📃SegDAC 리뷰
🔍 Ping. 🔔 Ring. ⛏️ Dig. A tiered review series: quick look, key ideas, deep dive.
Related Post: ManiSkill3 리뷰
- 💡 SegDAC는 시각적 강화 학습(RL)을 위해 Segment Anything(SAM)과 YOLO-World를 활용하여 동적이고 가변적인 수의 객체 중심 표현을 추출하는 새로운 Transformer 기반 Actor-Critic 방법을 제안합니다.
- 🚀 이 방법은 이미지 재구성, 데이터 증강, 또는 수동 레이블 없이 잠재 공간에서 직접 학습하며, 가변 길이의 segment embedding을 처리하는 최초의 온라인 RL 방법입니다.
- 🏆 ManiSkill3 벤치마크에서 SegDAC는 가장 어려운 시각적 일반화 설정에서 기존 성능을 최대 2배 향상시키고 샘플 효율성도 능가하며, 더 가볍고 직접적인 파이프라인으로도 우수한 결과를 달성할 수 있음을 입증했습니다.
🔍 Ping Review
🔍 Ping — A light tap on the surface. Get the gist in seconds.
본 논문은 Visual Reinforcement Learning (Visual RL)에서 고차원 시각 입력, 환경 가변성, 그리고 시각적 perturbations에 대한 정책의 낮은 견고성으로 인해 발생하는 도전 과제를 다룹니다. 기존의 대규모 인지 모델(perception models)을 효과적으로 Visual RL에 통합하여 시각적 일반화(visual generalization) 및 샘플 효율성(sample efficiency)을 개선하는 것이 어렵다는 점을 지적합니다.
SegDAC: Improving Visual Reinforcement Learning by Extracting Dynamic Object-Centric Representations from Pretrained Vision Models
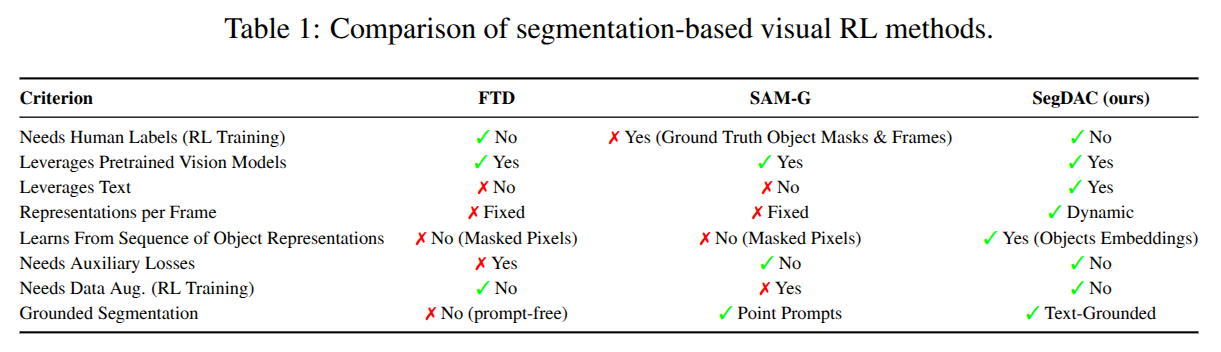
본 논문은 이러한 문제 해결을 위해 SegDAC (Segmentation-Driven Actor-Critic)이라는 새로운 접근 방식을 제안합니다. SegDAC는 Object-Centric Representations가 픽셀 기반 또는 패치 기반(patch-based) 표현보다 더 유용하다는 가정하에 개발되었습니다. 기존의 분할(segmentation) 기반 RL 방법들이 고정된 슬롯(fixed slots), 사전 계산된 마스크(precomputed masks) 또는 강한 지도학습(strong supervision)에 의존하여 유연성과 일반성을 제한했던 한계를 극복합니다.
핵심 방법론 (Core Methodology)
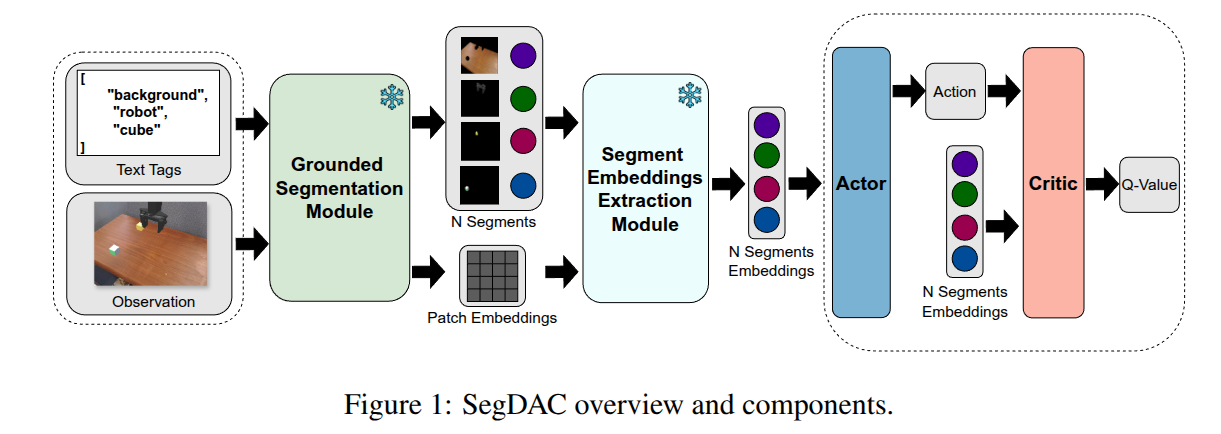
SegDAC의 핵심은 사전에 학습된 비전 모델을 활용하여 동적인 수의 Object-Centric Embeddings를 추출하고 이를 통해 행동을 예측하거나 Q-value를 평가하는 것입니다. SegDAC는 raw pixels에서 인코더를 학습하는 대신 latent space에서 완전히 동작합니다.
Grounded Segmentation Module:
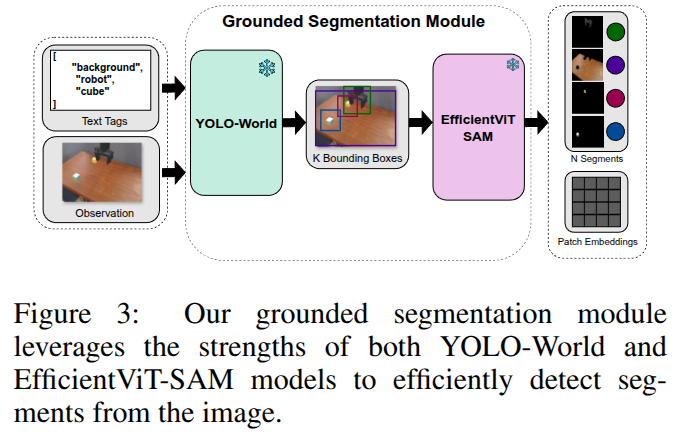
- 이 모듈은 RGB 이미지와 일련의 grounding text inputs을 사용하여 텍스트 기반으로 이미지를 분할합니다.
- YOLO-World 모델은 open-vocabulary를 사용하여 제공된 text tags (예: “cube”, “robot”, “background”)를 기반으로 바운딩 박스(bounding boxes)를 생성합니다. YOLO-World는 zero-shot 방식으로 동작합니다.
- 이 바운딩 박스들은 EfficientViT-SAM (SAM) 모델의 프롬프트(prompts)로 사용되어 각 박스 내에서 세그먼트 마스크(segment masks)와 패치 임베딩(patch embeddings)을 생성합니다. SAM과 YOLO-World는 학습 과정에서 frozen 상태로 유지됩니다.
- 이 모듈의 출력은 시간 단계마다 가변적인 수(N)의 세그먼트입니다. 이는 고정된 수의 객체 표현에 의존하는 기존 방법들과의 차이점입니다.
- 특히 “background”와 같은 일반적인 text tag를 포함하여 에이전트가 관련 없는 영역을 무시하도록 학습함으로써 일반화를 향상시키는 효과가 있음이 입증되었습니다.
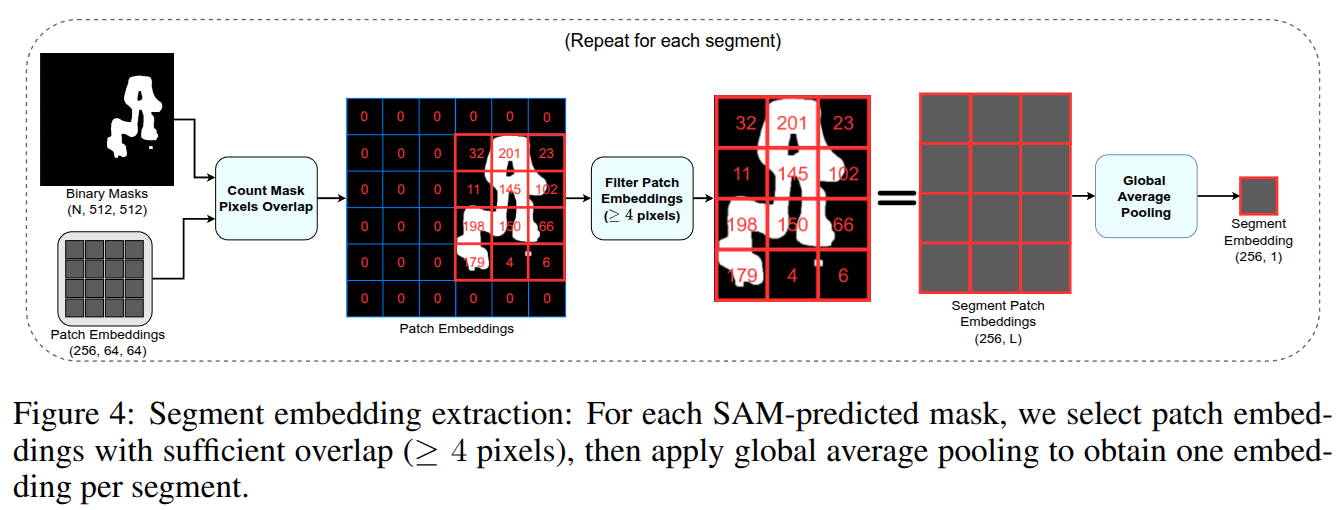
Segment Embeddings Extraction Module:
- 이 모듈은 Grounded Segmentation Module에서 생성된 이진 세그먼트 마스크(N개)와 SAM의 패치 임베딩을 입력으로 받습니다.
- 학습 가능한 파라미터가 없는 이 모듈은 각 세그먼트 마스크에 대해 해당 마스크와 공간적으로 겹치는 SAM 패치 임베딩을 식별합니다.
- 각 패치 내 마스크의 활성 픽셀(active pixels) 수를 세어, 작은 임계값(예: 4픽셀) 미만으로 겹치는 패치는 버려집니다.
- 남은 관련 패치 임베딩에 Global Average Pooling을 적용하여 각 세그먼트에 대한 단일 임베딩 벡터 (차원 S, 예: S=256)를 생성합니다.
- 이 과정은 SAM의 패치 임베딩이 전체 이미지로부터의 contextual information을 포함하고 있기 때문에, 결과 세그먼트 임베딩 또한 이러한 공유 컨텍스트를 계승하여 분할이 불완전할 때에도 견고성을 유지합니다.
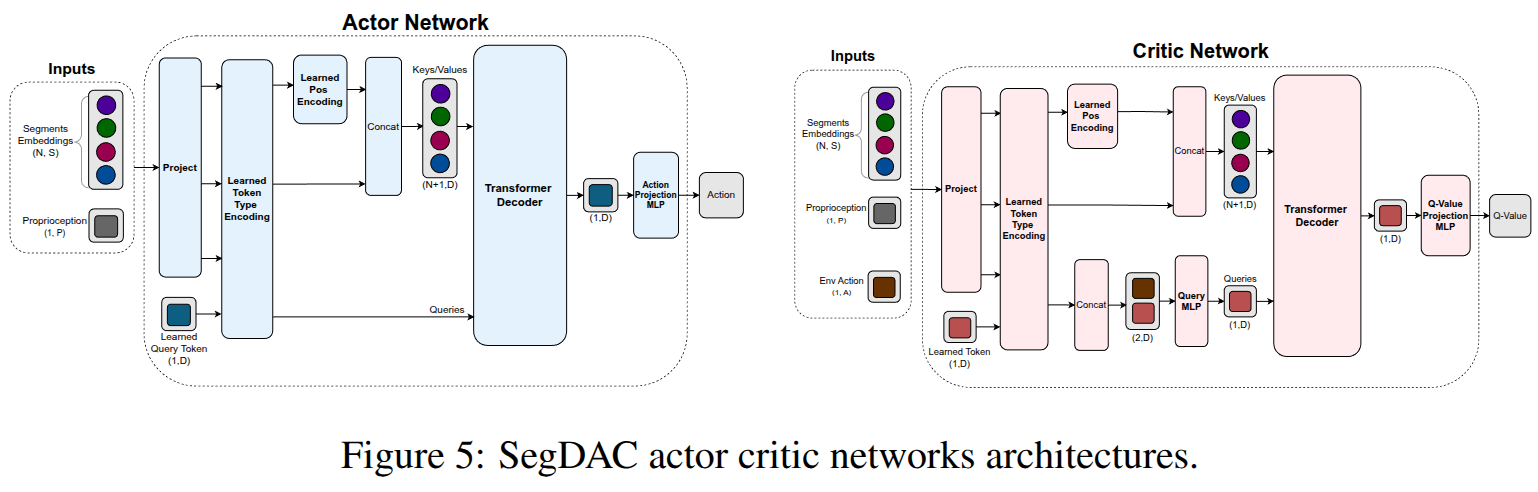
Actor-Critic Networks:
- Actor와 Critic은 각각 독립적인 transformer decoder를 사용하며, 고유한 가중치(weights), projection heads 및 encoding layers를 가집니다.
- 입력은 세그먼트 임베딩, proprioception (로봇의 자체 상태 정보), 그리고 학습된 query token으로 구성됩니다.
- 모델은 세그먼트, proprioception, query를 구분하기 위해 학습된 token-type encoding을 각 토큰에 부여합니다.
- 세그먼트 토큰에는 바운딩 박스 좌표에 기반한 positional encoding이 추가되어 객체 중심 구조에 맞는 공간적 참조를 제공합니다.
- Critic 네트워크의 경우, query는 action vector와 학습된 토큰을 concatenate하고 MLP를 통해 투영하여 형성됩니다. Keys와 values는 세그먼트 토큰, proprioception 토큰, 학습된 토큰의 집합을 투영하여 얻습니다. 디코더는 이 집합에 어텐션(attention)을 적용하여 단일 출력 토큰을 생성하며, 이는 projection head를 통해 Q-value로 매핑됩니다.
- Actor 네트워크는 유사한 설계를 사용하지만, 학습된 query token이 action 입력 역할을 하며, 출력 토큰은 action space로 투영됩니다.
- SegDAC는 직접 세그먼트 임베딩에서 작동하므로 패치 기반 인코더보다 훨씬 적은 수의 토큰을 처리하며, 감독 없이도 중요한 객체에 초점을 맞출 수 있습니다.
주요 기여 (Main Contributions)
- Dynamic object-centric RL: 이미지 재구성 단계 없이 가변 길이 세그먼트 임베딩에서 직접 작동하는 transformer 기반 Actor-Critic을 제안합니다. 이는 SegDAC가 온라인 RL에서 동적으로 계산되는 가변 길이 객체 임베딩에서 학습하는 최초의 방법임을 의미합니다.
- Text-Grounded Segmentation for Online RL: 온라인 RL을 위해 텍스트 기반 분할을 사용하고 가변적인 수의 세그먼트 임베딩에서 학습하는 최초의 방법입니다.
- Strong visual generalization: ManiSkill3 기반의 새로운 시각적 일반화 벤치마크에서 기존 성능의 두 배 향상을 달성했습니다.
- Faster SAM-based training and inference: 경량 세그먼트 임베딩, 빠른 텍스트 기반 분할, 간단한 마스크 후처리, 완전한 latent-space 학습을 통해 기존 SAM 기반 접근 방식보다 2~5배 빠른 속도를 제공합니다.
- New direction for visual RL: 데이터 증강(data augmentation), 보조 손실(auxiliary losses), 외부 데이터셋 없이 순수 SAC 손실만 사용하여 강한 시각적 일반화를 달성할 수 있음을 보여주며, 더 가볍고 직접적인 파이프라인의 가능성을 제시합니다.
실험 결과 (Experimental Results)
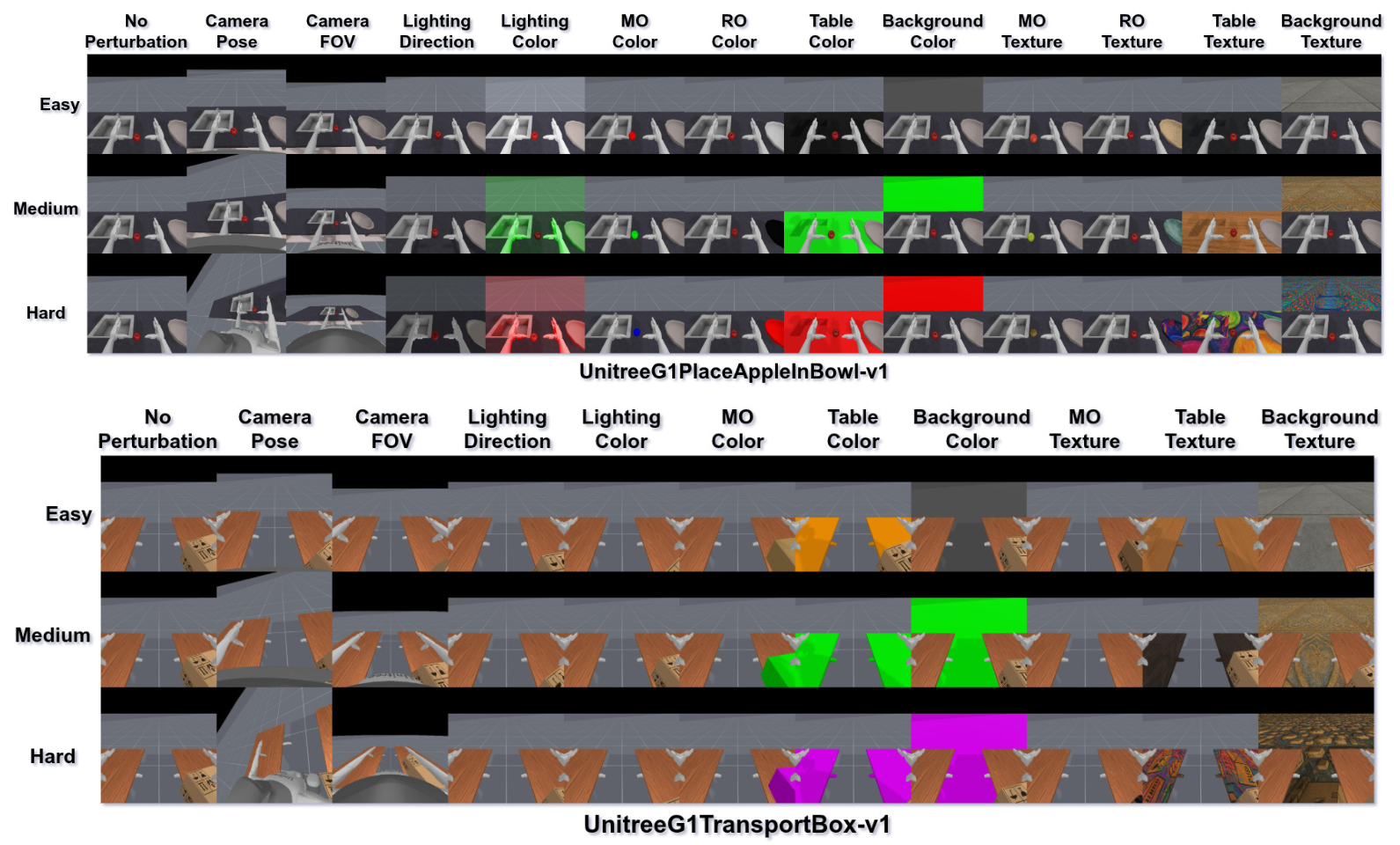
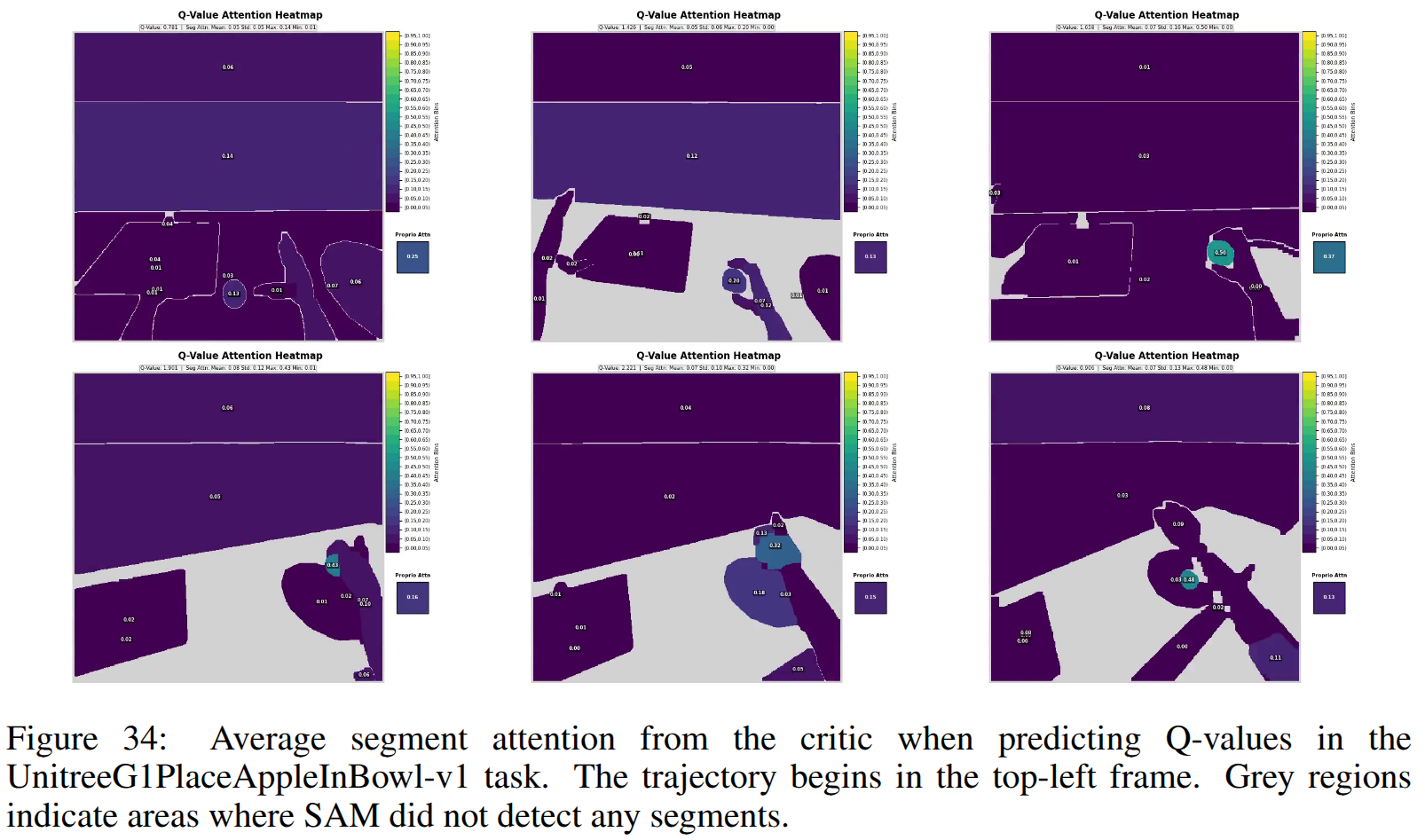
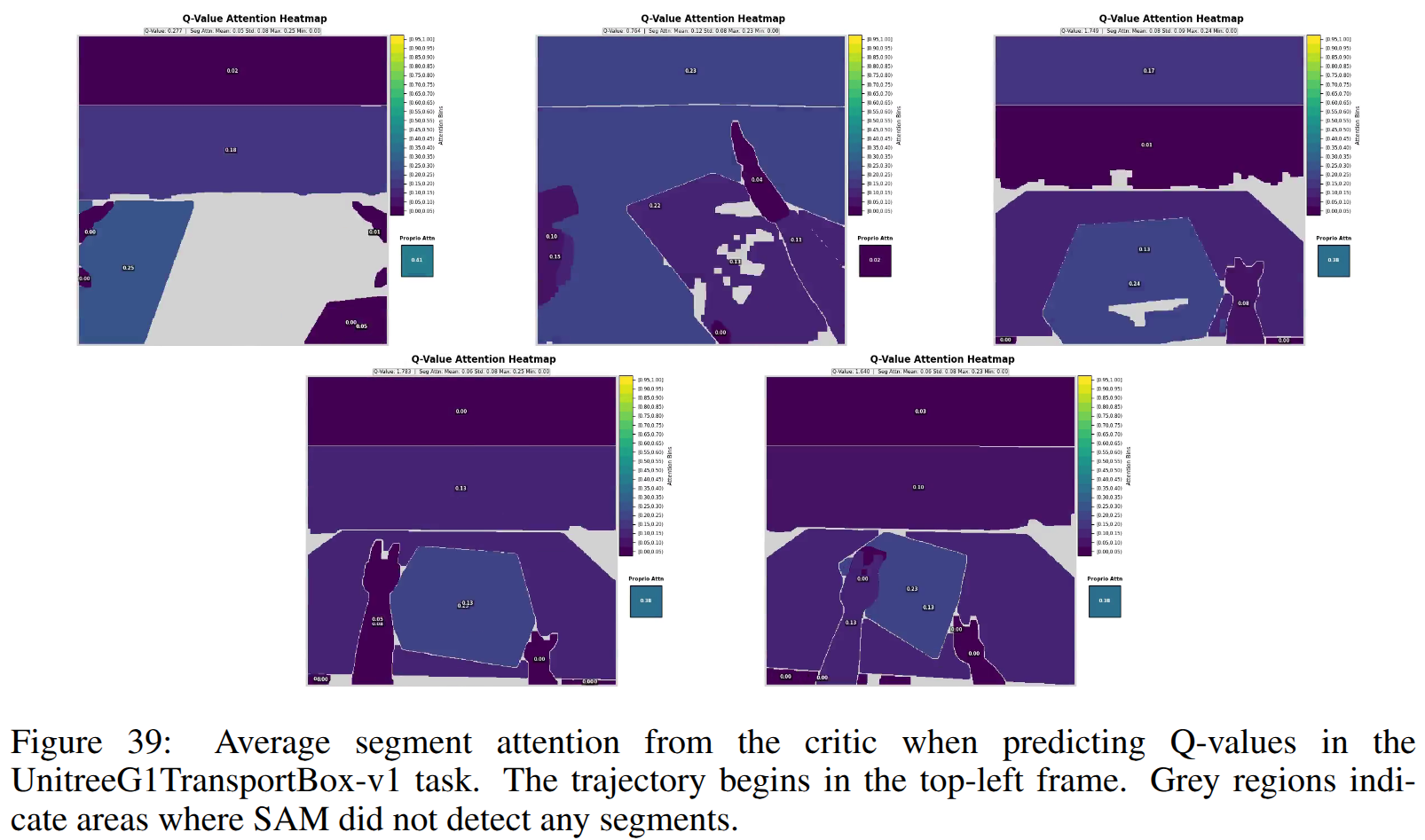
SegDAC는 ManiSkill3 기반의 새로운 시각적 일반화 벤치마크(8개 조작 작업, 3단계 난이도, 12가지 시각적 섭동)에서 평가되었습니다. SegDAC는 모든 기존 baseline (SAC-AE, DrQ-v2, SAM-G, SMG, SADA, MaDi) 대비 더 높은 견고성을 보였습니다. 특히 가장 어려운 설정에서는 기존 성능을 두 배로 높였으며, 샘플 효율성 측면에서는 state-of-the-art인 DrQ-v2와 필적하거나 능가했습니다. SegDAC는 동적으로 변화하는 세그먼트 수, 크기, 세밀도(granularity)에도 불구하고 안정적인 동작을 유지했으며, 작업 관련 객체에 선택적으로 attention을 기울이는 능력을 보여주었습니다. 이는 객체 중심 접근 방식의 강점을 입증합니다.