📃Imitating Animals
- 🐾 본 논문은 실제 동물 모션 데이터를 모방하여 다족 로봇이 다양하고 민첩한 locomotion skills를 학습할 수 있게 하는 imitation learning framework를 제안합니다.
- 🛠️ 이 framework는 inverse-kinematics를 통한 motion retargeting, reference motion을 활용한 Reinforcement Learning 기반 정책 훈련, 그리고 information bottleneck이 적용된 latent space를 통한 sample-efficient domain adaptation으로 sim-to-real transfer를 가능하게 합니다.
- ✨ 18-DoF quadruped robot Laikago에 적용하여 다양한 dynamic gaits 및 behaviors를 성공적으로 학습시켰으며, adaptive policies는 실제 환경에서 non-adaptive 방식보다 우수한 성능과 robustness를 보였습니다.
🔍 Ping Review
🔍 Ping — A light tap on the surface. Get the gist in seconds.
본 논문은 로봇이 실제 동물의 움직임을 모방하여 민첩한 이동(locomotion) 기술을 학습할 수 있는 프레임워크를 제안합니다. 기존 수동 제어기 설계의 복잡성과 강화 학습(RL)의 보상 함수 설계 및 sim-to-real 전이 문제를 해결하는 데 중점을 둡니다.
I. 프레임워크 개요 (Framework Overview)
이 프레임워크는 세 가지 주요 단계로 구성됩니다:
- 모션 리타겟팅 (Motion Retargeting): 동물에서 기록된 모션 캡처(mocap) 데이터를 로봇의 형태에 맞게 변환합니다.
- 모션 모방 (Motion Imitation): 리타겟팅된 모션 데이터를 사용하여 시뮬레이션 환경에서 로봇 모델이 해당 모션을 모방하도록 강화 학습을 통해 정책(policy)을 훈련합니다.
- 도메인 적응 (Domain Adaptation): 시뮬레이션에서 훈련된 정책을 실제 로봇에 효율적으로 전이시키기 위한 기술을 적용합니다.
II. 모션 리타겟팅 (Motion Retargeting)
동물의 모션 데이터는 로봇과 형태가 다르기 때문에 역기구학(inverse-kinematics, IK)을 사용하여 로봇에 재매핑(retargeting)됩니다.
- 동물의 특정 키포인트(발, 엉덩이 등)를 로봇의 해당 키포인트에 매핑합니다.
- 각 타임스텝에서 소스 모션의 3D 키포인트 위치 \hat{x}_i(t)를 추적하도록 로봇의 포즈 q_t 시퀀스 q_{0:T}를 계산합니다.
- 최적화 문제는 다음과 같습니다: \arg \min_{q_{0:T}} \sum_t \sum_i ||\hat{x}_i(t) - x_i(q_t)||^2 + (\bar{q} - q_t)^T W(\bar{q} - q_t) 여기서 \bar{q}는 기본 포즈, W는 정규화 계수 행렬입니다.
III. 모션 모방 (Motion Imitation)
모션 모방은 강화 학습 문제로 공식화됩니다. 정책 \pi는 환경 상태 s_t와 모방할 목표 모션 g_t를 입력으로 받아 행동 a_t를 샘플링합니다.
정책 입력: 상태 s_t = (q_{t-2:t}, a_{t-3:t-1})는 이전 세 타임스텝의 로봇 포즈(q)와 행동(a)으로 구성됩니다. 포즈 특징은 IMU(Inertial Measurement Unit)를 통해 얻은 루트 방향(root orientation) 및 각 관절의 로컬 회전(local rotations)을 포함합니다. 루트 위치는 실제 배포 시 추정 문제를 피하기 위해 제외됩니다.
목표 입력: g_t = (\hat{q}_{t+1}, \hat{q}_{t+2}, \hat{q}_{t+10}, \hat{q}_{t+30})는 참조 모션에서 약 1초 동안의 미래 네 개 타임스텝의 목표 포즈를 나타냅니다.
행동 출력: a_t는 각 관절의 PD 제어기(PD controller)에 대한 목표 회전을 지정합니다. 부드러운 움직임을 위해 저역 통과 필터(low-pass filter)를 거칩니다.
보상 함수 (Reward Function): 정책이 참조 모션의 목표 포즈 시퀀스 (\hat{q}_0, \hat{q}_1, ..., \hat{q}_T)를 추적하도록 유도합니다. 총 보상 r_t는 여러 항의 가중 합으로 구성됩니다: r_t = w_p r_{pt} + w_v r_{vt} + w_e r_{et} + w_{rp} r_{rpt} + w_{rv} r_{rvt}
- 자세 보상 (Pose Reward) r_{pt}: 로봇 관절의 로컬 회전 q_j^t가 참조 모션의 \hat{q}_j^t와 유사하도록 장려합니다: r_{pt} = \exp \left[ -5 \sum_j ||\hat{q}_j^t - q_j^t||^2 \right]
- 속도 보상 (Velocity Reward) r_{vt}: 관절 각속도 \dot{q}_j^t가 참조 모션의 \hat{\dot{q}}_j^t와 유사하도록 합니다: r_{vt} = \exp \left[ -0.1 \sum_j ||\hat{\dot{q}}_j^t - \dot{q}_j^t||^2 \right]
- 말단 효과기 보상 (End-effector Reward) r_{et}: 말단 효과기(end-effector)의 3D 상대 위치 x_e^t가 참조 모션의 \hat{x}_e^t를 추적하도록 합니다: r_{et} = \exp \left[ -40 \sum_e ||\hat{x}_e^t - x_e^t||^2 \right]
- 루트 자세 및 속도 보상 (Root Pose and Velocity Reward) r_{rpt}, r_{rvt}: 로봇의 루트(torso)의 글로벌 위치 및 선형/각속도가 참조 모션과 유사하도록 합니다: r_{rpt} = \exp [-20||\hat{x}_{\text{root}}^t - x_{\text{root}}^t||^2 - 10||\hat{q}_{\text{root}}^t - q_{\text{root}}^t||^2] r_{rvt} = \exp [-2||\hat{\dot{x}}_{\text{root}}^t - \dot{x}_{\text{root}}^t||^2 - 0.2||\hat{\dot{q}}_{\text{root}}^t - \dot{\dot{q}}_{\text{root}}^t||^2]
IV. 도메인 적응 (Domain Adaptation)
시뮬레이션과 실제 환경 간의 동역학적 불일치(dynamics discrepancies)를 해결하기 위해 다음과 같은 방법을 사용합니다.
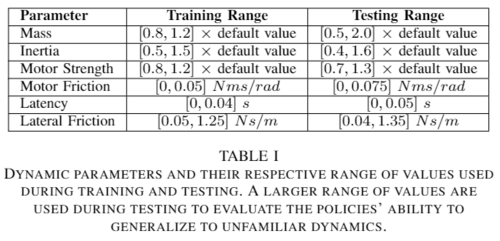
A. 도메인 무작위화 (Domain Randomization): 훈련 중 동역학 파라미터(예: 질량, 관성, 마찰, 모터 강도, 지연 시간)를 무작위로 변경하여 정책이 다양한 동역학에 대해 견고(robust)해지도록 합니다.
B. 도메인 적응 (Latent Space Method): 강건성을 넘어 새로운 환경에 적응할 수 있는 전략을 학습하는 것이 목표입니다. 동역학 파라미터 \mu를 잠재 임베딩(latent embedding) z로 인코딩하는 stochastic encoder E(z|\mu)를 사용하며, 정책 \pi(a|s, g, z)는 이 z에 조건화됩니다.
- 정보 병목 (Information Bottleneck): 정책이 실제 시스템의 동역학에 과적합(overfit)되는 것을 방지하기 위해, 동역학 파라미터 M과 인코딩 Z 간의 상호 정보량(mutual information) I(M, Z)에 상한 I_c를 둡니다. 이 제약 조건은 variational upper bound를 사용하여 DKL(Kullback-Leibler divergence)로 근사됩니다.
- 최적화 목표는 정보 정규화된(information-regularized) 형태로 표현됩니다: \arg \max_{\pi,E} E_{\mu \sim p(\mu)} E_{z \sim E(z|\mu)} E_{\tau \sim p(\tau|\pi,\mu,z)} \left[ \sum_{t=0}^{T-1} \gamma^t r_t \right] - \beta E_{\mu \sim p(\mu)} [D_{KL}[E(\cdot|\mu)||\rho(\cdot)]] 여기서 \beta \ge 0는 라그랑주 승수(Lagrange multiplier)로, 강건성(robustness)과 적응성(adaptability) 사이의 균형을 조절합니다. \beta가 클수록 강건하지만 비적응적인 정책이, 작을수록 덜 강건하지만 적응적인 정책이 생성됩니다.
C. 실세계 전이 (Real World Transfer): 실제 로봇에 정책을 적용하기 위해, 실제 동역학 하에서 가장 높은 리턴(return)을 제공하는 최적의 인코딩 z^*를 직접 탐색합니다. z^* = \arg \max_z E_{\tau \sim p^*(\tau|\pi,z)} \left[ \sum_{t=0}^{T-1} \gamma^t r_t \right] 이 z^*를 찾기 위해 AWR(Advantage-Weighted Regression)을 사용합니다.
- 초기 검색 분포 \omega_0(z) = \mathcal{N}(0, I)에서 인코딩 z_k를 샘플링합니다.
- z_k에 조건화된 정책 \pi로 실제 로봇에서 에피소드를 실행하고 리턴 R_k를 기록합니다.
- 이전 샘플과 리턴을 포함하는 리플레이 버퍼(replay buffer) D를 업데이트합니다.
- D의 샘플 중 더 큰 장점(advantage)을 가진 샘플에 더 높은 가능도(likelihood)를 부여하는 새로운 분포 \omega_{k+1}를 학습합니다. 이는 \exp\left(\frac{1}{\alpha}(R_i - \bar{v})\right)로 각 샘플 z_i의 가중치를 부여하여 기울기 하강(gradient descent)으로 \omega_k(z)를 점진적으로 업데이트함으로써 수행됩니다.
V. 실험 결과 (Experimental Results)
18 자유도(DoF) 사족보행 로봇인 Laikago를 사용하여 다양한 동적 이동 기술을 학습하고 평가합니다.
- 학습된 기술: 페이싱(pacing), 트로팅(trotting), 역방향 보행, 제자리 걸음(In-Place Steps), 옆걸음(Side-Steps), 회전(Turn), 홉-턴(Hop-Turn) 등 다양한 보행 패턴과 동적 기술을 학습했습니다. Dog Trot 정책은 1.08m/s, 역방향 트로팅은 1.20m/s에 도달하여 제조사 수동 제어기(0.84m/s)보다 빠른 속도를 보여주었습니다.
- 도메인 적응 효과: “No Rand” (무작위화 없이 훈련), “Robust” (무작위화만 적용), “Adaptive” (본 논문 제안 적응 방식) 정책을 비교했습니다.
- 실제 로봇에 배포 시, “Adaptive” 정책이 대부분의 기술에서 “No Rand” 및 “Robust” 정책보다 뛰어난 성능을 보였습니다. 특히 Dog Pace, Dog Spin과 같은 동적 기술에서 “Robust” 정책은 자주 넘어졌지만 “Adaptive” 정책은 더 일관되게 기술을 수행했습니다.
- “Adaptive” 정책은 다른 방법들보다 균형을 더 오래 유지할 수 있었고, 많은 경우 넘어지지 않고 최대 에피소드 길이에 도달했습니다.
- 훈련 시 사용된 범위보다 넓은 동역학 파라미터 범위(out-of-distribution)에서 “Adaptive” 정책이 더 높은 리턴을 달성하며, 익숙하지 않은 동역학에 대한 더 나은 일반화(generalization) 능력을 보여주었습니다.
- 실제 시스템에서 AWR을 통한 적응은 일반적으로 적은 수의 에피소드(약 50회)로 새로운 환경에 적응할 수 있음을 확인했습니다.
- 정보 병목 효과: 정보 병목의 계수 \beta의 영향을 분석했습니다.
- \beta 값이 클수록 정책은 동역학 파라미터에 대한 의존도가 낮아져, 적응 전 성능(robustness)은 향상되지만 적응 후 성능 향상 폭(adaptability)은 작아집니다.
- \beta 값이 작을수록 덜 강건하지만 더 적응적인 정책이 생성됩니다.
- 본 연구에서는 \beta=10^{-4}가 강건성과 적응성 사이의 좋은 균형을 제공함을 발견했습니다. 정보 병목이 없는(No IB) 정책보다 정보 제약(information-constrained) 정책이 적응 전후 모두 더 나은 성능을 보였습니다.
VI. 결론 및 향후 연구 (Discussion and Future Work)
이 프레임워크는 다양한 동물 모션 데이터를 모방하여 사족보행 로봇이 민첩한 이동 기술을 학습하고 이를 실제 세계로 효율적으로 전이시키는 데 성공했습니다. 하지만 하드웨어 및 알고리즘적 한계로 인해 아직 큰 점프나 달리기와 같은 더 역동적인 행동은 학습하지 못했습니다. 향후 연구는 학습된 제어기의 안정성 향상, 더 다양한 행동 데이터 소스(예: 비디오 클립)로부터 학습하는 것을 목표로 합니다.
🔔 Ring Review
🔔 Ring — An idea that echoes. Grasp the core and its value.
서론
RL로 학습한 에이전트는 시뮬레이션에서는 좋은 결과를 보이지만, 실로봇에 올리면 부자연스럽거나 위험·실행 불가능한 행동 을 보이기 쉽습니다. 그래서 자연스러운 질문이 생깁니다 — 동물의 모션을 직접 모방하면, 더 적은 노력으로 더 민첩한 컨트롤러를 만들 수 있지 않을까?
reference motion을 쓰면 스킬별 보상 함수 설계의 부담 이 크게 줄어듭니다. 다만 시뮬레이션에서 학습한 정책을 실세계로 옮기려면 sim-to-real 갭을 넘어야 하는데, 저자들은 sample-efficient adaptation 기법으로 정책의 거동을 미세조정합니다. 대상 로봇은 Laikago 4족 로봇이며, 다양한 보행 gait와 dynamic hop·turn을 다룹니다.
이 논문의 한 줄 요약: 동물 mocap을 모방 해 스킬별 보상 설계 없이 다양한 민첩 보행을 학습하고, latent space domain adaptation 으로 시뮬레이션→실로봇 전이를 효율화한다.
관련 연구와 차별점
- Trajectory optimization / MPC: 컨트롤러 설계의 수작업을 줄였지만, 보행 시스템의 고차원·복잡 동역학 때문에 축약 모델(reduced-order model) 에 의존했습니다.
- Motion imitation: 보행 로봇 적용은 주로 상체 위주·정적 하체 행동에 국한됐고 균형 제어는 별도 전략에 맡겼습니다. 최근 RL 기반 motion imitation은 시뮬레이션에서 acrobatic 스킬을 잘 학습합니다.
- Sim-to-real: 정확한 시뮬레이터 구축, 실데이터로 시뮬레이터 보정, domain randomization(학습 중 동역학을 변화시켜 강건성 확보), fine-tuning·meta-learning 같은 적응 기법 등이 있습니다.
차별점(Ours): latent space 방법 을 motion imitation 과 결합합니다. pre-training에서 다양한 시나리오에 효과적인 behavior들의 latent 표현을 학습하고, 새 도메인에서는 latent space를 탐색해 작업을 성공시키는 behavior를 찾습니다. 정교한 스킬별 보상 설계나 system identification에 의존한 이전 방법(Hwangbo et al. ANYmal, Xie et al. Cassie, Yu et al. Darwin OP2)보다 더 다양하고 민첩한 행동 을 실로봇에서 수행합니다.
방법 (Overview)
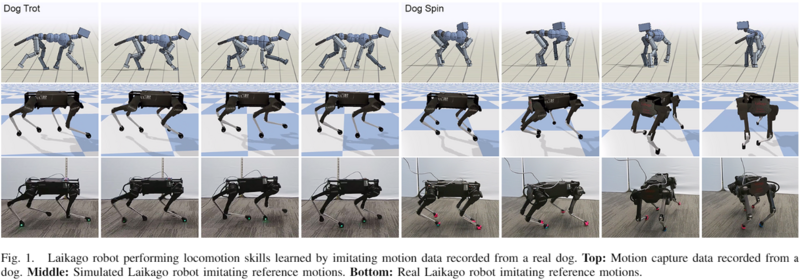
원하는 스킬의 reference motion(실제 동물 mocap 등)을 입력받아, RL로 그 스킬을 실세계에서 재현하는 정책을 합성합니다. 3단계입니다.
- Motion Retargeting: 모션 클립을 원 대상(동물)의 형태에서 로봇 형태로 inverse-kinematics 를 통해 매핑.
- Motion Imitation: retarget된 reference를 시뮬레이션 로봇이 재현하도록 정책 학습. 전이를 위해 domain randomization 적용.
- Domain Adaptation: 학습된 latent dynamics 표현 을 이용해 정책을 실로봇에 sample-efficient하게 적응.
1. Motion Retargeting
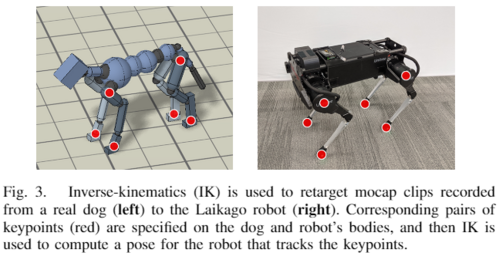
로봇과 모션을 얻은 동물의 형태가 다르므로 IK로 retarget합니다. 키포인트는 발(feet)과 엉덩이(hips) 위치를 씁니다. source 모션이 각 키포인트 i 의 3D 위치 \hat{\mathbf x}_i(t) 를 지정하면, 로봇 자세 \mathbf q_t 에 의해 결정되는 대응 키포인트 \mathbf x_i(\mathbf q_t) 가 이를 추종하도록 자세열 \mathbf q_{0:T} 를 구성합니다. default 자세 \bar{\mathbf q} 에서 크게 벗어나지 않도록 정규화 항(관절별 계수 대각행렬 \mathbf W)을 더합니다.
\underset{\mathbf q_{0:T}}{\arg\min} \sum_t \sum_i \big\lVert \hat{\mathbf x}_i(t) - \mathbf x_i(\mathbf q_t) \big\rVert^2 + (\bar{\mathbf q} - \mathbf q_t)^T \mathbf W (\bar{\mathbf q} - \mathbf q_t)
2. Motion Imitation
표준 RL 목표 J(\pi) = \mathbb E_{\tau\sim p(\tau\mid\pi)}\big[\sum_{t=0}^{T-1}\gamma^t r_t\big] 를 최대화하되, 정책 입력에 모방할 모션을 지정하는 goal \mathbf g_t 를 추가합니다: \pi(\mathbf a_t \mid \mathbf s_t, \mathbf g_t). 정책은 30Hz 로 질의됩니다.
- 상태 \mathbf s_t = (\mathbf q_{t-2:t}, \mathbf a_{t-3:t-1}): 직전 3스텝 자세 + 직전 3 행동. 자세 feature는 root 방향(roll/pitch/yaw)의 IMU 값과 각 관절의 로컬 회전. root 위치는 제외(실세계 배포 시 root 위치 추정 부담 회피).
- goal \mathbf g_t = (\hat{\mathbf q}_{t+1}, \hat{\mathbf q}_{t+2}, \hat{\mathbf q}_{t+10}, \hat{\mathbf q}_{t+30}): reference의 미래 4개 시점 목표 자세(약 1초 범위).
- 행동 \mathbf a_t: 각 관절 PD 컨트롤러의 목표 회전. 부드러운 모션을 위해 PD 목표에 low-pass filter 적용.
보상 함수 는 목표 자세열 추종을 유도하는 5개 항의 가중합입니다.
r_t = w^p r_t^p + w^v r_t^v + w^e r_t^e + w^{rp} r_t^{rp} + w^{rv} r_t^{rv}
w^p=0.5,\ w^v=0.05,\ w^e=0.2,\ w^{rp}=0.15,\ w^{rv}=0.1
각 항(모두 exp 형태):
r_t^p = \exp\Big[-5\sum_j \lVert \hat{\mathbf q}_t^j - \mathbf q_t^j \rVert^2\Big] \quad\text{(pose: 관절 회전)}
r_t^v = \exp\Big[-0.1\sum_j \lVert \hat{\dot{\mathbf q}}_t^j - \dot{\mathbf q}_t^j \rVert^2\Big] \quad\text{(velocity: 각속도)}
r_t^e = \exp\Big[-40\sum_e \lVert \hat{\mathbf x}_t^e - \mathbf x_t^e \rVert^2\Big] \quad\text{(end-effector 위치)}
r_t^{rp} = \exp\big[-20\lVert \hat{\mathbf x}_t^{\text{root}} - \mathbf x_t^{\text{root}} \rVert^2 - 10\lVert \hat{\mathbf q}_t^{\text{root}} - \mathbf q_t^{\text{root}} \rVert^2\big] \quad\text{(root pose)}
r_t^{rv} = \exp\big[-2\lVert \hat{\dot{\mathbf x}}_t^{\text{root}} - \dot{\mathbf x}_t^{\text{root}} \rVert^2 - 0.2\lVert \hat{\dot{\mathbf q}}_t^{\text{root}} - \dot{\mathbf q}_t^{\text{root}} \rVert^2\big] \quad\text{(root velocity)}
3. Domain Adaptation
(A) Domain Randomization. 학습 중 동역학을 변화시켜, 서로 다른 동역학에서 기능하는 전략을 정책이 배우도록 강건성을 높입니다. 다만 모든 환경에 통하는 단일 전략은 없습니다 — 그래서 적응이 필요합니다.
(B) Domain Adaptation (latent + information bottleneck). 시뮬레이션에서 무작위화되는 동역학 파라미터 \boldsymbol\mu \sim p(\boldsymbol\mu) 를 stochastic encoder E 가 latent embedding \mathbf z \sim E(\mathbf z\mid\boldsymbol\mu) 로 인코딩하고, 이를 정책의 추가 입력으로 줍니다: \pi(\mathbf a\mid\mathbf s, \mathbf z). 핵심은 encoder에 information bottleneck 을 넣어, 동역학 파라미터 \mathbf M 과 인코딩 \mathbf Z 사이 상호정보 I(\mathbf M, \mathbf Z) 에 상한 I_c 를 두는 것입니다.
\underset{\pi, E}{\arg\max}\ \mathbb E_{\boldsymbol\mu\sim p(\boldsymbol\mu)} \mathbb E_{\mathbf z\sim E(\mathbf z\mid\boldsymbol\mu)} \mathbb E_{\tau\sim p(\tau\mid\pi,\boldsymbol\mu,\mathbf z)}\Big[\sum_{t=0}^{T-1}\gamma^t r_t\Big] \quad \text{s.t. } I(\mathbf M, \mathbf Z) \le I_c
bottleneck이 강할수록(작은 \beta) 정책이 동역학의 정확한 값에 덜 의존해 적응 전 성능이 높지만 적응 폭은 작아지고, 약할수록 적응 전엔 덜 강건하나 적응 후 개선이 큽니다.
(C) Real World Transfer. 실세계에서는 latent space에서 누적 보상을 최대화하는 \mathbf z^* 를 탐색해 적응합니다.
\mathbf z^* = \underset{\mathbf z}{\arg\max}\ \mathbb E_{\tau\sim p^*(\tau\mid\pi,\mathbf z)}\Big[\sum_{t=0}^{T-1}\gamma^t r_t\Big]
모델 구조
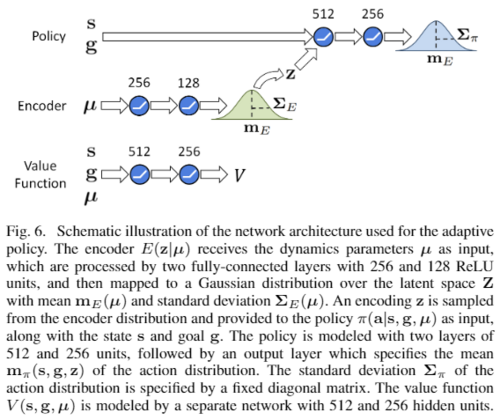
encoder E(\mathbf z\mid\boldsymbol\mu) 는 동역학 파라미터를 분포 평균·표준편차로 매핑하는 완전연결망(256, 128 ReLU). 정책 \pi(\mathbf a\mid\mathbf s, \mathbf g, \mathbf z) 는 상태·goal·동역학 인코딩을 받아 가우시안 행동 분포의 평균을 출력(512, 256층, 표준편차는 고정 대각행렬). 가치함수 V(\mathbf s, \mathbf g, \boldsymbol\mu) 는 별도 망(512, 256).
실험
셋업: 18-DoF 4족 로봇(다리당 3 구동 자유도 ×4 = 12 + root 6 미구동). mocap은 공개 데이터셋. 성능은 정규화 return(0=최소, 1=최대)으로 기록. 각 정책은 PPO로 약 2억 샘플 시뮬레이션 학습(reparameterization trick으로 end-to-end). 실세계 적응은 AWR(Advantage-Weighted Regression) 을 latent dynamics 공간에서 수행, 정책당 약 50회 실세계 trial(스킬당 5~10초).
학습한 스킬
pacing·trotting 같은 보행과 민첩한 turning·spinning을 학습 — 서로 다른 reference motion을 주는 것만으로 다양한 gait를 학습합니다(pacing: 같은 쪽 두 다리가 함께, 느린 속도 / trotting: 대각 다리가 함께, 빠른 속도). mocap을 거꾸로 재생해 후진 gait 도 학습했는데, 제조사 컨트롤러보다 빨랐습니다(제조사 최고 0.84 m/s, Dog Trot 1.08 m/s, 후진 trot 1.20 m/s). 아티스트가 만든 애니메이션(공중 90° 회전 Hop-Turn 등)도 모방했으나, Running Man처럼 일부 동작은 재현이 어려웠습니다.
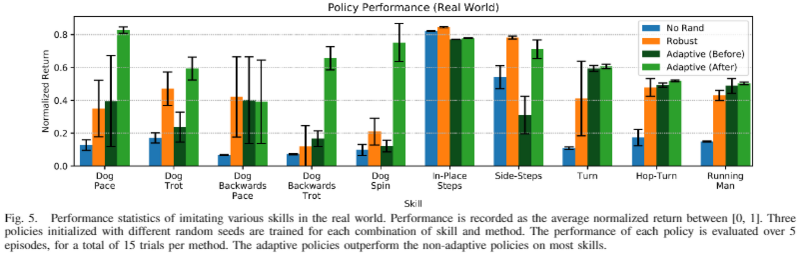
실세계 성능 (Fig. 5, 7)
네 방법 비교 — No Rand(무작위화 없음), Robust(무작위화O, 적응X), Adaptive (Before/After). 3개 시드 × 5 에피소드 = 방법당 15 trial.
- 적응형 정책이 대부분 스킬에서 비적응 정책을 능가.
- 단순 스킬(In-Place Steps, Side-Steps)은 Robust만으로도 전이 충분. 하지만 동적 스킬(Dog Pace, Dog Spin)은 Robust가 넘어지기 쉬운 반면 adaptive는 일관되게 수행.
- 무작위화 없는 정책은 대부분 스킬에서 전이 실패.
- Fig. 7(넘어지기까지 시간): 적응형이 균형을 더 오래 유지하며, 종종 최대 에피소드 길이까지 버팀.
Out-of-distribution & Information Bottleneck (Fig. 8–10)
- OOD: 학습 범위보다 넓은 동역학을 샘플한 100개 시뮬 환경에서, 적응형이 더 다양한 동역학에서 높은 return 을 달성(예: Dog Pace에서 적응형은 50% 환경에서 return>0.6, robust는 38%). 적응 학습 곡선(Fig. 9)은 비교적 적은 에피소드로 새 환경에 적응.
- Information bottleneck: \beta=10^{-4} 가 강건성과 적응성의 좋은 절충. bottleneck이 있는(IB) 정책이 없는(No IB) 정책보다 적응 전·후 모두 대체로 우수.
비판적 고찰
강점
- 보상 설계 부담 제거. reference motion을 모방함으로써 스킬별 정교한 보상 함수 설계를 없애고, 하나의 시스템으로 다양한 민첩 스킬 을 자동 합성합니다. mocap을 거꾸로 재생해 후진 gait를 얻는 등 확장도 손쉽습니다.
- latent + IB 기반 적응의 효율성. domain randomization으로 강건한 적응형 정책을 만들고, latent space 탐색으로 약 50회 trial 만에 실로봇에 적응합니다. information bottleneck으로 강건성↔︎적응성 트레이드오프를 조절하는 점이 우아합니다.
- 실로봇 검증의 폭. pacing·trotting·spin·hop-turn 등 다양한 동작을 실제 Laikago에서 보였고, OOD 동역학에서도 적응형의 우위를 정량화했습니다.
- 실세계 친화적 설계. root 위치를 상태에서 제외하고 PD 저역통과 필터를 쓰는 등, 배포 현실(추정 불확실성·진동)을 고려했습니다.
약점과 한계
- 저자가 인정한 동적 행동의 한계. 하드웨어·알고리즘 제약으로 큰 점프나 빠른 달리기 같은 더 동적인 행동은 학습하지 못했습니다.
- 수작업 컨트롤러 대비 안정성. 학습된 컨트롤러는 최고 수준의 수동 설계 컨트롤러만큼 안정적이지 않습니다. 더 복잡한 실세계 응용엔 강건성 향상이 필요합니다.
- reference·mocap 의존. 좋은 reference motion(mocap/애니메이션)이 있어야 하며, 물리적으로 부정확한 애니메이션은 일부 동작(Running Man)에서 재현 실패를 낳았습니다.
- 적응에 실세계 trial 필요. 50회 수준이라 적지만, 위험한 동적 스킬에서는 실세계 trial 자체가 비용·위험을 동반합니다(추측). 저자는 향후 비디오 클립 등으로 행동 데이터를 늘리는 방향을 제시합니다.
요약 및 결론
이 논문은 동물 mocap 모방 으로 4족 로봇의 다양하고 민첩한 보행 스킬을 학습하는 프레임워크를 제시합니다. 핵심은 (1) IK 기반 motion retargeting, (2) goal-conditioned 보상으로 모션을 따라가는 motion imitation(+ domain randomization), (3) latent dynamics + information bottleneck 기반 sample-efficient domain adaptation 입니다. reference motion이 스킬별 보상 설계를 대체하고, latent space 탐색이 sim-to-real 전이를 효율화합니다.
수치로 정리하면, 18-DoF Laikago에서 pacing·trotting·후진 gait(최고 1.20 m/s)·spin·hop-turn을 학습했고, 약 50회 실세계 trial 의 적응으로 적응형 정책이 비적응 정책 대비 더 안정적으로(넘어지기까지 오래 버팀) 동작했으며, OOD 동역학에서도 우위를 보였습니다. information bottleneck \beta=10^{-4} 가 강건성과 적응성의 좋은 절충점이었습니다.
실무 관점에서 이 연구의 가치는 “스킬별 보상 설계 없이, 동물 모션을 모방하고 효율적으로 적응시켜 다양한 민첩 보행을 실로봇에서 구현할 수 있음을 보인 것” 에 있습니다. 큰 점프·달리기 같은 동적 행동과 최고 수동 컨트롤러 수준의 안정성은 한계로 남지만, imitation + latent adaptation 이라는 틀은 이후 보행 로봇 학습 연구의 중요한 토대가 되었습니다.