flowchart TD
A[Start: Offline Dataset D\n& Empty Replay Buffer R] --> B[Environment Interaction]
B --> C[Collect Transition\nstore in R]
C --> D{For G gradient steps}
D --> E["Symmetric Sampling\n50% from R + 50% from D\n--> Batch b"]
E --> F["TD Target Computation\ny = r + gamma * min_{Z} Q_i(s', a')\n[with optional entropy]"]
F --> G["Critic Update x E\nLayerNorm prevents Q-value divergence\nEnsemble provides regularization"]
G --> H["Actor Update\nmaximize mean Q over ensemble"]
H --> I["Target Network EMA Update"]
I --> D
D --> B
style E fill:#4CAF50,color:#fff
style G fill:#2196F3,color:#fff
style F fill:#9C27B0,color:#fff
📃RLPD 리뷰
rl
offline-data
sample-efficiency
Efficient Online Reinforcement Learning with Offline Data
- 💡 이 논문은 기존의 off-policy RL 방법에 최소한의 수정만으로 오프라인 데이터를 활용하는 효율적인 온라인 강화 학습 방법인 RLPD를 제안합니다.
- ⚙️ RLPD는 symmetric sampling, 가치 과대추정(value over-extrapolation)을 완화하기 위한 Layer Normalization, 그리고 sample-efficient 학습을 위한 large ensembles 사용을 통해 이를 달성합니다.
- 🚀 30가지 다양한 태스크에 걸친 광범위한 실험을 통해, RLPD는 추가적인 계산 오버헤드 없이 기존 방법보다 최대 2.5배 향상된 신뢰할 수 있는 state-of-the-art 성능을 입증했습니다.
🔍 Ping Review
🔍 Ping — A light tap on the surface. Get the gist in seconds.
본 연구는 온라인 Reinforcement Learning(RL)에서 샘플 효율성(sample efficiency)과 탐험(exploration)이라는 주요 문제를 해결하기 위해 오프라인 데이터(offline data)를 활용하는 방법을 제안한다. 기존 방법들은 오프라인 데이터를 효과적으로 사용하기 위해 광범위한 수정이나 추가적인 복잡성을 요구했지만, 본 논문은 기존 off-policy RL 방법들을 활용하여 오프라인 데이터를 온라인 학습에 통합할 수 있는지 질문한다. 연구 결과, 약간의 중요하고 필수적인 변경 사항만으로도 신뢰할 수 있는 성능을 달성할 수 있음을 보여주며, 이를 RLPD(Reinforcement Learning with Prior Data)라고 명명한다.
기존 off-policy RL 알고리즘을 오프라인 데이터와 함께 단순히 적용하는 것은 만족스럽지 못한 결과를 초래할 수 있다. 예를 들어, Figure 1에서 ’SAC + Offline Data’는 ’IQL + Finetuning’에 비해 낮은 성능을 보인다. RLPD는 이러한 문제를 해결하기 위해 몇 가지 핵심 설계 선택(design choices)을 제안한다.
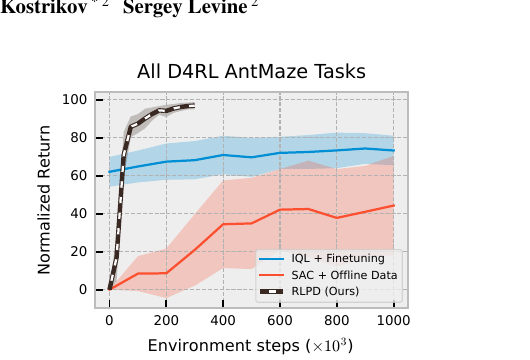
Figure 1. RLPD(검은 점선)는 사전 학습 없이도 D4RL AntMaze 전체 태스크에서 기존 방법을 능가한다. 단순히 ’SAC + Offline Data’를 적용하면 ’IQL + Finetuning’보다 오히려 낮은 성능을 보인다.
Design Choice 1: A Simple and Efficient Strategy to Incorporate Offline Data (Symmetric Sampling) RLPD는 사전 수집된 오프라인 데이터를 통합하기 위해 간단한 ‘symmetric sampling’ 방식을 사용한다. 이는 각 미니배치에서 50%의 데이터를 현재 replay buffer에서 샘플링하고, 나머지 50%는 오프라인 데이터 버퍼에서 샘플링하는 방식이다. 이 전략은 하이퍼파라미터 튜닝 없이도 다양한 도메인에서 효과적이다. 그러나 SAC와 같은 표준 off-policy 메서드에 이를 단순히 적용하는 것만으로는 강력한 성능을 얻기 어렵다.
Design Choice 2: Layer Normalization Mitigates Catastrophic Overestimation 표준 off-policy RL 알고리즘은 학습된 Q-function을 Out-of-Distribution(OOD) 액션에 대해 쿼리할 때, 함수 근사(function approximation)로 인해 실제 값보다 과도하게 높게 평가(overestimation)하는 경향이 있다. 이는 학습 불안정성과 잠재적인 발산(divergence)을 초래한다. Figure 2는 symmetric sampling을 적용했을 때 Q-value가 발산하는 현상을 보여준다. RLPD는 이러한 문제를 완화하기 위해 critic 네트워크에 Layer Normalization(LayerNorm)을 적용할 것을 제안한다. LayerNorm은 네트워크의 외삽(extrapolation)을 효과적으로 제한하면서도, 정책이 오프라인 데이터에 고정되도록 명시적으로 제약하지 않아 새로운 영역 탐색을 방해하지 않는다. 특히, LayerNorm은 Q-value를 가중치(weight) 레이어의 norm에 의해 경계 짓는다. 즉, Q-function Q_{\theta,w}(s, a)가 파라미터 \theta, w로 표현되고 중간 표현이 \psi_\theta(s, a)일 때, 다음과 같은 관계가 성립한다: \Vert Q_{\theta,w}(s, a)\Vert = \Vert w^T \text{relu}(\psi_\theta(s, a))\Vert \le \Vert w\Vert \Vert \text{relu}(\psi_\theta(s, a))\Vert \le \Vert w\Vert \Vert \psi(s, a)\Vert \le \Vert w\Vert 이러한 속성은 OOD 액션에 대한 Q-value가 이미 본 데이터의 값보다 크게 증가하지 않도록 보장하여, 오차성 액션 외삽의 영향을 크게 줄인다. Figure 2와 Figure 7은 LayerNorm이 critic 발산을 완화하고 성능을 크게 향상시킴을 보여준다.
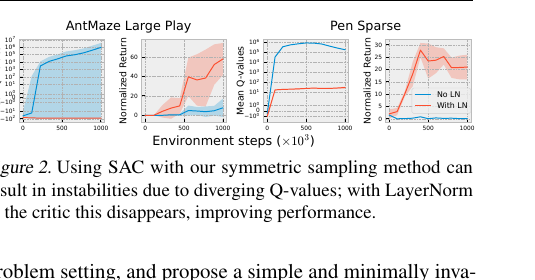
Figure 2. Symmetric sampling만 적용하면 AntMaze, Pen 등에서 Q-value가 로그 스케일로 발산하여 성능이 정체된다. Critic에 LayerNorm을 추가하면(With LN) 발산이 사라지고 성능이 회복된다.
Design Choice 3: Sample Efficient RL 오프라인 데이터의 효과적인 활용을 위해 Bellman backup이 최대한 샘플 효율적으로 수행되어야 한다. 이를 위해 RLPD는 업데이트-대-데이터(update-to-data, UTD) 비율을 증가시킨다. 그러나 높은 UTD 비율은 통계적 과적합(statistical overfitting)을 유발할 수 있으므로, 이를 완화하기 위해 critic 네트워크에 Random Ensemble Distillation을 적용한다. 이는 L2 normalization이나 Dropout보다 강력한 정규화(regularization) 효과를 제공한다(Figure 9). 픽셀 기반(pixel-based) 환경의 경우, Random Shift Augmentations도 함께 사용된다.
Per-Environment Design Choices 본 논문은 Deep RL 알고리즘의 구현 세부 사항에 대한 민감성을 강조하며, 특정 설계 선택이 환경에 따라 달라질 수 있음을 지적한다.
- Clipped Double Q-Learning (CDQ): Q-learning의 값 과대평가 문제를 완화하기 위해 제안되었으나, 특정 환경(예: sparse reward tasks)에서는 너무 보수적일 수 있다. RLPD는 2개의 Q-function 대신 1개의 Q-function을 사용하는 것이 더 나은 성능을 보일 수 있음을 시사한다.
- Maximum Entropy RL: 탐험을 촉진하는 데 유용하지만, 엔트로피 항의 유무나 가중치 \alpha는 환경에 따라 최적의 값이 달라질 수 있다.
- Architecture: Actor와 critic 네트워크의 레이어 수(2 또는 3)도 성능에 영향을 미친다. RLPD는 practitioner들을 위해 이러한 환경별 설계 선택을 순서대로 테스트해보는 워크플로우를 제안한다.
RLPD Algorithm Overview (Algorithm 1)
RLPD는 SAC를 기반으로 하며, 위에서 설명한 핵심 요소들을 통합한다.
- LayerNorm, Large Ensemble Size (E), Gradient Steps (G), 그리고 네트워크 Architecture를 선택한다.
- 초기화된 Critic(\theta_i) 및 Actor(\phi) 파라미터를 사용한다.
- Symmetric sampling을 통해 minibatch를 생성한다. (Line 12: replay buffer R에서 N/2 샘플, Line 13: offline data buffer D에서 N/2 샘플)
- Critic 업데이트 시, Ensemble Critics 중 Subset Z개를 샘플링하여 타겟 Q-value를 계산한다 (Line 15, 16: y = r + \gamma \min_{i \in Z} Q_{\theta'_i}(s', \tilde{a}'), \tilde{a}' \sim \pi_\phi(\cdot|s')).
- 선택적으로 entropy term을 추가한다 (Line 17: y = y + \gamma\alpha \log \pi_\phi(\tilde{a}'|s')).
- Critic 및 Actor 네트워크를 업데이트한다.
Experiments
RLPD는 Sparse Adroit, D4RL AntMaze, D4RL Locomotion, V-D4RL 등 30개 이상의 다양한 태스크에서 평가되었다. 기존 최첨단 방법(Prior SoTA)과 SACfD(오프라인 데이터로 replay buffer를 초기화하는 방식)와 비교했을 때, RLPD는 모든 벤치마크에서 기존 최고 성능을 능가하거나 대등한 성능을 보이며, 특히 어려운 sparse reward 태스크에서는 최대 2.5배의 성능 향상을 달성했다(Figure 4, 5). RLPD는 사전 학습(pre-training) 없이도 이러한 성능을 달성하여, 빠른 온라인 개선을 보여주었다.
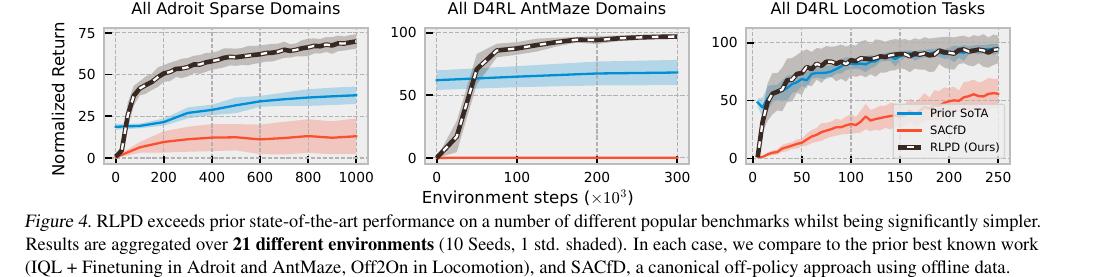
Figure 4. Adroit Sparse, AntMaze, Locomotion 세 벤치마크 모두에서 RLPD(검은 점선)가 Prior SoTA 및 SACfD를 능가한다. 21개 환경, 10시드, 1 표준편차 기준으로 집계한 결과이다.
Ablation Study
- LayerNorm의 중요성: Figure 7에서 LayerNorm은 Adroit 도메인에서 강력한 성능을 위해 매우 중요하며, 특히 데이터가 제한적이거나 협소하게 분포된 경우(Expert Adroit Sparse Tasks) LayerNorm이 없으면 성능이 붕괴됨을 보여준다.
- Workflow 검증: Figure 8은 제안된 환경별 설계 선택(CDQ 사용 여부, entropy term 사용 여부, 네트워크 레이어 수)이 강한 성능을 이끌어내고, 이를 적절히 조정하는 것이 중요함을 보여준다.
- Critic Regularization: Figure 9에서 Random Ensemble Distillation이 weight-decay나 Dropout보다 전반적으로 더 나은 성능을 제공하며, 특히 sparse reward 태스크에서 그러하다.
- Sampling Proportion Sensitivity: Figure 12에서 50%의 symmetric sampling 비율이 다양한 시나리오에서 최적의 성능을 제공하며, RLPD가 샘플링 비율에 크게 민감하지 않음을 보여준다. Initializing the buffer with offline data(Figure 11)는 초기 성능은 좋으나 점근적 성능 향상에 한계가 있다.
결론적으로, 본 연구는 기존 off-policy RL 알고리즘을 오프라인 데이터와 함께 온라인 학습에 활용하는 것이 매우 효과적임을 보여준다. symmetric sampling, LayerNorm을 통한 Q-value 외삽 정규화, 그리고 샘플 효율적인 학습(large ensembles)의 독특한 조합이 RLPD의 성공에 핵심적임을 입증했다. 이 접근 방식은 계산 효율성에 미미한 영향을 미치며, 기존 방법론에 쉽게 통합될 수 있어 practitioner들에게 실용적인 지침을 제공한다.
🔔 Ring Review
🔔 Ring — An idea that echoes. Grasp the core and its value.
ICML 2023 (Short Presentation)
서론: 왜 이 문제가 어려운가?
로봇 팔이 물건을 집어 올리는 법을 배운다고 상상해보자. 우리에게는 이미 인간이 시연한 데이터 수백 개가 있다. 그런데 강화학습(RL) 에이전트가 이 데이터를 보고서도 처음엔 완전히 무작위로 팔을 휘젓는다면 얼마나 비효율적인가? 이미 “어디로 가야 하는지”를 가르쳐주는 데이터가 있는데 이를 활용하지 못한다면, 이는 마치 길을 알고 있는 지도를 주머니에 넣어두고 길을 헤매는 것과 같다.
RL의 샘플 효율성(sample efficiency) 문제는 로봇공학 실무자에게 특히 뼈아프다. 실제 로봇을 수십만 번 돌릴 수는 없다. 하드웨어가 마모되고, 안전사고가 나며, 무엇보다 시간이 없다. 그래서 연구자들은 크게 두 가지 방향을 탐색해왔다.
- 오프라인 RL (Offline RL): 수집된 데이터만으로 정책을 학습한다. 환경과의 상호작용이 전혀 없다. 대표적으로 IQL(Implicit Q-Learning), CQL(Conservative Q-Learning) 등이 있다.
- 온라인 파인튜닝 (Online Fine-tuning): 오프라인 RL로 먼저 정책을 초기화한 뒤, 온라인 상호작용으로 개선한다.
두 방식 모두 공통된 딜레마를 안고 있다. 오프라인 RL은 분포 외 행동(out-of-distribution action)에 대해 과도하게 보수적이어서, 온라인으로 전환했을 때 탐색을 억제한다. 반대로 이 보수성을 풀면 Q-값이 폭발적으로 발산한다.
이 논문의 핵심 질문은 단순하면서도 도발적이다:
“오프라인 사전 학습이나 명시적 제약 없이, 기존 off-policy 알고리즘에 오프라인 데이터를 그냥 집어넣으면 안 되는가?”
그리고 저자들의 답은 “된다. 단, 몇 가지 핵심 설계 선택이 필요하다”이다. 이 논문은 그 설계 선택들을 체계적으로 찾아내고 정당화한다.
방법: RLPD의 세 가지 핵심 설계 선택
저자들이 제안하는 알고리즘의 이름은 RLPD (Reinforcement Learning with Prior Data)다. 기반 알고리즘은 SAC (Soft Actor-Critic)이며, 세 가지 핵심 수정을 가한다. 이 세 가지를 하나씩 해부해보자.
설계 선택 1: 대칭 샘플링 (Symmetric Sampling)
가장 단순하면서도 가장 강력한 아이디어다.
기존 접근 방식들은 오프라인 데이터를 어떻게 다뤄왔는가? 크게 두 가지였다.
- 버퍼 초기화(Seeded Buffer): 오프라인 데이터를 리플레이 버퍼에 미리 채워 넣는다. 온라인 경험이 쌓이면 오프라인 데이터의 비율이 줄어든다.
- 사전 학습(Pre-training): 오프라인 데이터로 먼저 정책을 학습한 뒤 온라인 전환.
RLPD는 다르다. 매 미니배치마다 정확히 50%는 온라인 리플레이 버퍼에서, 50%는 오프라인 데이터 버퍼에서 샘플링한다. 학습 내내 이 비율을 고정으로 유지한다. 이를 대칭 샘플링(Symmetric Sampling)이라 부른다.
이 단순한 전략이 왜 효과적인가? 직관적으로 생각해보자:
- 버퍼 초기화 방식의 문제: 온라인 경험이 쌓이면 오프라인 데이터가 버퍼에서 희석된다. 즉, 후반부에는 오프라인 데이터를 거의 사용하지 않게 된다. 희귀한 시연 데이터라면 더욱 심각하다.
- 대칭 샘플링의 장점: 오프라인 데이터를 처음부터 끝까지 일정 비율로 활용한다. 이는 오프라인 데이터가 탐색 밀도(reward density)를 높여주는 역할을 지속적으로 수행하게 한다.
실험에서도 이를 확인할 수 있다 (논문 Figure 10). Adroit Pen 환경에서 대칭 샘플링은 배치 내 보상 밀도를 지속적으로 높이며, Door 환경에서는 안정성을 크게 향상시킨다. 놀랍게도 50% 비율이 25%, 75%, 100%보다 다양한 도메인에서 가장 견고한 성능을 보인다 (논문 Figure 12). 하이퍼파라미터 튜닝 없이도 잘 동작하는 “공짜 점심”에 가깝다.
설계 선택 2: 레이어 정규화 (Layer Normalization)로 Q-값 발산 억제
이것이 RLPD에서 가장 중요하고 흥미로운 통찰이다.
문제의 본질: 오프라인 데이터는 상태-행동 공간의 일부만 커버한다. Q-신경망은 학습 데이터 분포 바깥의 행동에 대해서도 값을 예측해야 하는데, 이때 분포 외 행동에 대한 Q-값이 폭발적으로 과대추정(overestimation)될 수 있다. 오프라인 RL 분야에서 이 현상은 오래전부터 알려진 치명적 병리다.
논문의 Figure 2를 보면 극명하게 드러난다. 대칭 샘플링만 적용했을 때 AntMaze Large 같은 복잡한 환경에서 Q-값이 로그 스케일로 폭주한다. 성능은 전혀 오르지 않는다.
기존 오프라인 RL의 대처법은 보수적 벌점(conservative penalty)이었다. CQL은 분포 외 행동의 Q-값을 명시적으로 낮추고, BCO는 행동 클로닝 항을 추가한다. 이런 방식은 효과적이지만 탐색을 억제한다는 부작용이 있다.
RLPD의 해법은 놀랍도록 우아하다: 레이어 정규화(Layer Normalization, LN)를 크리틱 네트워크에 적용한다.
왜 LN이 효과가 있는가? 저자들은 이를 수학적으로 보여준다. LN이 적용된 Q-함수 Q_{\theta,w}에 대해:
\|Q_{\theta,w}(s, a)\| = \|w^T \text{relu}(\psi_\theta(s, a))\| \leq \|w\| \cdot \|\psi_\theta(s, a)\|
LN은 중간 표현 \psi_\theta를 단위 구 위로 정규화한다. 따라서:
\|\psi_\theta(s, a)\| \leq 1 \quad \Rightarrow \quad \|Q_{\theta,w}(s, a)\| \leq \|w\|
결론: Q-값은 마지막 레이어 가중치의 norm에 의해 위로 유계(bounded)된다. 이는 분포 외 행동에 대해서도 마찬가지다. Q-값이 무한히 폭발하는 일이 구조적으로 불가능해진다.
논문의 Figure 3이 이를 직관적으로 보여준다. 반지름 0.5인 원 위의 데이터를 학습할 때, 표준 MLP는 분포 밖(원 외부)에서 값이 무한히 증가하지만, LN을 추가한 MLP는 분포 밖에서도 값이 경계 내에 머문다.
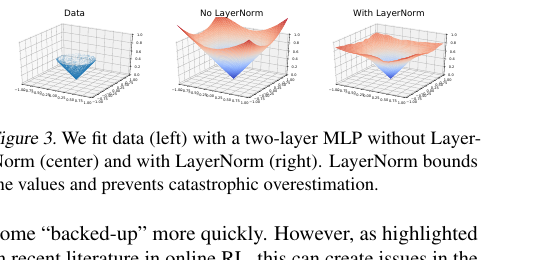
Figure 3. 2층 MLP로 데이터(왼쪽)를 학습한 결과. LayerNorm이 없으면(가운데) 분포 밖 영역에서 값이 무한히 외삽되지만, LayerNorm을 추가하면(오른쪽) 값이 경계 내에 머물러 치명적 과대추정을 방지한다.
그런데 여기서 중요한 미묘함이 있다. LN은 Q-값에 상한을 두지만, 특정 행동을 명시적으로 “나쁘다”고 판단하지는 않는다. CQL처럼 분포 외 행동의 Q-값을 인위적으로 낮추지 않는다. 따라서 탐색을 억제하지 않는다. 이것이 온라인 RL에서 LN이 특히 강력한 이유다. 오프라인 데이터로 인한 발산을 막으면서도, 에이전트가 새로운 영역을 자유롭게 탐색할 수 있도록 허용한다.
설계 선택 3: 샘플 효율적 RL — 대규모 앙상블
오프라인 데이터를 최대한 빠르게 활용하려면, 각 환경 스텝에서 더 많은 학습이 이루어져야 한다. 이를 위한 두 가지 축이 있다.
① UTD (Update-to-Data) 비율 증가
환경 스텝 1회당 여러 번의 그래디언트 업데이트를 수행한다. UTD=20이면 환경 스텝 1번에 그래디언트 업데이트 20번을 한다. 오프라인 데이터가 더 빨리 “소화”된다.
하지만 UTD를 높이면 통계적 과적합(overfitting) 문제가 생긴다. Q-함수가 미니배치에 과적합하여 일반화 성능이 떨어지는 것이다.
② 크리틱 앙상블 (Critic Ensemble)
이 과적합 문제를 해결하기 위해 RLPD는 REDQ (Randomized Ensemble Double Q-Learning) 스타일의 대규모 앙상블을 채택한다. E개의 크리틱 Q_{\theta_1}, \ldots, Q_{\theta_E}를 동시에 학습하며, TD 백업 시 이 중 랜덤하게 서브셋 Z개를 선택해 최솟값을 취한다.
y = r + \gamma \min_{i \in \mathcal{Z}} Q_{\theta'_i}(s', \tilde{a}'), \quad \tilde{a}' \sim \pi_\phi(\cdot|s')
여기서 |\mathcal{Z}|는 환경에 따라 1 또는 2로 설정한다 (자세한 내용은 아래 환경별 설계 선택 섹션 참조).
저자들은 다양한 정규화 방법을 비교한다 (논문 Figure 9): - Weight Decay: 모든 도메인에서 앙상블보다 열등. - Dropout: 밀집 보상(dense reward) 환경에서는 괜찮지만, 희소 보상(sparse reward) 환경에서는 실패. - 앙상블 (RLPD): 가장 일관되게 강력한 성능.
결론적으로 앙상블이 가장 범용적이고 강력한 정규화 전략이다.
의사코드: RLPD 전체 구조
Algorithm: RLPD (Online RL with Offline Data)
Inputs:
- Offline dataset D = {(s, a, r, s') tuples}
- Ensemble size E, gradient steps G per env step
- Architecture: LayerNorm, number of layers
Initialize:
- E critic networks {theta_i}, targets {theta'_i = theta_i}
- Actor network phi
- Empty online replay buffer R
While training:
Receive initial state s_0
For each env step t:
a_t ~ pi_phi(.|s_t) # Act
Store (s_t, a_t, r_t, s_{t+1}) in R # Collect
For g = 1..G: # Multiple gradient steps
Sample N/2 from R (online data)
Sample N/2 from D (offline data) # Symmetric Sampling
Combine into batch b of size N
Sample subset Z of Z indices from {1..E}
Compute TD target:
y = r + gamma * min_{i in Z} Q_{theta'_i}(s', a'_tilde)
[optionally + gamma * alpha * log pi_phi(a'_tilde|s')]
For i = 1..E:
Update theta_i: minimize (y - Q_{theta_i}(s,a))^2 # LayerNorm in Q-net
Update actor phi: maximize (1/E) * sum_i Q_{theta_i}(s, a_tilde)
Update target networks: theta'_i <- rho*theta'_i + (1-rho)*theta_i환경별 설계 선택 (Per-Environment Design Choices)
RLPD는 위의 세 가지 핵심 선택 외에, 환경에 따라 조정해야 할 “환경 민감(environment-sensitive)” 선택들이 있다. 저자들은 이것이 기존 RL 문헌에서 흔히 당연하게 받아들여지지만 사실은 재검토가 필요하다고 강조한다.
① Clipped Double Q-Learning (CDQ)
TD3와 SAC에서 표준으로 쓰이는 CDQ는 두 크리틱의 최솟값을 타깃으로 쓴다. 이는 실제 타깃 Q-값에서 약 1 표준편차를 빼는 효과가 있어 보수적이다. 희소 보상 환경에서는 이 보수성이 학습을 방해할 수 있다. 논문의 AntMaze Large Diverse 실험 (Figure 8)에서 CDQ를 제거하고 1개 크리틱만 서브셋으로 사용했을 때 성능이 크게 향상된다.
② 최대 엔트로피 항 (MaxEnt / Entropy Backups)
SAC의 엔트로피 항은 탐색을 돕는다. 그러나 일부 환경(Adroit Relocate, Humanoid Walk)에서는 오히려 성능을 저하시킨다. 저자들은 이 항을 제거하는 것을 출발점으로 추천한다.
③ 네트워크 깊이 (Network Depth)
2층 vs. 3층 MLP를 비교한다. 복잡한 환경(예: Adroit, Humanoid)에서는 3층이 유리하고, 단순한 환경에서는 2층으로 충분하다.
실용적 워크플로우: 저자들은 이 세 가지 환경별 선택을 아래 순서로 먼저 탐색하라고 권장한다.
Step 1: Try subsetting 1 critic (disable CDQ) --> Observe improvement?
Step 2: Try removing entropy backups --> Observe improvement?
Step 3: Try deeper 3-layer MLP --> Observe improvement?전체 구조 다이어그램
RLPD 핵심 설계 선택 요약표
| 설계 선택 | 무엇을 해결하는가 | 어떻게 작동하는가 | 추가 비용 |
|---|---|---|---|
| 대칭 샘플링 | 오프라인 데이터 희석 문제 | 매 배치 50:50 고정 혼합 | 없음 |
| Layer Normalization | Q-값 발산 / 과대추정 | Q-값을 \|w\|로 유계화 | 미미함 |
| 크리틱 앙상블 (REDQ) | 통계적 과적합 | E개 크리틱, 랜덤 서브셋 | 메모리 E배 |
| UTD 비율 증가 | 느린 데이터 활용 | 스텝당 G번 업데이트 | 계산량 G배 |
| CDQ 조정 | 과도한 보수성 | 1개 크리틱 서브셋 | 없음 |
| 엔트로피 항 조정 | 환경별 탐색 trade-off | 환경에 따라 on/off | 없음 |
실험: 어떤 환경에서 얼마나 좋은가?
실험 설정
저자들은 총 30개 태스크에 걸쳐 RLPD를 검증한다. 크게 세 그룹이다.
그룹 1: Sparse Adroit (3개 태스크)
dexterous hand 조작 태스크 — 펜 돌리기(Pen), 문 열기(Door), 공 재배치(Relocate). 희소 보상이며, 소수의 인간 시연 + 대량의 BC 정책 궤적이 오프라인 데이터로 제공된다. 비교 기준: IQL + Fine-tuning.
그룹 2: D4RL AntMaze (6개 태스크)
Ant 로봇이 미로를 탐색하는 태스크. 보상은 극히 희소(목표 도달시에만). 오프라인 데이터는 서브옵티멀 궤적으로만 구성된다. 비교 기준: IQL + Fine-tuning.
그룹 3: D4RL Locomotion (12개 태스크)
Hopper, HalfCheetah, Walker, Ant의 다양한 오프라인 데이터 품질 버전. 밀집 보상. 비교 기준: Off2On.
모든 실험은 10 시드, 1 표준편차를 보고한다.
주요 결과
논문 Figure 4 (모든 태스크 집계 결과):
- Adroit: RLPD는 IQL+Fine-tuning을 크게 앞서며, 특히 Door 태스크에서 Prior SoTA 대비 2.5배 성능 향상.
- AntMaze: RLPD는 Prior SoTA가 할당한 스텝의 3분의 1 이내에 동등 이상의 성능 달성. 모든 6개 AntMaze 태스크를 처음으로 효과적으로 풀어낸 방법이라고 저자들은 주장한다.
- Locomotion: 기존 Off2On과 유사한 수준이며, 사전 학습 없이도 경쟁력 있는 성능.
특히 주목할 점은 이다: IQL+Fine-tuning 같은 Prior SoTA 방법들은 오프라인 사전 학습 덕분에 초기 성능이 높다. 그러나 RLPD는 사전 학습 없이 시작해서 1만 스텝 내외만에 이 초기 성능을 따라잡고 이를 넘어선다.
픽셀 기반 환경으로의 전이
저자들은 RLPD를 V-D4RL (비전 기반 D4RL)에도 적용한다. 오프라인 데이터는 상태 기반(state-based) 정책이 생성한 픽셀 관찰 궤적으로, 부분 가관측성(partial observability) 문제가 내재되어 있다.
평가 기준은 “10% DMC” — 즉 DrQ-v2가 사용하는 전체 타임스텝의 단 10%만 사용.
- Walker Walk, Cheetah Run에서 RLPD는 DrQ-v2 대비 일관되게 높은 샘플 효율.
- Humanoid Walk에서는 BC baseline이 시각적 폐색(visual occlusion)으로 실패하지만 RLPD는 유의미한 학습을 달성.
- UTD=10으로 높였을 때 Cheetah Run Expert에서 극적인 성능 향상 — 픽셀 기반 continuous control에서 고-UTD 접근이 효과적임을 처음으로 보인 사례.
이미지 기반 태스크에서는 랜덤 시프트 어그멘테이션(random shift augmentation)을 추가로 사용하며, 이는 TD-learning 과적합 문제를 완화한다.
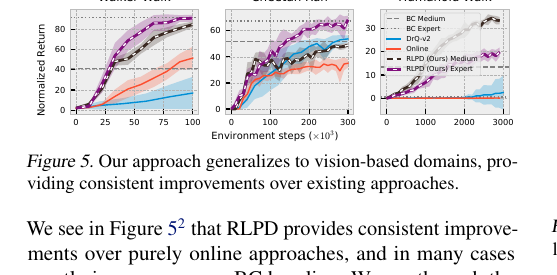
Figure 5. RLPD는 픽셀 기반 V-D4RL 도메인(Walker Walk, Cheetah Run, Humanoid Walk)에도 일반화되어, DrQ-v2 등 기존 접근 대비 일관되게 높은 샘플 효율을 보인다.
Ablation: LayerNorm의 역할
논문 Figure 7은 LN의 중요성을 다양한 조건에서 보여준다:
- Adroit Sparse (전체 데이터): LN 제거 시 분산이 크게 증가하고 평균 성능 하락.
- Expert Adroit Sparse (22개 궤적만): 데이터가 극히 제한적일 때 LN 없이는 완전히 실패 — 모든 태스크에서 진전 없음. LN이 있으면 여전히 Prior SoTA를 능가.
- AntMaze Large: LN이 샘플 효율 향상에 기여.
- V-D4RL Humanoid Walk: 복잡한 고차원 픽셀 환경에서도 LN의 안정화 효과 확인.
이 결과는 LN이 단순한 “있으면 좋은” 첨가물이 아니라, 데이터가 제한적이거나 좁은 분포일 때 필수적인 구성 요소임을 보여준다.
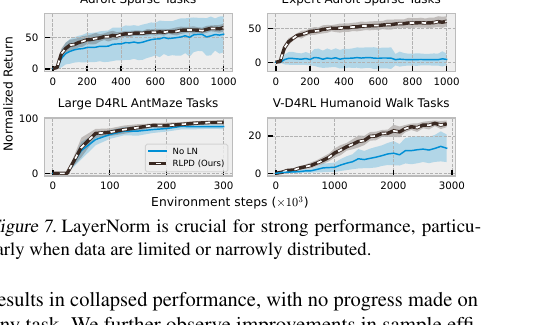
Figure 7. LayerNorm의 중요성. 특히 Expert Adroit Sparse처럼 데이터가 극히 제한적이고 좁게 분포된 경우, LayerNorm이 없으면(No LN) 성능이 완전히 붕괴된다.
비교: 관련 연구 포지셔닝
graph LR
A["Offline RL\n(IQL, CQL, TD3+BC)"] -->|"+ Online Finetuning"| B["IQL + Finetuning\n(Kostrikov et al., 2022)"]
A --> C["Off2On\n(Lee et al., 2021)"]
D["Online RL\n(SAC, TD3)"] -->|"+ Offline Buffer Init"| E["SACfD\n(Vecerík et al., 2017)"]
D -->|"+ REDQ + LN + Sym. Sampling"| F["RLPD (Ours)"]
B -->|"Requires offline pretraining\nRestricts exploration"| G["Drawbacks"]
E -->|"Offline data diluted\nNo divergence control"| G
F -->|"No pretraining\nNo explicit constraints\nExploration-friendly"| H["Advantages"]
| 방법 | 오프라인 사전학습 | 명시적 제약 | 탐색 억제 | 복잡도 |
|---|---|---|---|---|
| IQL + Fine-tuning | O | O (보수적 Q) | 부분적 | 높음 |
| Off2On | O | O (pessimistic Q-ensemble) | 부분적 | 높음 |
| SACfD | X | X | X | 낮음 |
| RLPD | X | X | X | 낮음 |
RLPD의 가장 직접적인 경쟁자는 Off2On (Lee et al., 2021) 이다. Off2On도 대규모 앙상블과 높은 UTD를 사용하지만, 오프라인 사전 학습이 필요하고 별도의 balancing mechanism을 도입한다. RLPD는 사전 학습 없이도 비슷하거나 더 나은 성능을 달성한다.
비판적 고찰: 강점과 한계
강점
1. 실용적 단순성 (Practical Simplicity)
RLPD의 핵심 아이디어들은 “추가적인 복잡성 없이 기존 SAC에 몇 줄을 바꿨을 뿐”이다. LayerNorm을 크리틱에 추가하고, 샘플링 방식을 바꾸고, 앙상블을 키웠다. 이것으로 기존 방법들을 압도한다. 재현성(reproducibility)도 높다. 코드베이스가 JAX로 공개되어 있으며, IQL 같은 무거운 사전 학습 파이프라인이 없어서 시작하기 쉽다.
2. 데이터 품질에 무관한 범용성
전문가 시연 22개짜리 극히 제한된 데이터에서부터 대량의 서브옵티멀 궤적까지 모두 잘 동작한다. 이는 오프라인 데이터의 품질을 보장하기 어려운 실제 로봇 응용에서 매우 중요한 특성이다.
3. 탐색 비억제 (Exploration-Friendly)
LN은 Q-값에 상한을 두지만 특정 행동을 벌주지 않는다. 오프라인 데이터 분포 바깥의 새로운 행동을 시도할 자유가 보장된다. 이는 오프라인 RL의 고질적 문제인 “분포 내 갇힘”을 해결한다.
4. LayerNorm의 이론적 정당화
단순히 “실험적으로 LN이 잘 된다”가 아니라, Q-값의 upper bound 유도를 통해 왜 LN이 발산을 방지하는지 이론적으로 보인다.
한계와 약점
1. 앙상블의 메모리 비용
E=10짜리 앙상블을 사용하면 파라미터 수가 10배다. 실제 로봇 배포 환경에서 메모리 제약이 있는 엣지 디바이스에서는 적용이 어려울 수 있다. 논문은 계산 오버헤드가 없다고 주장하지만, 이는 병렬 계산이 가능한 고사양 GPU 환경을 전제로 한다.
2. 환경별 하이퍼파라미터 탐색 필요
CDQ 사용 여부, 엔트로피 항, 네트워크 깊이 등 환경별 선택은 결국 탐색이 필요하다. 저자들이 워크플로우를 제시하지만, 새로운 환경에 적용할 때 이 탐색 비용이 발생한다. “하이퍼파라미터 없음”이라는 주장은 핵심 세 가지(대칭 샘플링, LN, 앙상블)에만 해당한다.
3. 리워드 함수 설계 의존성
RLPD도 결국 RL이므로, 보상 함수가 필요하다. 실제 로봇에서 희소 보상(성공/실패)은 그나마 정의하기 쉽지만, 복잡한 조작 태스크에서 밀집 보상을 설계하는 것은 별개의 어려운 문제다.
4. 단기 탐색 비효율 가능성
대칭 샘플링은 오프라인 데이터를 계속 50% 사용한다. 만약 오프라인 데이터가 극히 제한적이고 분포가 좁다면, 후반부 학습에서 이 고정 비율이 오히려 불필요한 편향을 줄 수 있다. 이에 대한 이론적 분석은 부족하다.
5. 오프라인 데이터의 보상 레이블 가용성 가정
RLPD는 오프라인 데이터에 (s, a, r, s') 튜플 — 즉 보상 r이 포함되어 있다고 가정한다. 실제로는 보상 레이블이 없는 비디오 데이터나 모션 캡처 데이터만 있는 경우가 많다. 이 경우 RLPD를 직접 적용하기 어렵다.
재현 노트: 최신 GPU(Blackwell)에서 RLPD 돌리기
논문이 강조하는 “재현성”을 실제로 확인하기 위해, 저자들이 공개한 JAX 코드베이스(ikostrikov/rlpd)를 최신 GPU 환경에서 스모크 테스트로 돌려보았다. 이 절은 논문 본문에는 없는, 2026년 시점의 최신 하드웨어에서 이 코드를 실행하려는 독자를 위한 실무 메모다. RLPD 알고리즘의 주장이 아니라 재현 과정의 사실만 기록한다.
실행 요약
- 환경: 로컬 머신 RTX 5090(Blackwell,
sm_120) + Python 3.10 +jax[cuda12]==0.6.2+flax==0.10.6+numpy<2. - 커맨드: 원본 README의 D4RL Locomotion 예제(
train_finetuning.py --env_name=halfcheetah-expert-v0 --utd_ratio=20 --config=configs/rlpd_config.py)를 그대로 사용하되, 학습 스텝 수만 축소. - 결과: 301/301 스텝을 약 90초에 완주했고, wandb offline 로그에서
critic_loss,actor_loss,q,entropy,temperature가 스텝마다 실제로 변동함을 확인했다. 즉 대칭 샘플링 + 앙상블 크리틱 학습 루프가 최신 스택 위에서 정상 동작한다. (30개 태스크 전체 성능 재현이 아니라, 학습 루프가 살아 있음을 확인하는 스모크런 수준이다.) - 기록: 미러 레포 curieuxjy/rlpd의 PR #1에 재현 과정을 남겼다.
실무적으로 걸렸던 지점 (같은 시도를 하려는 독자에게)
- GPU 인식 ≠ 실행 가능.
jax.devices()가 CUDA 디바이스를 정상 반환하더라도, 오래된 jaxlib는 Blackwell(sm_120)에서 첫 연산을 컴파일하는 순간ptxas fatal: cannot be compiled to future architecture로 죽는다. Blackwell을 쓰려면jax>=0.6.2가 사실상 필수다. - 최신 jax와
mujoco_py의 numpy 충돌. Blackwell 지원을 위해 jax를 올리면, D4RL이 의존하는mujoco_py(numpy<2요구)와 버전이 부딪힌다. 결국jax==0.6.2+numpy<2+python<3.11(d4rl 제약)의 교집합을 손으로 찾아야 했다. - 설치 순서가 의존성 재해석을 깨뜨린다.
mujoco_py는--no-build-isolation으로, 상위 패키지는--no-deps로 설치해야 pip이 의존성을 다시 풀면서 방금 맞춘 버전 조합을 깨는 일을 막을 수 있었다.
정리하면, RLPD 코드 자체는 최신 GPU에서도 문제없이 돌지만, 병목은 알고리즘이 아니라 D4RL/mujoco_py가 요구하는 구형 numpy와 Blackwell이 요구하는 신형 jax 사이의 파이썬 생태계 버전 매칭에 있다. 이 조합만 맞춰두면 논문이 주장하는 “가볍고 재현하기 쉬운 코드베이스”라는 장점은 실제로 성립한다.
로봇공학 실무자를 위한 적용 가이드
RLPD가 특히 유용한 시나리오:
소수의 인간 시연 + 온라인 RL 조합: 텔레오퍼레이션이나 키네스테틱 티칭으로 얻은 시연 데이터를 활용해 RL 초기화. Allegro Hand 같은 dexterous hand에서 finger gaiting이나 regrasping 학습.
서브옵티멀 사전 데이터 활용: 이전 실험에서 실패한 궤적들도 오프라인 데이터로 활용 가능. 오프라인 데이터 품질에 덜 민감하다는 장점.
Sim-to-Real 파이프라인: 시뮬레이터에서 생성한 궤적을 오프라인 데이터로, 실제 로봇 상호작용을 온라인 데이터로 활용하는 hybrid 접근.
실용적 구현 체크리스트:
[ ] SAC 기반 구현에서 시작
[ ] 크리틱 네트워크 모든 hidden layer에 LayerNorm 추가
[ ] 크리틱 앙상블 크기 E=10으로 설정 (proprioceptive)
[ ] 오프라인 데이터 버퍼 D 별도 구성 (고정, 업데이트 안 함)
[ ] 매 배치: R에서 N/2, D에서 N/2 샘플링
[ ] UTD 비율: 시작은 UTD=1, 이후 필요시 증가
[ ] 환경별 조정: CDQ / Entropy / 레이어 깊이 순서로 탐색
[ ] 픽셀 기반: 랜덤 시프트 어그멘테이션 추가요약 및 결론
RLPD가 우리에게 가르쳐주는 것은 단순하지만 심오하다: 오프라인 데이터와 온라인 RL의 결합을 위해 복잡한 아키텍처 변경이 필요하지 않다. 핵심은 세 가지다.
- 대칭 샘플링 — 오프라인 데이터를 처음부터 끝까지 일정하게 사용하라.
- Layer Normalization — Q-값 발산을 구조적으로 막되, 탐색을 억제하지 마라.
- 대규모 앙상블 — UTD를 높여도 과적합되지 않도록 통계적 정규화를 제공하라.
이 세 가지의 조합이 기존 방법들을 최대 2.5배 앞서는 성능을 만들어낸다. 추가 계산 오버헤드 없이.
로봇공학 관점에서 이 논문의 가장 중요한 메시지는 “좋은 오프라인 데이터가 있다면, 복잡한 사전 학습 파이프라인 없이도 온라인 RL을 빠르게 시작할 수 있다”는 것이다. Allegro Hand 같은 dexterous manipulation 플랫폼에서 소수의 텔레오퍼레이션 시연으로 RL 학습을 킥스타트하려는 연구자들에게 직접적으로 유용한 레시피다.
물론 보상 함수 설계, 도메인 랜덤화, 실제 로봇의 안전 제약 같은 실무 문제들은 여전히 별도로 해결해야 한다. 하지만 RLPD는 “사전 데이터를 어떻게 활용할 것인가”라는 핵심 질문에 명쾌하고 실용적인 답을 제시한다.
복잡함은 이해의 부족에서 온다. 진짜 이해는 단순함으로 수렴한다.
참고 문헌 (선택)
- Ball et al. (2023). Efficient Online Reinforcement Learning with Offline Data. ICML 2023.
- Haarnoja et al. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning. ICML.
- Chen et al. (2021). Randomized Ensembled Double Q-Learning. ICLR.
- Kostrikov et al. (2022). Offline Reinforcement Learning with Implicit Q-Learning. ICLR.
- Lee et al. (2021). Offline-to-Online RL via Balanced Replay and Pessimistic Q-Ensemble. CoRL.
- Fu et al. (2020). D4RL: Datasets for Deep Data-Driven Reinforcement Learning. arXiv.
- Ba et al. (2016). Layer Normalization. arXiv.