📝NVIDIA Cosmos 3: 추론·월드·액션 모델로 Physical AI 개발하기
원문: Develop Physical AI Reasoning, World, and Action Models with NVIDIA Cosmos 3 — NVIDIA Developer Blog (Asawaree Bhide, Alexander Schwarz · 2026-05-31)
이 글은 위 블로그를 섹션 구성 그대로 따라 한국어로 옮기고 정리한 것입니다. 본문의 그림/영상은 원문 자산 링크로 삽입했으며, 핵심 표현은 짧게 인용했습니다.

Cosmos 3로 생성한 임바디드(휴머노이드) 로봇의 망치질 동작
들어가며
NVIDIA Cosmos 3 는 물리적 추론(physical reasoning), 월드 생성(world generation), 액션 생성(action generation)을 하나의 오픈 모델에 결합한 프런티어 파운데이션 모델입니다. 로봇, 자율주행 차량, 산업 자동화처럼 물리 세계와 직접 상호작용하는 Physical AI 개발을 겨냥합니다.
기존 Cosmos 라인업이 추론(Cosmos Reason), 예측/월드 생성(Cosmos Predict), 변환/증강(Cosmos Transfer)을 별개 모델로 제공했다면, Cosmos 3는 이 능력들을 단일 모델로 통합했다는 점이 가장 큰 변화입니다.
“물리적 추론, 월드 생성, 액션 생성을 하나의 오픈 모델 안에 결합한다(combines physical reasoning, world generation, and action generation within a single open model).”

Figure 1. Cosmos 3가 자율주행 도메인에서 생성한 영상 클립 — 교차로에서 다른 차량이 지나간 뒤 좌회전하는 장면
Cosmos 3의 새로운 점
Cosmos 3의 핵심은 Mixture-of-Transformers(MoT) 아키텍처이며, 두 개의 “타워(tower)”로 구성됩니다.
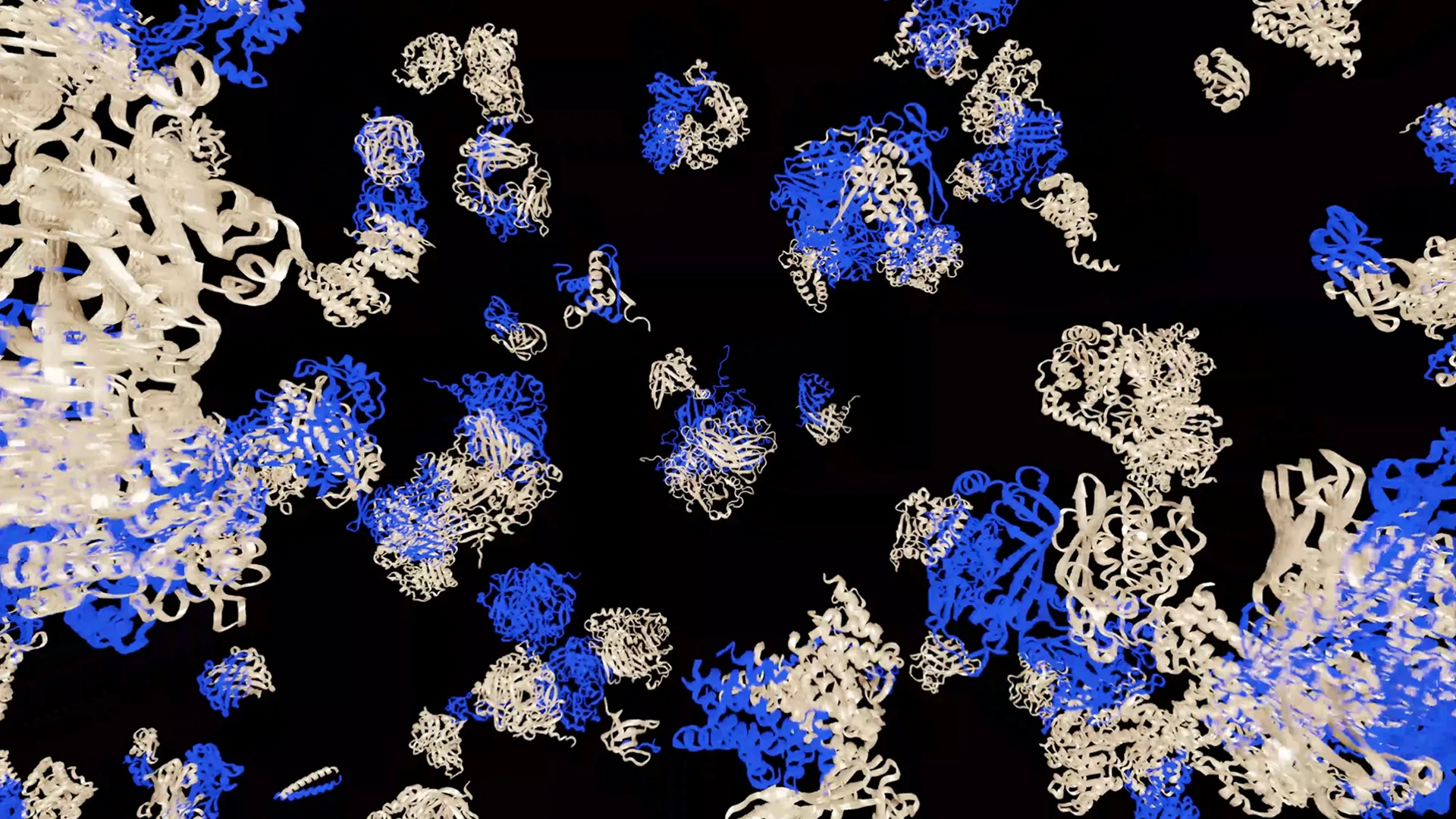
Figure 3. Cosmos 3 아키텍처 — Reasoner 타워와 Generator 타워, 그리고 둘 사이의 정보 흐름
- Reasoner 타워(추론기): 이미지·영상·텍스트·오디오·액션 등 멀티모달 관측을 해석하는 비전-언어 모델(VLM). 자기회귀(autoregressive) 구조로 “무슨 일이 벌어지고 있는가, 다음에 무엇을 해야 하는가”를 추론합니다.
- Generator 타워(생성기): 확산(diffusion) 기반 프로세스로 물리적으로 타당한 영상과 액션을 생성합니다. 즉 “그 다음 장면/행동이 실제 물리에 맞게 어떻게 펼쳐질지”를 만들어냅니다.
직관적으로 보면, Reasoner는 “이해하고 판단하는 뇌”, Generator는 “상상하고 행동을 만들어내는 손과 눈” 에 해당하며, 두 타워가 같은 모델 안에서 정보를 주고받습니다. 그래서 하나의 모델이 추론(reasoning) → 미래 예측(world model) → 행동 생성(action model) 을 끊김 없이 이어갈 수 있습니다.
적절한 모델 크기 선택하기
Cosmos 3는 두 가지 규모로 제공됩니다.
| 모델 | 파라미터 | 타깃 환경 |
|---|---|---|
| Cosmos 3 Nano | 16B | 효율적 추론에 최적화 — 워크스테이션급 컴퓨트(예: NVIDIA RTX PRO 6000) |
| Cosmos 3 Super | 64B | 최대 품질·성능 — 데이터센터(NVIDIA Hopper·Blackwell GPU) 배포 |
Nano는 현장/엣지·워크스테이션에서 가볍게 돌리는 용도, Super는 데이터센터에서 최고 품질이 필요한 용도로 나뉩니다.
지원 모달리티
Cosmos 3는 입력·출력 모달리티의 조합에 따라 다양한 Physical AI 응용을 한 모델로 커버합니다.
Table 1. Cosmos 3가 응용별로 지원하는 입출력 모달리티
| 입력(Input) | 출력(Output) | 응용 |
|---|---|---|
| 텍스트 | 이미지 | 물리적으로 타당한 이미지 생성 |
| 텍스트 / 영상 | 영상 | 엣지 케이스·미래 예측을 위한 월드 모델 |
| 텍스트 / 이미지 / 영상 | 텍스트 | VLM 추론 |
| 액션 / 영상 / 텍스트 | 영상 | 액션 조건부(action-conditioned) 월드 모델 |
| 영상 / 텍스트 | 영상 / 액션 | 월드·비전-언어-액션 모델, 로봇 정책(robot policy) |
특히 마지막 두 행이 중요합니다. 액션을 조건으로 미래 영상을 생성하거나(주어진 행동을 했을 때 세상이 어떻게 변할지 상상), 영상·텍스트로부터 직접 액션을 생성(로봇 정책)할 수 있어, 월드 모델과 행동 정책이 한 모델 안에서 맞물립니다.
Physical AI를 위한 오픈 데이터셋
NVIDIA는 Hugging Face에 6종의 오픈 데이터셋을 함께 공개했습니다. Physical AI 모델의 사전학습·후학습·평가에 바로 쓸 수 있습니다.
1. Embodied Robot Scenes (임바디드 로봇 장면)

Figure 4. Embodied Robot Scenes 데이터셋의 조작(manipulation) 예시
다양한 환경에서 여러 휴머노이드 로봇이 조작 과제를 수행하는 영상 모음입니다.
2. Physical Interaction Scenes (물리 상호작용 장면)
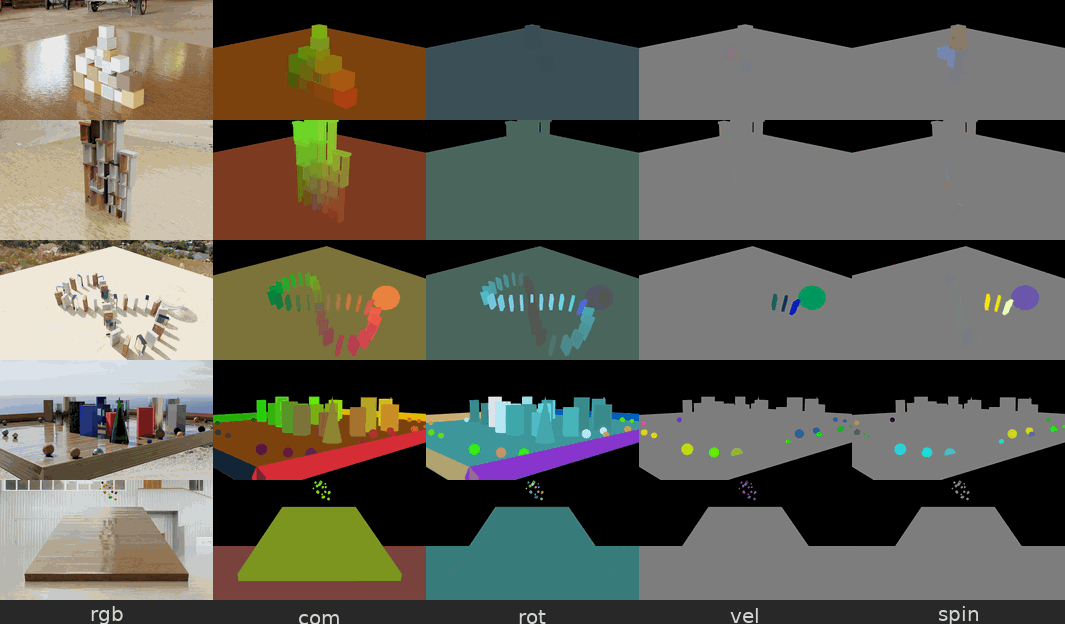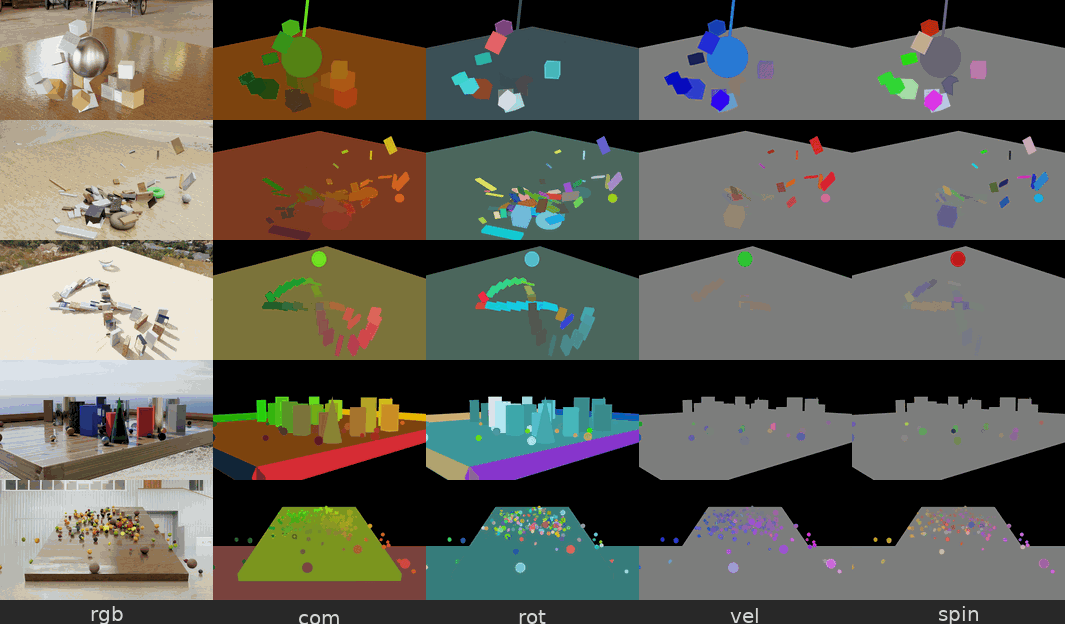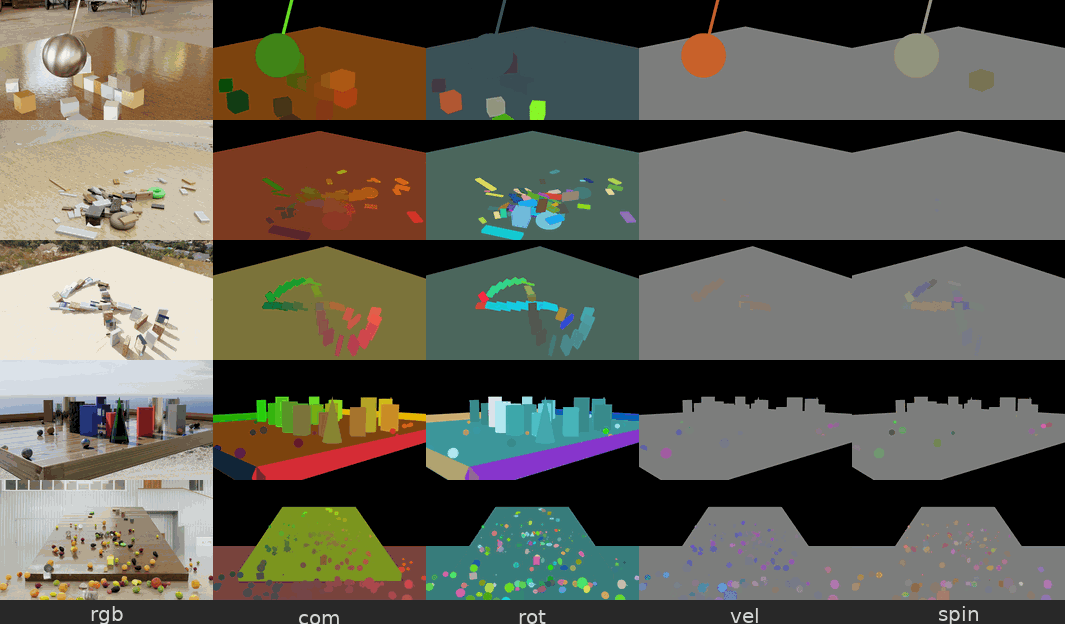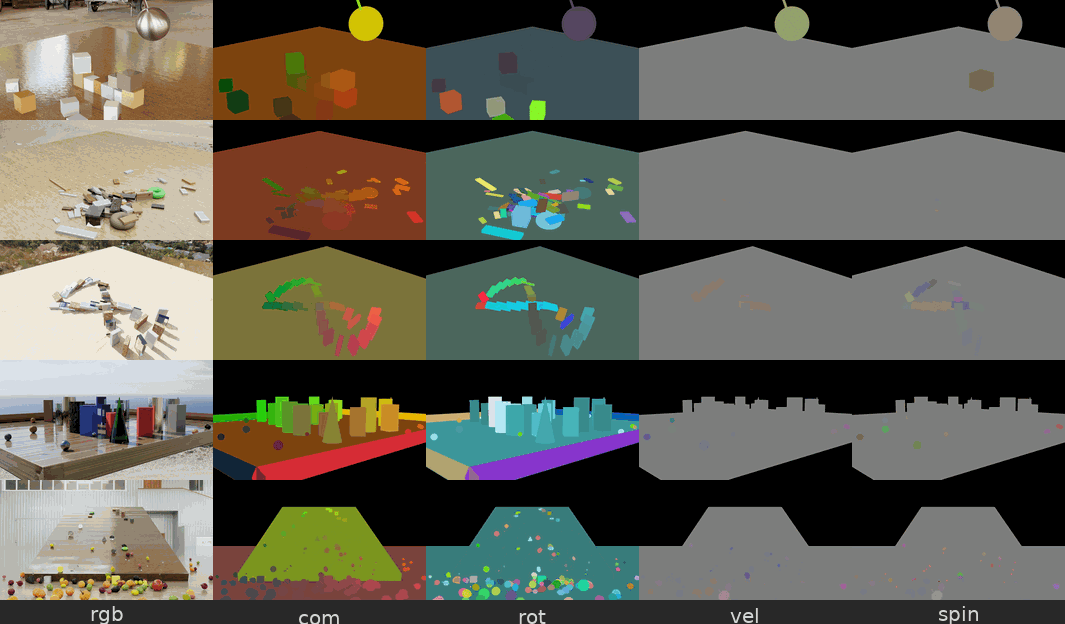
Figure 5. Physical Interaction Scenes 데이터셋 예시 — 파괴추(wrecking ball), 무너지는 탑, 도미노 등
파괴추가 물체를 때리거나, 장난감 탑이 무너지거나, 도미노가 쓰러지는 등의 물리 시뮬레이션 장면입니다. 각 장면에는 물체별 속도(velocity), 질량중심 변위(center-of-mass displacement), 프레임별 의미 분할(semantic segmentation) 같은 정답 물리 주석(ground-truth physics annotation) 이 함께 제공됩니다.
3. Spatial Reasoning (공간 추론)

Figure 6. Spatial Reasoning 데이터셋 예시 — 주방·복도·사무실 장면과 질문-답변 쌍
주방·복도·사무실·다용도실 등 실내 장면과 함께 질문-답변(Q&A) 쌍을 제공합니다. 예: “커피 테이블은 소파에서 얼마나 떨어져 있나?”, “로봇이 서재로 가는 최적 경로는?”
4. Digital Human Scenes (디지털 휴먼 장면)

Figure 7. Digital Human Scenes 데이터셋 예시 — 다양한 실내외 환경 속 디지털 휴먼
다양한 실내외 환경에서 서 있거나 움직이는 디지털 휴먼 영상으로, 인물 외형·동작·장면 맥락·조명·카메라 모션이 폭넓게 포함됩니다.
5. Autonomous Driving Scenarios (자율주행 시나리오)

Figure 8. Autonomous Driving Scenarios 데이터셋 예시 — 다양한 날씨·조명·주행 행동의 에고뷰 주행
자율주행 차량의 에고뷰(ego-view) 주행 영상으로, 다양한 날씨·조명 조건과 차선 변경·보행자 상호작용 같은 주행 행동을 담습니다.
6. Warehouse Operations Scenes (창고 운영 장면)

Figure 9. Warehouse Operations Scenes 데이터셋 예시 — 지게차·안전 사고 시나리오
여러 카메라 각도에서 본 시뮬레이션 창고 장면으로, 지게차가 사람·물체와 충돌하거나 사람이 상자를 떨어뜨리는 등 안전(safety) 관련 시나리오를 포함합니다.
NVIDIA Cosmos 휴먼 평가 벤치마크
Physical AI 모델은 “영상이 그럴듯한가”를 넘어 물리적으로 타당한가를 평가해야 합니다. NVIDIA는 이를 위해 Cosmos Human Evaluation Benchmark 를 도입해, 사람 평가자가 생성 결과의 물리적 타당성·일관성을 판정하도록 했습니다.

Figure 2. Cosmos 3로 생성한 창고 안전 데이터 — 복도의 상자 더미에서 작은 폭발과 연기가 발생하는 장면
위와 같은 안전 사고(폭발·화재) 장면은 현실에서 수집하기 위험하고 비싸기 때문에, 월드 모델로 엣지 케이스를 합성하는 것이 특히 가치가 큽니다.
벤치마크 결과
추론(Reasoning)
- Cosmos 3 Super 는 VANTAGE-Bench의 32B 등급에서 선두.
- Cosmos 3 Nano 는 8B 등급에서 선두.
- Traffic Anomaly Reasoning (TAR) 리더보드(AI City Challenge 2026, Track 3)에서 1위.
생성(Generation)
- PAI-Bench, R-Bench Physics-IQ, RoboLab 에서 오픈소스 SOTA.
- Artificial Analysis의 text-to-image 및 image-to-video 리더보드 선두.
- Physics-IQ 실세계 영상 벤치마크에서 최상위 성능.

Cosmos 3 자율주행 도메인 생성 예시(Alpamayo)
정리: 추론(VLM)과 생성(월드 모델) 양쪽 모두에서 동급 최강을 주장한다는 점이 핵심입니다. 특히 “물리 IQ”를 재는 Physics-IQ류 벤치마크에서의 우위는, 단순히 예쁜 영상이 아니라 물리 법칙을 따르는 영상을 만든다는 주장의 근거입니다.
학습 레시피 (Training Recipes)
Cosmos 3는 커스텀 데이터로 손쉽게 적응시킬 수 있도록 학습 레시피를 제공합니다.
- 지도 미세조정(SFT, Supervised Fine-Tuning): 사용자 보유 영상 데이터셋으로 모델을 특화.
- 액션 후학습(Action post-training): 순방향 동역학(forward dynamics), 역방향 동역학(inverse dynamics), 정책 생성(policy generation) 용도로 후학습.
- 코드와 설정(config)은 GitHub에 공개.

Video 1. Cosmos 3 후학습(post-training) 튜토리얼 — 임바디드 로봇 학습 예시
액션 후학습의 세 갈래를 직관적으로 풀면 — forward dynamics(이 행동을 하면 세상이 어떻게 변할까?), inverse dynamics(이 변화를 만들려면 어떤 행동이 필요했나?), policy(목표를 위해 지금 무슨 행동을 할까?)입니다. 월드 모델 하나로 이 셋을 모두 후학습할 수 있다는 것이 강점입니다.
NVIDIA NIM 마이크로서비스로 배포하기
Cosmos 3는 NVIDIA NIM 마이크로서비스로 손쉽게 배포할 수 있습니다.
- Cosmos 3 Reasoner NIM: 현재 제공.
- Cosmos 3 Generator NIM: 곧 제공 예정.
- 사용에는 NVIDIA NGC API 키가 필요합니다.
배포는 도커 한 줄로 시작합니다(아래는 Nano 기준, super로 바꾸면 대형 모델).
추론 최적화
- 양자화(Quantization): BF16, FP8, NVFP4(4-bit) 지원 — NVFP4로 최대 2배 속도 향상.
- vLLM 서빙 스택으로 처리량(throughput) 향상.
- Efficient Video Sampling (EVS): 청크(chunk) 수준에서 영상 토큰 수를 줄여 추론 효율 개선.

Video 2. Cosmos Reasoner NIM 사용 튜토리얼
시작하기 (Get Started)
- Hugging Face: 모델 체크포인트 —
nvidia/Cosmos3-Nano,nvidia/Cosmos3-Super - GitHub: github.com/nvidia/Cosmos — 코드·학습 스크립트·배포 도구
- Build 플랫폼: Cosmos 3 Nano Reasoner 및 Cosmos 3 Nano 모델 체험 제공
- 문서: docs.nvidia.com/nim/vision-language-models — 배포 상세
- 커뮤니티: Discord에서 이슈·기여 가능
정리 — 무엇이 중요한가
- 하나의 오픈 모델이 물리적 추론 + 월드 생성 + 액션 생성을 통합 → 기존 Reason/Predict/Transfer의 분산 구조를 합침.
- MoT 2-타워 구조: 자기회귀 Reasoner(VLM) + 확산 Generator(영상·액션).
- 두 가지 규모: Nano(16B, 워크스테이션) / Super(64B, 데이터센터).
- 6종 오픈 데이터셋 + 휴먼 평가 벤치마크 로 물리적 타당성 중심 평가.
- 추론·생성 양쪽에서 SOTA 주장(VANTAGE-Bench, TAR, PAI-Bench, Physics-IQ, Artificial Analysis 등).
- SFT·액션 후학습 레시피 + NIM 배포(NVFP4 양자화로 최대 2배, vLLM, EVS).
로봇·자율주행·산업 자동화에서 월드 모델 기반 데이터 생성 + 추론 + 정책을 한 스택으로 가져가려는 팀에게, Cosmos 3는 “오픈 모델로 Physical AI 파이프라인을 한 번에 깔 수 있다”는 제안을 던집니다. (단, 본 글의 수치·성능은 NVIDIA 발표 기준이므로, 실제 도메인 적용 시 자체 벤치마크 검증이 필요합니다.)