으로 주면, 로봇은 이를 실시간으로 따라간다. BFM-Zero는 기존의 SOTA 모델인 GMT(Global Motion Tracking)보다 더 적은 데이터로도 훨씬 더 매끄러운 추종 성능을 보여주었다.
- 보상 최적화 (Reward Optimization): “머리 높이를 유지하며 옆으로 걸어라”와 같은 텍스트 형태의 논리적 보상 함수를 주면, 로봇은 잠재 공간을 탐색하여 이를 만족하는 움직임을 즉시 생성한다.
외란에 대한 강건성 (Disturbance Rejection)
BFM-Zero의 가장 인상적인 장면 중 하나는 로봇이 큰 외부 충격을 받았을 때이다. 로봇이 보행 중 옆에서 강하게 밀리면, 정책은 잠재 공간의 연속성을 활용하여 자연스럽게 ’회복 동작’으로 전이한다. 이는 특정 궤적만을 고집하는 기존 방식과 달리, 잠재 공간 자체가 로봇의 동역학적 안정성을 내포하고 있기 때문에 가능한 결과이다.
퓨샷 적응: 4kg의 페이로드를 견디다
제로샷 추론이 모든 문제를 해결할 수는 없다. 학습 시 경험하지 못한 4kg의 무거운 페이로드가 갑자기 추가되었을 때, 로봇은 처음에 다소 불안정한 모습을 보였다. 하지만 연구진은 잠재 공간 Z 내에서 샘플링 기반 최적화(CMA-ES 등)를 수행하는 ‘퓨샷 적응(Few-shot Adaptation)’ 과정을 거쳤다. 결과적으로 단 2분 미만의 시뮬레이션 적응만으로 로봇은 페이로드의 무게를 감안하여 무게 중심을 뒤로 옮기는 법을 스스로 터득했고, 한 발 서기 시간을 획기적으로 늘리는 데 성공했다.
비판적 고찰: 연구의 강점과 한계
강점 및 기여도
BFM-Zero는 비지도 강화학습이 실제 복잡한 휴머노이드 하드웨어에서도 작동할 수 있음을 증명한 최초의 사례 중 하나이다. 특히 보상 함수를 매번 재설계할 필요 없이 ’프롬프트’를 통해 로봇의 행동을 제어할 수 있다는 점은 로봇 공학의 대중화와 확장성 측면에서 엄청난 기여를 한다. 또한, FB 표현형의 수학적 간결함이 실제 휴머노이드의 복잡한 동역학을 효과적으로 압축할 수 있음을 보여주었다.
한계점 및 개선 방향
물론 완벽한 모델은 아니다. 첫째, 잠재 공간의 붕괴(Latent Collapse) 위험이 존재한다. 특정 도메인 랜덤화 조건에서 일부 동작들이 잠재 공간 상의 한 점으로 모여버려 행동의 다양성이 상실되는 현상이 관찰되었다. 둘째, 정밀한 속도 제어의 어려움이다. 비디오 분석 결과, 로봇이 정지 상태에서도 미세하게 흐르는(Drifting) 현상이 보이는데, 이는 관측 데이터셋에 루트의 선속도가 포함되지 않은 설계적 선택에서 기인했을 가능성이 크다. 셋째, 비지도 학습의 품질이 여전히 모션 데이터셋의 질에 의존한다는 점이다. 인간의 데이터가 없는 기발한 동작(예: 물구나무 서서 걷기 등)은 현재의 FB-CPR 구조 하에서는 학습되기 어렵다.
요약 및 결론
BFM-Zero는 ’학습된 전문가’에서 ’학습 가능한 일반인’으로 휴머노이드의 패러다임을 전환하려는 시도이다. 이 모델은 전방-후방 표현형이라는 강력한 수학적 토대 위에 비지도 학습과 비대칭 역사 학습이라는 공학적 기술을 결합하여, 실제 세계의 복잡성을 견뎌내는 행동 파운데이션 모델을 구축했다.
로봇공학자들에게 이 연구가 주는 메시지는 명확하다. 우리가 로봇에게 모든 상황에 대한 정답을 가르칠 수는 없지만, 로봇이 스스로 정답을 찾을 수 있는 ’공간’과 ’언어’를 만들어줄 수는 있다는 것이다. BFM-Zero가 구축한 이 잠재 공간은 향후 대규모 언어 모델(LLM)이나 시각 모델(VLM)과 결합되어, 인간의 고수준 명령을 저수준의 정교한 모터 제어로 연결하는 핵심 고리가 될 것이다.
결론적으로 BFM-Zero는 휴머노이드 제어의 새로운 표준을 제시했다. 이제 우리는 로봇에게 “어떻게 걸을지”를 가르치는 단계를 넘어, 로봇이 스스로 “어떤 움직임이 가능한지”를 탐구하게 만들고 있다. 이것이 바로 우리가 꿈꾸던 ’일반 지능을 가진 로봇’으로 가는 가장 유망한 경로 중 하나임에 틀림없다.