flowchart TB
subgraph Input["입력"]
A[RGB 이미지] --> D[Vision Encoder]
B[텍스트 명령] --> E[Language Encoder]
C[Proprioception] --> F[MLP + Embodiment ID]
end
subgraph VLM["Vision-Language Model"]
D --> G[Cosmos-Reason-2B VLM]
E --> G
end
subgraph ActionHead["Action Head"]
G --> H[MLP Connector]
F --> H
H --> I[Flow Matching DiT]
I --> J[Continuous Actions]
end
🧩NVIDIA GR00T N1.6
foundation model
vla
휴머노이드 로봇용 차세대 파운데이션 모델
개요
GR00T N1.6은 엔비디아가 개발한 오픈 Vision-Language-Action(VLA) 파운데이션 모델의 최신 버전입니다. 로봇이 자연어 지시를 이해하고, 전체 몸 동작과 조작을 통합해 실제 세계에서 인간처럼 행동할 수 있도록 설계되었습니다.
기존 GR00T N1, N1.5 모델을 기반으로 하며, 데이터·아키텍처·추론 능력이 크게 강화되었습니다. CES 2026에서 공개된 이 모델은 Cosmos Reason을 두뇌로 활용하여 휴머노이드 로봇의 전신 제어(whole-body control)를 지원합니다.

Note핵심 특징
- 언어, 이미지, 로봇 상태 정보를 통합한 범용 로봇 지능
- 물리적 추론 능력을 갖춘 상황 이해 및 계획 수립
- Hugging Face 및 GitHub를 통한 오픈 모델 접근
- Cross-embodiment: 다양한 로봇 형태에 적용 가능
모델 스펙
GR00T-N1.6-3B 개요
Hugging Face에서 공개된 GR00T N1.6 모델의 상세 스펙입니다:
| 항목 | 값 |
|---|---|
| 파라미터 수 | 3B (30억) |
| 텐서 타입 | BF16 |
| 포맷 | Safetensors |
| 런타임 | PyTorch |
| 라이선스 | NVIDIA One-Way Non-Commercial License |
아키텍처 구성
Architecture Type: Vision Transformer + Multilayer Perceptron + Flow Matching Transformer
| 구성 요소 | 모델/기술 | 설명 |
|---|---|---|
| Vision Encoder | Cosmos-Reason-2B 내장 | 네이티브 종횡비 지원, 패딩 불필요 |
| Language Encoder | Cosmos-Reason-2B 내장 | 텍스트 명령 인코딩 |
| Proprioception | MLP + Embodiment ID | 로봇 형태별 고유감각 인코딩 |
| Action Decoder | Flow Matching DiT (32 layers) | AdaLN으로 확산 스텝 컨디셔닝 |
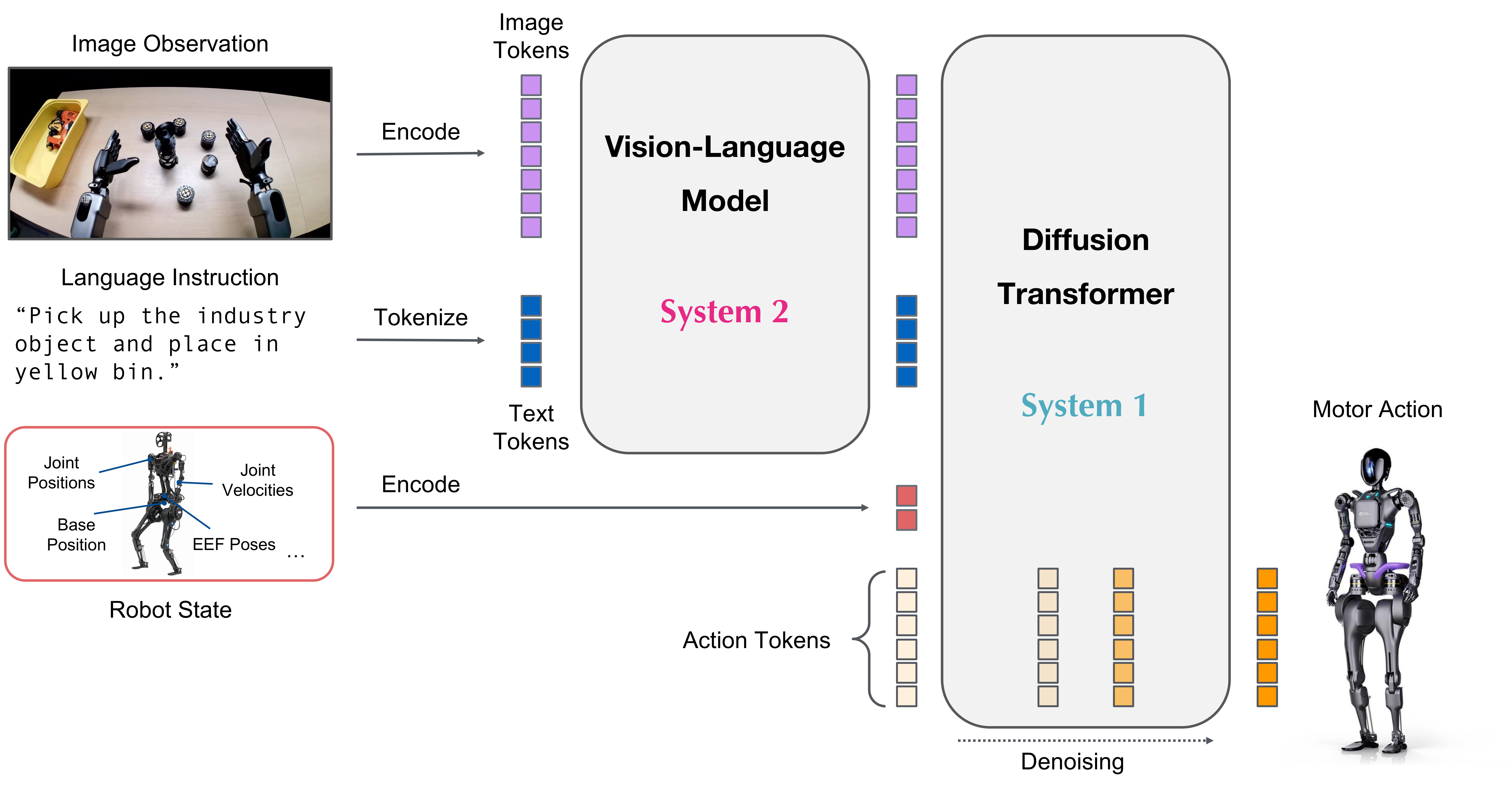
네트워크 아키텍처 상세
GR00T N1.6은 Vision Transformer와 Text Transformer를 사용하여 로봇의 이미지 관측과 텍스트 지시를 인코딩합니다.
다중 뷰 처리:
- 로봇 형태(embodiment)별로 가변적인 카메라 뷰 수를 처리
- 모든 프레임의 이미지 토큰 임베딩을 시퀀스로 연결(concatenate)
- 이미지 토큰 뒤에 언어 토큰 임베딩을 연결
flowchart LR
subgraph ImageTokens["이미지 토큰"]
A[View 1] --> D[Token Seq]
B[View 2] --> D
C[View N] --> D
end
D --> E[Language Tokens]
E --> F[VLM Output]
Proprioception 인코딩:
- Embodiment ID로 인덱싱된 MLP를 사용하여 로봇 고유감각 인코딩
- 가변 차원 proprioception 처리를 위해 configurable max length로 패딩 후 MLP에 입력
- 액션 인코딩 및 속도 예측 디코딩도 embodiment별 개별 MLP 사용
Flow Matching Transformer (DiT) 구현:
| 구성 요소 | 설명 |
|---|---|
| Self-Attention | Proprioception과 Actions에 대한 self-attention |
| Cross-Attention | Vision 및 Language 임베딩에 대한 cross-attention |
| Interleaving | Self-attention과 Cross-attention을 교차 배치 |
| AdaLN | Adaptive LayerNorm으로 diffusion step 컨디셔닝 |
NoteN1.5 기준 네트워크 아키텍처 (참고)
N1.5에서는 다음 구성을 사용했습니다:
- Vision: 사전학습된 Vision Transformer (SigLip2)로 RGB 프레임 처리
- Language: 사전학습된 Transformer (T5)로 텍스트 인코딩
- Proprioception: Embodiment ID로 인덱싱된 MLP
- Action: Embodiment별 개별 MLP로 인코딩/디코딩
- DiT: Adaptive LayerNorm (AdaLN)으로 diffusion step 컨디셔닝
NoteN1.5 → N1.6 아키텍처 변경점
- VLM 변경: SigLip2 + T5 → Cosmos-Reason-2B VLM (통합 모델)
- DiT 확장: 16 layers → 32 layers (2배)
- 학습 목표 추가: Flow Matching + World-Modeling 공동 학습
- MLP Connector 개선: 시뮬레이션 벤치마크 성능 향상
입출력 형식
입력 (Input):
| 유형 | 입력 타입 | 포맷 | 파라미터 |
|---|---|---|---|
| Vision | Image Frames | 로봇 카메라의 가변 개수 이미지 프레임 | 2D RGB 이미지, 임의 해상도 |
| State | Robot Proprioception | Floating Point | 1D 부동소수점 벡터 |
| Language | Text Instruction | String | 1D 문자열 |
출력 (Output):
| 유형 | 출력 타입 | 포맷 | 파라미터 |
|---|---|---|---|
| Actions | Motor Controls | Continuous-value vectors | 2D 벡터 |
Note출력 특성
출력되는 연속값 벡터는 로봇의 자유도(Degrees of Freedom, DOF)에 따라 다른 모터 제어값에 대응합니다. 로봇 형태(embodiment)에 따라 출력 차원이 달라집니다.
GPU 최적화
GR00T N1.6은 NVIDIA GPU 가속 시스템에서 실행되도록 설계 및 최적화되었습니다:
| 항목 | 설명 |
|---|---|
| 하드웨어 활용 | NVIDIA GPU 코어 활용 |
| 소프트웨어 프레임워크 | CUDA 라이브러리 |
| 성능 이점 | CPU 전용 솔루션 대비 빠른 학습/추론 시간 |
학습 데이터
| 항목 | 값 |
|---|---|
| 데이터셋 | nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim |
| 샘플 수 | 855K |
| 구성 | 실제 로봇 데이터 + 합성 데이터 (Isaac GR00T Blueprint) |
| 로봇 형태 | Bimanual, Semi-Humanoid, Humanoid |
학습 설정
| 항목 | 사전학습 | 파인튜닝 |
|---|---|---|
| Steps | 300K | 10K~30K |
| Batch Size | 16,384 | ≤1K |
| 용도 | 범용 모델 | 태스크 특화 |
하드웨어 요구사항
| 항목 | 지원 |
|---|---|
| GPU 아키텍처 | Ampere, Hopper, Lovelace, Blackwell |
| Jetson | 지원 (AGX Orin 등) |
| OS | Linux (권장) |
시뮬레이션 벤치마크
GR00T N1.6은 다음 벤치마크에서 평가되었습니다:
| 벤치마크 | 태스크 수 | 설명 |
|---|---|---|
| DexMG | 9 | Dexterous manipulation |
| RoboCasa | 24 | Mobile manipulator 시뮬레이션 |
| Digital Cousin | 24 | GR-1 휴머노이드 manipulation |
실제 로봇 검증:
- Bimanual YAM
- Agibot Genie-1
- Unitree G1
- GR-1 Humanoid
모델 버전 비교
| 항목 | GR00T-N1-2B | GR00T-N1.5-3B | GR00T-N1.6-3B |
|---|---|---|---|
| 파라미터 | 2B (2.2B) | 3B | 3B |
| VLM | Eagle-2 (1.34B) | SigLip2 + T5 | Cosmos-Reason-2B |
| DiT | 0.86B | 16 layers | 32 layers |
| 행동 예측 | 절대 좌표 | 절대 좌표 | 상대 좌표 |
| World-Modeling | X | X | O |
Eagle VLM과의 관계
GR00T 시리즈의 VLM 백본은 NVIDIA의 Eagle VLM 연구에서 시작되었습니다:
NoteEagle VLM 계보
Eagle은 NVIDIA가 개발한 Vision-Language Model로, ICLR 2025 Spotlight 논문으로 채택되었습니다.
- Eagle 1: Mixture of Vision Encoders (MoVE) 아키텍처 제안
- Eagle 2: SigLIP + ConvNeXt 조합으로 고해상도 이미지 처리 강화
- Eagle 2.5: Long-Context Post-Training으로 긴 비디오/고해상도 이미지 이해력 향상
GR00T 버전별 VLM 진화:
flowchart LR
A[Eagle-2 VLM] --> B[GR00T N1-2B]
C[SigLip2 + T5] --> D[GR00T N1.5-3B]
E[Cosmos-Reason-2B] --> F[GR00T N1.6-3B]
B --> D
D --> F
style A fill:#e1f5fe
style C fill:#e1f5fe
style E fill:#e1f5fe
| 버전 | VLM 백본 | 특징 |
|---|---|---|
| N1-2B | Eagle-2 (1.34B) | SmolLM2 + SigLIP-2 기반, 12번째 레이어에서 representation 추출 |
| N1.5-3B | SigLip2 + T5 | 분리된 Vision/Language 인코더 |
| N1.6-3B | Cosmos-Reason-2B | 통합 VLM, 물리 추론 + embodied reasoning 특화 |
Eagle VLM의 핵심 기술:
| 기술 | 설명 |
|---|---|
| Mixture of Vision Encoders (MoVE) | 여러 비전 인코더 토큰을 단순 연결 (복잡한 mixing 불필요) |
| Tiled MoVE | SigLIP + ConvNeXt 조합으로 고해상도 처리 |
| Pre-Alignment | 비전 인코더와 언어 토큰 간 갭 해소 |
| PixelShuffle | SigLIP 피처를 2x 다운샘플링하여 ConvNeXt 출력과 매칭 |
GR00T N1.6의 Hugging Face 모델 카드에서 Eagle 2.5 논문을 참조로 명시한 이유는, Eagle VLM 연구가 GR00T 시리즈의 Vision-Language 처리 기반 기술로 활용되었기 때문입니다. 다만 N1.6에서는 Eagle에서 Cosmos-Reason으로 VLM이 진화하여 물리적 추론 능력이 강화되었습니다.
기술적 특징
듀얼 시스템 아키텍처
GR00T N1.6은 듀얼 시스템 설계를 채택합니다:
flowchart LR
subgraph System2["System 2 (Slow Thinking)"]
A[Vision-Language Model] --> B[환경 이해]
B --> C[지시 해석]
end
subgraph System1["System 1 (Fast Acting)"]
D[Diffusion Transformer] --> E[연속 행동 생성]
end
C --> D
E --> F[로봇 제어]
| 시스템 | 역할 | 구성 요소 |
|---|---|---|
| System 2 | 느린 사고 (deliberate thinking) | Cosmos-Reason-2B VLM |
| System 1 | 빠른 행동 (real-time action) | 32-layer Diffusion Transformer |
멀티모달 입력 처리
GR00T N1.6은 세 가지 입력을 동시에 처리합니다:
| 입력 유형 | 설명 | 특징 |
|---|---|---|
| 텍스트 | 자연어 명령 | 모호한 지시도 단계별 계획으로 분해 |
| 이미지 | 카메라 입력 | 네이티브 종횡비 지원, 패딩 없이 인코딩 |
| 로봇 상태 | Proprioception | 관절 위치, 속도, 토크 등 |
Vision-Language Model (VLM)
GR00T N1.6의 VLM은 Cosmos-Reason-2B를 기반으로 합니다:
- 유연한 해상도: 이미지를 네이티브 종횡비로 인코딩 (패딩 불필요)
- 듀얼 학습: 일반 vision-language 태스크 + embodied reasoning 태스크
- 다음 행동 예측: next action prediction으로 훈련
Diffusion Transformer (DiT)
행동 생성을 담당하는 DiT의 주요 특징:
| 항목 | N1.5 | N1.6 |
|---|---|---|
| DiT 레이어 수 | 16 | 32 (2배) |
| Post-VLM Adapter | 4-layer transformer | 제거 |
| VLM 상위 레이어 | Frozen | Unfrozen (상위 4개 레이어) |
| 행동 예측 방식 | 절대 좌표 | 상대 좌표 (state-relative) |
ImportantFlow Matching 기반 행동 생성
GR00T N1.6은 Flow Matching Transformer를 사용하여 연속적인 행동을 생성합니다:
- 학습 시: 클린 액션 벡터와 가우시안 노이즈 사이를 랜덤하게 보간하여 입력
- 추론 시: 가우시안 노이즈에서 시작하여 속도 예측을 통해 반복적으로 액션 복원
- 결과: 더 부드럽고 덜 떨리는(jittery) 동작 생성
Flow Matching의 이론적 배경
GR00T N1.6의 행동 생성 메커니즘은 Rectified Flow와 π₀ (Pi-Zero) 연구에 기반합니다:
Rectified Flow
Rectified Flow는 ICLR 2023 Spotlight 논문으로, 두 분포 사이의 transport를 학습하는 ODE 기반 방법입니다:
flowchart LR
A["π₀ (노이즈 분포)"] -->|"직선 경로 학습"| B["π₁ (타겟 분포)"]
B -->|"Rectification"| C["더 직선화된 경로"]
C -->|"반복"| D["1-step 생성 가능"]
핵심 아이디어:
| 개념 | 설명 |
|---|---|
| 직선 경로 선호 | 두 점 사이 최단 경로 = 직선 → 시간 이산화 없이 정확한 시뮬레이션 가능 |
| Rectification | 임의 coupling을 점점 더 직선화된 결정론적 coupling으로 변환 |
| Reflow | 반복 적용으로 궁극적으로 1-step 생성 달성 |
| 손실 함수 | 간단한 비선형 최소제곱 → 대규모 모델 확장 용이 |
로봇 제어에서의 장점:
- 부드럽고 연속적인 행동 궤적 생성
- 빠른 추론 속도 (적은 denoising step)
- GAN보다 높은 다양성, 빠른 diffusion보다 좋은 품질
π₀ (Pi-Zero) 아키텍처
π₀는 Physical Intelligence가 개발한 범용 로봇 제어용 VLA Flow Model입니다:
| 항목 | π₀ | GR00T N1.6 |
|---|---|---|
| VLM 백본 | PaliGemma | Cosmos-Reason-2B |
| Action Head | Flow Matching | Flow Matching DiT |
| Action Chunk | H=50 (50Hz) | H=16 |
| VLM-DiT 연결 | MoE-like 구조 | Cross-Attention |
| 학습 데이터 | 7개 로봇, 68개 태스크 | 시뮬레이션 + 실제 데이터 혼합 |
π₀의 주요 기술 (GR00T에 영향):
- Flow Matching Action Generation: 랜덤 노이즈 → 모터 액션 시퀀스로 점진적 수렴
- Pre-trained VLM 활용: 인터넷 규모 시맨틱 지식 상속
- Cross-Embodiment: 단일 모델로 다양한 로봇 형태 지원
- Real-time Control: 50Hz로 부드러운 실시간 액션 궤적 생성
flowchart TB
subgraph FlowMatching["Flow Matching 프로세스"]
A[가우시안 노이즈] -->|"t=0"| B[중간 상태]
B -->|"t=0.5"| C[중간 상태]
C -->|"t=1"| D[액션 시퀀스]
end
E[이미지 + 텍스트] --> F[VLM]
F --> G[Cross-Attention]
H[Proprioception] --> G
G --> FlowMatching
D --> I[로봇 제어]
GR00T vs π₀: 주요 차이점
| 측면 | π₀ | GR00T N1.6 |
|---|---|---|
| 데이터 전략 | 실제 로봇 데이터 중심 (Trossen ALOHA) | 시뮬레이션 + 합성 데이터 활용 |
| 추론 속도 | 50Hz | 10Hz (System 2) + 120Hz (System 1) |
| VLM 학습 | Fine-tuning | Frozen + 상위 4개 레이어만 Unfrozen |
| Auxiliary Loss | - | Object Detection Loss (Ldet) 추가 |
| 타겟 로봇 | 다양한 형태 | 휴머노이드 특화 |
TipGR00T의 Object Detection Loss
GR00T N1은 Flow Matching Loss (Lfm) 외에 Object Detection Loss (Ldet)를 추가하여, 모델의 비전 시스템이 지시문에 언급된 핵심 객체를 명시적으로 위치 추정하도록 강제합니다. 이는 예측된 동작과 관련 객체 간의 연결을 학습하는 데 도움이 됩니다.
N1.6 주요 개선점
1. 향상된 Reasoning
- Cosmos Reason 통합: 물리 법칙과 상식을 이해하는 추론 특화 VLM
- Chain-of-Thought 추론: 복잡한 지시를 단계별 계획으로 분해
- 상황 일반화: 새로운 환경에서도 적절한 판단 수행
2. 확장된 데이터 및 로봇 접목
- 양손 로봇(dual-arm/bimanual) 데이터
- Semi-humanoid 및 다양한 형태의 시뮬레이션 궤적
- 실제 로봇 데이터: Unitree G1, Agibot Genie-1, YAM 등
3. 성능 향상
- N1.5 대비 시뮬레이션 벤치마크 및 실제 로봇 성능 모두 향상
- 더 빠른 수렴 속도 (단, 오버피팅 방지를 위한 튜닝 필요)
- 300K steps, batch size 16384로 사전학습
Cosmos Reason: 로봇의 두뇌
Cosmos Reason은 GR00T N1.6의 추론 엔진 역할을 합니다:
Cosmos Reason 특징
| 항목 | 설명 |
|---|---|
| 기반 모델 | Qwen2.5-VL (Reason 1) / Qwen3-VL (Reason 2) |
| 파라미터 | 2B, 7B, 8B 버전 제공 |
| 주요 능력 | 시공간 이해, 물리 법칙 추론, embodied decision making |
| 특수 기능 | 2D/3D 포인트 로컬라이제이션, 바운딩 박스 좌표 추론 |
활용 사례
flowchart TB
A[모호한 지시] --> B[Cosmos Reason]
B --> C[단계별 계획 생성]
C --> D[GR00T N1.6 Action Head]
D --> E[로봇 제어 명령]
F["'저기 있는 물건 가져와'"] --> B
B --> G["1. 물건 위치 파악\n2. 경로 계획\n3. 그리퍼 접근\n4. 파지\n5. 복귀"]
Sim-to-Real 워크플로우
엔비디아는 시뮬레이션에서 실세계로의 전이를 지원하는 통합 워크플로우를 제공합니다:
flowchart LR
A[Isaac Sim] --> B[COMPASS 합성 데이터]
B --> C[GR00T N1.6 학습]
C --> D[Fine-tuning]
D --> E[실세계 배포]
F[Whole-body RL] --> C
G[cuVSLAM/cuVGL] --> E
H[Newton Physics Engine] --> A
Isaac Lab
Isaac Lab은 로봇 학습을 위한 오픈소스 모듈형 프레임워크입니다:
| 특징 | 설명 |
|---|---|
| 기반 | NVIDIA Isaac Sim 위에 구축 |
| 물리 엔진 | NVIDIA PhysX (Newton 통합 예정) |
| 렌더링 | NVIDIA RTX 기반 물리 기반 렌더링 |
| 병렬화 | GPU 기반 대규모 병렬 시뮬레이션 |
지원 RL 라이브러리:
- RSL RL
- RL-Games
- SKRL
- Stable Baselines3
Newton Physics Engine
Newton은 Google DeepMind, Disney Research, NVIDIA가 공동 개발하고 Linux Foundation이 관리하는 오픈소스 GPU 가속 물리 엔진입니다:
NoteNewton의 특징
- NVIDIA Warp 기반: 고속, 물리적으로 정확한 미분 가능 시뮬레이션
- 유연한 솔버: 눈/자갈 위 보행, 컵/과일 같은 취약 물체 조작 등 복잡한 태스크 시뮬레이션
- 로봇 학습 프레임워크 통합: MuJoCo Playground, Isaac Lab과 호환
- Gradient 기반 학습: 미분 가능 시뮬레이션으로 데이터 효율적 학습 가능
얼리 어답터: ETH Zurich RSL, TU Munich, Peking University, Lightwheel, Style3D
COMPASS: 합성 내비게이션 데이터
COMPASS (Cross-embOdiment Mobility Policy via ResiduAl RL and Skill Synthesis)는 cross-embodiment mobility policy 개발을 위한 워크플로우입니다:
flowchart TB
subgraph Training["COMPASS 학습 파이프라인"]
A[Imitation Learning] --> D[Policy Distillation]
B[Residual RL] --> D
C[시뮬레이션 궤적] --> A
C --> B
end
D --> E[Vision-based Mobility Model]
E --> F[Zero-shot Sim-to-Real 배포]
COMPASS 주요 특징:
| 항목 | 설명 |
|---|---|
| 입력 | 비전 기반 (카메라 이미지) |
| 출력 | Velocity 명령 → Whole-body Controller |
| 전이 성능 | 추가 데이터 수집 없이 Zero-shot Sim-to-Real |
| Cross-embodiment | 휴머노이드, 사족보행 로봇, AMR 등 다양한 형태 지원 |
활용 기업: ADATA, UCR, Foxlink
Isaac Lab-Arena
CES 2026에서 공개된 Isaac Lab-Arena는 오픈소스 시뮬레이션 프레임워크입니다:
- GitHub에서 오픈소스로 제공
- 다양한 로봇 형태와 환경 시뮬레이션
- GR00T 모델 학습 및 평가 지원
Visual Mapping & Localization (Isaac ROS)
실세계 배포 시 정확한 위치 추정을 위해 CUDA-X visual mapping and localization 라이브러리를 활용합니다:
cuVSLAM (CUDA Visual SLAM)
cuVSLAM은 NVIDIA 가속 Visual SLAM/Odometry 패키지입니다:
| 특징 | 설명 |
|---|---|
| 입력 | 스테레오 카메라 이미지 + IMU |
| 성능 | KITTI 벤치마크 최고 수준 (translation/rotation error) |
| 처리 속도 | Jetson AGX Orin에서 4개 스테레오 카메라 쌍으로 30+ fps |
| 기능 | 맵 생성, 저장, 로드, 로컬라이제이션 |
주요 기능:
- 오프라인 맵핑: 텔레오퍼레이션으로 데이터 수집 후 맵 생성
- 런타임 로컬라이제이션: 생성된 맵 내에서 실시간 위치 추정
- Pure Visual: 스테레오 feature matching만으로 환경 맵핑
WarningcuVSLAM 제한사항
- 트래킹 손실 시 (카메라 가림, 모션 블러) 자동 복구 불가 → 외부 알고리즘 필요
- “납치된 로봇(kidnapped robot)” 문제 미해결
- GNSS, 휠 오도메트리, LiDAR 등 다른 센서와의 Kalman Filter 업데이트 미지원
cuVGL (Visual Global Localization)
cuVGL은 초기 위치를 모르거나 로컬라이제이션을 잃었을 때 전역 위치를 찾는 도구입니다:
flowchart LR
A[로봇 시작/트래킹 손실] --> B[cuVGL]
B --> C[기존 맵에서 전역 위치 찾기]
C --> D[공유 글로벌 프레임에서 동작]
맵 생성 워크플로우
Visual Navigation을 위한 세 가지 맵을 생성해야 합니다:
flowchart TB
A[스테레오 카메라 데이터 수집] --> B[Rectified Stereo Images]
B --> C[cuVGL Map 생성]
B --> D[cuVSLAM Map 생성]
B --> E[Occupancy Grid Map 생성]
C --> F[Isaac ROS Perceptor]
D --> F
E --> F
F --> G[Visual Navigation]
| 맵 종류 | 용도 | 생성 도구 |
|---|---|---|
| cuVGL Map | 전역 로컬라이제이션 | cuVGL |
| cuVSLAM Map | 실시간 SLAM/Odometry | cuVSLAM |
| Occupancy Grid Map | 장애물 회피, 경로 계획 | Isaac ROS |
로컬라이제이션 실행
Terminal
# 1. 맵 로드 및 로컬라이제이션 시작 (ROS2 서비스)
ros2 service call /visual_slam/localize_in_map \
isaac_ros_visual_slam_interfaces/srv/LocalizeInMap \
"{map_file_path: '/path/to/cuvslam_map', prior_pose: {position: {x: 0, y: 0, z: 0}}}"
# 2. cuVSLAM 노드 실행
ros2 launch isaac_ros_visual_slam isaac_ros_visual_slam.launch.py
# 3. cuVGL 전역 로컬라이제이션 (트래킹 손실 시)
ros2 launch isaac_ros_visual_slam isaac_ros_visual_slam_cuvgl.launch.pyIsaac ROS Perceptor
Isaac ROS Perceptor는 위의 모든 맵 레이어를 통합하여 비전 기반 내비게이션을 제공합니다:
- cuVSLAM map + cuVGL map + Occupancy map + 실시간 카메라 데이터
- LiDAR 없이 순수 비전 기반 내비게이션 가능
- Nav2와 통합 지원
빠른 시작 가이드
환경 설정
저장소 클론
공식 튜토리얼 구조
Isaac-GR00T 저장소의 getting_started/ 폴더에서 단계별 학습이 가능합니다:
| 순서 | 파일명 | 내용 |
|---|---|---|
| 0 | 0_load_dataset.ipynb |
LeRobot 포맷 데이터 로드 |
| 1 | 1_gr00t_inference.ipynb |
사전학습 모델로 추론 실행 |
| 2 | 2_finetuning.ipynb |
파인튜닝으로 전문가 모델 생성 |
| 3 | 3_0_new_embodiment_finetuning.md |
새로운 로봇에 적용하기 |
| 4 | 4_deeper_understanding.md |
아키텍처 심층 이해 |
Policy Server 활용
서버 시작
클라이언트 연결
GR00T는 ZeroMQ 기반 서버-클라이언트 아키텍처를 제공합니다:
데이터 준비: LeRobot 포맷
GR00T LeRobot 데이터 구조
my_robot_dataset/
├── meta/
│ ├── episodes.jsonl # 에피소드 메타데이터
│ ├── modality.json # ⭐ GR00T 전용 (필수!)
│ ├── info.json # 데이터셋 정보
│ ├── tasks.jsonl # 태스크 설명
│ ├── stats.json # 통계 정보
│ └── relative_stats.json # 상대 통계
├── videos/
│ └── chunk-000/
│ └── observation.images.ego_view/
│ ├── episode_000000.mp4
│ └── episode_000001.mp4
└── data/
└── chunk-000/
├── episode_000000.parquet
└── episode_000001.parquet
Warningmodality.json 필수!
GR00T LeRobot은 표준 LeRobot v2와 호환되지만, meta/modality.json 파일이 반드시 필요합니다. 이 파일은 state와 action의 세부 구조를 정의합니다.
modality.json 예시
데이터 수집 권장사항
| 항목 | 권장 사항 |
|---|---|
| 최소 샘플 수 | 50개 이상 |
| 카메라 설정 | 수집 시 카메라 이름 정확히 기록 (파인튜닝에서 참조) |
| 데이터 형식 | LeRobot v2 호환 |
| 어노테이션 | coarse-grained, fine-grained 다중 채널 지원 |
파인튜닝 가이드
기본 파인튜닝
새로운 로봇에 적용 (New Embodiment)
- 데이터 준비: LeRobot 포맷으로 변환
- Embodiment 설정: 로봇의 관절 구조, 카메라 구성 정의
- 파인튜닝 실행: 공식 튜토리얼
3_0_new_embodiment_finetuning.md참조
Hugging Face 통합
NVIDIA는 Hugging Face와 협력하여 LeRobot 프레임워크와 GR00T를 통합했습니다:
- 비싼 하드웨어 없이도 로봇 학습 실험 가능
- NVIDIA의 260만 로보틱스 개발자 + Hugging Face의 1,300만 AI 빌더 연결
실제 로봇 배포
Policy API 사용
ROS2 연동 예시
import rclpy
from sensor_msgs.msg import Image
from gr00t.policy import Gr00tPolicy
class GR00TNode:
def __init__(self):
self.policy = Gr00tPolicy.from_pretrained("nvidia/GR00T-N1.6-3B")
self.sub = self.create_subscription(Image, '/camera/rgb', self.callback, 10)
def callback(self, msg):
rgb = self.bridge.imgmsg_to_cv2(msg)
action = self.policy.predict({
"image": rgb,
"instruction": "Navigate to the target location"
})
self.send_to_robot(action)산업 채택 현황
GR00T N1.6을 평가 중인 주요 기업들:
| 분야 | 기업 |
|---|---|
| 휴머노이드 로봇 | Unitree, Agibot, Mentee Robotics, Neura Robotics |
| 산업용 로봇 | Franka Robotics, Techman Robot, Solomon |
| 가전/서비스 | LG Electronics, AeiROBOT |
| 연구 기관 | UCR, Lightwheel |
활용 및 기대 효과
| 대상 | 기대 효과 |
|---|---|
| 연구자/개발자 | Hugging Face 및 GitHub를 통한 오픈 모델 접근 |
| 로봇 제조사 | 범용적 행동 계획 및 빠른 커스터마이즈 |
| Sim-to-Real 전이 | 최소한의 추가 데이터로 실제 적용 가능 |
| 물리 추론 능력 | 명령 → 행동 계획 실행 고도화 |
Tip실전 적용 팁
- Zero-shot vs Fine-tuning: 사전학습만으로 기본 태스크 수행 가능하나, 실환경에서는 파인튜닝으로 성능 향상
- 시뮬레이션 신뢰성: Isaac Sim + Newton Physics Engine 세팅이 Sim-to-Real 전이에 중요
- 데이터 믹스: 실제 로봇 데이터 + 시뮬레이션 데이터 혼합 사용 권장
- 오버피팅 주의: N1.6은 빠르게 수렴하므로, 적절한 early stopping 필요
- 최소 50개 샘플: 새로운 태스크 학습 시 최소 50개 이상의 데모 데이터 권장