flowchart LR
A[Goal pose q*] --> P[Planner pi_plan]
O[Object state estimate] --> P
F[Skill feedback] --> P
Pr[Proprioception] --> P
P -->|"axis (one-hot)"| S[Skill pi_skill - frozen]
P -->|"residual a_res"| Sum[+]
S -->|"a_skill"| Sum
Sum -->|"a_t = a_skill + a_res"| R[Robot Hand]
R --> Pr
R --> O
S --> F
📃From Simple to Complex Skills 리뷰
dexterity
hierarchical-rl
From Simple to Complex Skills: The Case of In-Hand Object Reorientation
Haozhi Qi, Brent Yi, Mike Lambeta, Yi Ma, Roberto Calandra, Jitendra Malik
- 🤖 In-hand object reorientation 작업을 위해, 본 논문은 미리 학습된 저수준 skill들을 재사용하는 계층적 정책(hierarchical policy)을 제안하여 sim-to-real gap과 학습 효율성 문제를 해결합니다.
- 🦾 또한, 시스템은 일반화 가능한 객체 자세 추정기(generalizable object pose estimator)를 도입하며, 이는 저수준 skill 정책의 피드백과 잔여 동작(residual action)을 활용하여 복잡한 조작 환경에서 정확한 자세 추정을 가능하게 합니다.
- ✨ 실험 결과, 제안된 접근 방식은 scratch부터 학습하는 baseline보다 더 빠르게 수렴하고 높은 성능을 보이며, 다양한 객체에 대한 현실 세계 sim-to-real transfer에서 강력한 견고함과 일반화 능력을 입증했습니다.
🔍 Ping Review
🔍 Ping — A light tap on the surface. Get the gist in seconds.
이 논문은 로봇의 In-Hand Object Reorientation이라는 복잡한 작업을 수행하기 위해 기존에 학습된(pre-trained) 저수준(low-level) 스킬을 재사용하는 계층적 정책(hierarchical policy) 시스템을 제안합니다. 시뮬레이션에서 정책을 학습하고 실제 세계로 전이(transfer)하는 것이 dexterous manipulation에서 유망한 접근 방식이지만, 각 새로운 작업에 대해 sim-to-real gap을 메우는 데에는 reward engineering, hyperparameter tuning, system identification과 같은 상당한 인간의 노력이 필요합니다. 본 연구는 이러한 문제를 해결하기 위해 계층적 접근 방식을 사용합니다.

전체 시스템 개요: 하드웨어 셋업(Allegro Hand + RGB-D 카메라), 저수준 스킬을 순차적으로 전환하며 목표 자세에 도달하는 계층적 재배향 정책, 그리고 다양한 실제 테스트 객체.
핵심 방법론 (Core Methodology):
본 시스템은 두 가지 주요 구성 요소로 이루어져 있습니다: Planner Policy (\pi_{plan})와 Skill Policy (\pi_{skill}).
- Skill Policy (\pi_{skill}):
- 이것은 미리 학습된 저수준 스킬로, In-Hand Object Rotation 정책 [6]에 기반합니다. 특정 회전 축 k에 대해 객체를 회전시키는 방법을 학습합니다.
- \pi_{skill}의 입력 o_{skill_t}는 로봇의 고유수용성(proprioception) 정보 (관절 위치 \theta_{t-T:t} 및 명령된 관절 목표 a_{skill_{t-T-1:t-1}})와 RGB-D 카메라에서 얻은 깊이 이미지(depth image) 임베딩 d_{t-T:t}를 포함하는 시간적 시퀀스(temporal sequence)입니다 (여기서 T=30 타임스텝의 기록을 사용).
- \pi_{skill}은 로봇에 대한 원시 관절 위치 목표(raw joint position targets) a_{skill_t}를 출력하며, 추가적으로 객체의 물리적 속성과 형태를 나타내는 특징 벡터 z_t를 출력합니다. 이 z_t는 고수준(high-level) 정책에 대한 피드백으로 사용됩니다. z_t는 시각 정보를 기반으로 객체의 기하학적 정보를 인코딩합니다.
- Planner Policy (\pi_{plan}):
- 이것은 고수준 정책으로, a_{plan_t} = \pi_{plan}(o_{plan_t}, q_{goal_t}, z_t)와 같이 정의됩니다.
- \pi_{plan}의 입력 o_{plan_t}는 다음과 같은 정보를 포함합니다:
- 객체의 상태 시퀀스 s_{t-5:t} (3D 위치 p_t 및 단위 쿼터니언(unit quaternion) q_t로 표현된 방향).
- 객체와 목표 방향 사이의 상대적 변환 \zeta_{t-5:t} = \Delta(q_t, q_{goal_t}) = q_{goal_t} \cdot \bar{q}_t.
- 이전 타임스텝의 planner action a_{plan_{t-6:t-1}}.
- 가장 중요한 것은, 저수준 스킬 정책인 \pi_{skill}에서 제공하는 피드백 z_t입니다. 이는 \pi_{plan}이 저수준 스킬의 반응을 인지하고 오류를 수정하는 데 도움을 줍니다.
- \pi_{plan}은 3계층 MLP(Multi-Layer Perceptron) 네트워크를 사용하며, ELU(Exponential Linear Unit) 활성화 함수를 가집니다.
- \pi_{plan}의 출력은 7차원 범주형 분포(categorical distribution)로, 여섯 개의 정규 회전 축 (\pm x, \pm y, \pm z) 중 하나와 추가적인 STOP 명령에 해당합니다. 쿼터니언은 네트워크 입력 시 6D representations으로 변환됩니다.
- Residual Actions (a_{rest}): \pi_{plan}은 선택된 회전 축 외에, 저수준 스킬의 출력에 보완적인 잔여 동작(residual action) a_{rest}를 출력합니다. 최종적으로 로봇에게 전달되는 동작은 a_t = a_{rest} + a_{skill_t}입니다. 이 a_{rest}는 planner policy가 low-level skill의 한계를 보완하고 추가적인 오류 보정을 수행할 수 있도록 합니다.
학습 및 보상:
- \pi_{plan}은 시뮬레이터에서 제공되는 ground-truth 객체 상태 q_t를 사용하여 학습됩니다.
- 보상 함수는 r = 1/(d(q_t, q_{goal_t}) + \epsilon) + \lambda_s \mathbb{1}(Success)로 구성됩니다. 여기서 d(q_t, q_{goal_t})는 회전 거리 보상이며, \mathbb{1}(Success)는 성공 보너스입니다. 기존 연구에 비해 보상 함수가 훨씬 단순하며, 이는 저수준 스킬이 이미 잘 튜닝되어 있기 때문에 가능합니다.
Generalizable State Estimator:
- 실제 세계로 정책을 전이하기 위해, 시스템은 강건한 객체 자세 추정기(pose estimator)를 필요로 합니다.
- 제안된 자세 추정기는 신경망 \phi로 구현된 재귀적 상태 추정기(recursive state estimator)입니다.
- 입력은 고유수용성, 동작, 제어 오류, 저수준 스킬 피드백(z_t), 그리고 이전에 추정된 객체 상태 시퀀스입니다.
- \phi는 다음 타임스텝의 객체 상태 \hat{s}_t를 출력합니다.
- 이 추정기는 Transformer 구조를 사용하며, 특징 시퀀스 f_t = [q_t, a_{t-1}, q_t - a_{t-1}, \hat{s}_{t-1}, z_t]를 입력으로 받아 \hat{s}_t를 예측합니다.
- 학습은 시뮬레이션에서 \pi_{plan}을 사용하여 롤아웃(rollout)하며, 예측된 쿼터니언과 ground-truth 쿼터니언 사이의 회전 거리가 0.8 라디안을 초과하거나 예측된 객체 위치가 3cm 이상 벗어나면 에피소드를 리셋하는 방식으로 \ell_2 distance를 최소화합니다.
실험 및 결과:
- 정책 학습 성능: 저수준 스킬을 사용한 계층적 정책은 학습에서 scratch부터 학습하는 baseline 정책보다 8배 더 빠르게 수렴하며, 더 높은 성공률을 달성합니다. 특히 객체 상태 정보에 노이즈가 증가할수록 baseline은 불안정해지고 수렴에 실패하는 반면, 제안된 방법은 안정적인 성능을 유지합니다. 이는 미리 학습된 모델이 탐색 공간을 구조화하고 의미 없는 무작위 행동을 줄여주기 때문입니다.
- Out-of-Distribution Robustness: 제안된 정책은 관측 노이즈, 물리적 무작위화(physical randomizations), 객체 형태 변화와 같은 out-of-distribution 시나리오에서 baseline보다 훨씬 강건함을 보여줍니다.
- Generalizable State Estimation: 학습된 자세 추정기를 사용하여, 시뮬레이션에서 예측된 객체 상태를 바탕으로 실제 세계에 정책을 성공적으로 전이합니다. 제안된 방법은 baseline보다 policy smoothness와 energy metrics에서 우수한 성능을 보여, 더 안정적인 객체 조작을 가능하게 합니다.
- Ablation Experiments:
- Residual Actions 및 Low-Level Skill Feedback: 이 두 요소가 없으면 성능이 크게 저하됩니다. Residual actions는 미세한 오류 보정을 제공하고, z_t를 통한 저수준 스킬 피드백은 \pi_{plan}이 low-level skill의 내부 상태와 객체 속성을 이해하는 데 필수적임을 입증합니다.
- Planner Policy Inputs: 쿼터니언 차이만 사용하는 것부터 시작하여, 객체 위치, 관측 기록, 이전 planner actions, 그리고 고유수용성 정보를 순차적으로 추가하면서 정책 성능이 점진적으로 향상됨을 보여줍니다. 이는 planner와 저수준 스킬 정책 간의 closed-loop feedback의 중요성을 강조합니다.
- 실제 세계 실험: Allegro Hand 로봇을 사용하여 훈련 데이터에 없었던 (out-of-distribution) 6가지 다양한 실제 객체에 대해 성공적인 in-hand reorientation을 시연했습니다. 특히 작은 큐브와 같은 조작하기 어려운 객체에도 잘 일반화되는 모습을 보여주었습니다.
결론 및 한계:
본 연구는 미리 학습된 저수준 스킬을 활용하여 in-hand object reorientation을 위한 계층적 정책을 구축하고, 강건하고 일반화 가능한 상태 추정기를 학습함으로써, 훈련 효율성, 강건성, 일반화 가능성을 크게 향상시킬 수 있음을 입증했습니다. 한계점으로는 저수준 정책의 효과성에 의존하며, 손가락과 객체 사이에 미끄러짐(slipping)이 발생하지 않는다는 가정이 있습니다. 또한, 현재 자세 추정 오차가 시간에 따라 누적될 수 있습니다. 향후 연구로는 촉각 센서(tactile sensing)를 통합하고 시각(vision)과 촉각(touch)을 결합하여 정확하고 장기적인 자세 추적을 가능하게 하는 방향을 제시합니다.
🔔 Ring Review
🔔 Ring — An idea that echoes. Grasp the core and its value.
들어가며: 왜 “다시” 손안 재배향인가
손안 회전(in-hand rotation)은 풀린 줄 알았다. 2022년 HORA가 z축 회전을 손끝만으로 풀고, 2023년 RotateIt이 임의 축으로 확장하면서, 다축 회전 자체는 더 이상 미해결 문제처럼 보이지 않았다. 그런데 같은 그룹(Qi et al., Berkeley/Meta)이 2025년에 또 다른 논문을 내놓았다. 제목은 「From Simple to Complex Skills: The Case of In-Hand Object Reorientation」. 회전(rotation)이 아닌 재배향(reorientation), 즉 목표 자세(target pose)에 도달하는 문제다.
언뜻 보면 작은 차이 같지만, 실제 차이는 크다. “계속 돌리기”와 “정해진 각도에 멈추기”는 RL 입장에서 보면 거의 다른 문제다. 전자는 회전 속도(angular velocity)에 비례한 보상으로 끝없이 돌게 두면 되지만, 후자는 “어디까지 돌렸는지”를 알아야 하고, 어느 순간 멈춰야 하며, 잘못 돌리면 되돌려야 한다. 손안에서 일어나는 일을 “정확히” 알아야 하는 것이다.
이 논문이 흥미로운 이유는 답을 풀어가는 방식이 우아하기 때문이다. 이미 잘 풀린 단순 스킬(축별 회전 정책)을 그대로 두고, 그 위에 얇은 플래너를 얹어 복잡한 작업을 만든다. 보상 엔지니어링과 도메인 랜덤화, 시스템 식별을 새 작업마다 처음부터 다시 깎아야 했던 기존 sim-to-real 워크플로의 인건비 문제를 정면으로 들이받는 셈이다.
Note한 줄 정리
저수준 스킬(축별 in-hand rotation)을 동결시켜 두고, 그 위에 (1) 어느 축으로 돌릴지 고르는 플래너, (2) 잔차 보정 행동을 더하는 잔차 정책, (3) 자세를 추정하는 상태 추정기, 이 세 가지만 새로 학습한다.
문제 설정: 회전과 재배향의 미묘하지만 결정적인 차이
손안 회전 작업은 다음과 같이 쓴다.
\max_\pi \; \mathbb{E}\left[\sum_{t=0}^T r_{\text{rot}}(s_t, a_t)\right], \quad r_{\text{rot}} = \omega_{\text{obj}} \cdot \hat{k}
여기서 \hat{k}는 목표 회전축, \omega_{\text{obj}}는 물체의 각속도다. 즉 “목표 축 방향으로 더 빨리 돌수록 좋다”는 단순한 보상이다. 끝(termination)이 없다.
재배향은 다르다. 시작 자세 q_0에서 목표 자세 q^*까지 가야 한다.
r_{\text{reorient}} = -\,\angle(q_t, q^*) + \mathbb{1}[\angle(q_t, q^*) < \epsilon] \cdot R_{\text{success}}
쿼터니언 거리(angular distance)와 성공 보너스, 두 항으로 끝낸다. 문제는 RL이 \angle(q_t, q^*)를 학습 신호로 받기에는 너무 sparse하고, 더 큰 문제는 손안에서 물체가 어떻게 놓여 있는지 실세계에서 모른다는 점이다. 시뮬레이션에서는 물리 엔진이 자세를 공짜로 알려주지만, 실제 손은 손가락 관절 인코더밖에 없다. 카메라가 있어도 손가락에 가려진다(occlusion).
이게 단순한 RL 문제가 아닌 이유다. 행동 정책과 인식(perception)을 동시에 풀어야 한다.
핵심 아이디어: 단순 스킬 위에 얇은 플래너 한 장
저자들의 접근은 한 마디로 “이미 가진 걸 다시 짜지 말자(don’t reinvent the wheel)”다.
위 그림이 시스템 전부다. 각 블록을 차례로 풀어 본다.
저수준 스킬 \pi_{\text{skill}}: RotateIt을 그대로 가져온다
기반은 RotateIt(Qi et al., CoRL 2023). 입력은 다음과 같이 구성된다.
- 로봇 관절 위치 q_{\text{robot},t}
- 직전 명령 관절 타겟 a_{t-1}
- 손바닥 시점 depth 이미지(경량 CNN으로 인코딩)
- 회전축 명령 \hat{k} (one-hot 또는 unit vector)
이 입력을 Transformer로 처리해 단일 벡터로 압축하고, 두 갈래의 헤드를 단다.
- 정책 헤드: 관절 타겟 출력 a_{\text{skill}}
- 물성 예측 헤드: 물체의 물리적 속성(질량, 마찰, 형상 등) 예측
여기가 핵심 트릭이다. 물성 예측 헤드는 학습에만 쓰는 보조 손실이 아니라, 추론 시 플래너에게 “내가 만지고 있는 물체가 어떤 놈인지”를 알려주는 피드백 신호다. 일반적인 hierarchical RL은 저수준이 “잘 됐는지” 정도만 위로 보내지만, 여기는 저수준이 자신이 만지는 대상의 표현(representation)을 위로 흘려보낸다.
Tip직관
저수준 스킬을 잘 만든 손가락 끝의 감각 뉴런이라고 생각하면 된다. 그 뉴런은 “지금 돌리고 있는 것”의 정체를 어렴풋이 안다. 굳이 위쪽 뇌가 처음부터 다시 추정할 필요가 없다.
플래너 \pi_{\text{plan}}: 축을 고르고 미세 보정을 더한다
플래너의 입력은 다음과 같다.
- 추정된 물체 자세 \hat{p}_t, \hat{q}_t
- 목표 자세 q^*, 또는 상대 회전 \Delta q = q^* \otimes \hat{q}_t^{-1}
- 저수준 스킬의 피드백(물성 예측 임베딩)
- 고유감각 q_{\text{robot},t}
출력은 두 개다.
- 회전축 명령 \hat{k}_t: 6개 후보 축(±x, ±y, ±z) 중 하나를 one-hot으로 선택
- 잔차 행동 a_{\text{res},t}: 관절 공간의 작은 보정
최종 행동은 단순한 합이다.
a_t = \pi_{\text{skill}}(o_t, \hat{k}_t) + \alpha \cdot a_{\text{res},t}
\alpha는 잔차의 크기를 제한하는 스케일링이다. 이 합산 구조는 이전 cascaded compositional residual learning(Kumar et al.)의 전통을 따른다.
Important왜 “축 선택 + 잔차”가 잘 동작하는가
계층적 RL의 고전적 실패 패턴은 저수준 스킬이 깨질 때 위에서 손을 쓸 방법이 없다는 것이다. 저수준이 “쥐고 돌리기”라고 가정했는데 실제로는 미끄러져 떨어지는 중이라면, 위가 “다시 돌려”라고 명령해 봐야 의미가 없다. 잔차 행동은 이 단절을 메운다. 위가 저수준에게 명령을 내릴 뿐 아니라, 직접 손가락 관절을 살짝 움직일 권한도 가진다. 계층을 두되 완전히 격리하지 않는다.
보상의 단순화
보상은 앞에서 본 두 항뿐이다.
r_t = -\angle(\hat{q}_t, q^*) + \mathbb{1}[\angle(\hat{q}_t, q^*) < \epsilon]\,R_{\text{success}}
이게 가능한 이유는 저수준 스킬이 이미 강건하기 때문이다. 떨어뜨림 페널티, 손가락 충돌 페널티, 행동 정규화, 토크 페널티 같은 부가 항을 일일이 튜닝할 필요가 없다. 떨어뜨림은 저수준이 알아서 방지하고, 행동 부드러움은 사전 학습된 정책의 prior에 이미 들어 있다. 위 보상은 “어디로 가야 하는지”만 말해주면 된다.
이게 논문 제목의 함의다. 복잡한 작업의 보상을 단순화하는 가장 좋은 방법은, 단순 작업의 정책을 잘 만들어 두고 그것에 작업을 위임하는 것이다.
자세 추정기: 손가락만으로 손안의 물체를 본다
여기가 이 논문에서 가장 영리한 부분이라고 생각한다. 실세계 배포의 가장 큰 벽이 인식이라는 점을 정면으로 인정하고, 시각이 아닌 고유감각 + 스킬 내부 신호로 자세를 추정하는 별도 네트워크를 만든다.
추정기 입력
추정기 g_\phi는 시간에 따라 자세를 갱신하는 재귀(recurrent) 구조로, 입력은 다음이다.
- 고유감각 q_{\text{robot},t}
- 직전 행동 a_{t-1}
- 제어 오차 e_t = a_{t-1} - q_{\text{robot},t} (명령한 관절 타겟과 실제 도달 위치의 차이)
- 저수준 스킬의 임베딩 z_t = \pi_{\text{skill}}(\cdot)의 중간 표현
- 직전 자세 추정 \hat{q}_{t-1}, \hat{p}_{t-1}
출력은 (\hat{p}_t, \hat{q}_t), 즉 물체의 3D 위치와 단위 쿼터니언 방향이다.
Note왜 제어 오차가 결정적인가
손가락이 어떤 관절 타겟을 명령받았는데 거기까지 못 갔다면, 무언가가 막고 있다. 그 “무언가”가 물체다. 제어 오차의 시계열은 사실상 암묵적 촉각이다. 별도의 촉각 센서 없이도, 명령과 실제의 갭이 접촉 정보를 흘려보낸다. HORA의 rapid motor adaptation도 비슷한 통찰을 썼다.
학습 전략
추정기는 시뮬레이션에서 GT 자세를 감독 신호로 사용해 학습한다. 손실은 다음과 같다.
\mathcal{L}_{\text{pose}} = \|p_t - \hat{p}_t\|_2^2 + d_{\text{quat}}(q_t, \hat{q}_t)
여기서 d_{\text{quat}}은 쿼터니언 거리(예: 1 - |q \cdot \hat{q}|). 학습 시 다양한 물체, 마찰, 질량으로 도메인 랜덤화를 수행해 일반화를 유도한다. 정책 학습과는 분리되어, 별도로 시뮬레이션에서 사전 학습된 다음 정책 학습에 freeze된 상태로 들어간다.
의사 코드
# Pseudocode for one timestep at deployment
def step(t, q_robot, prev_action, hand_state):
# 1. Estimate object pose
e_t = prev_action - q_robot # control error
z_t = skill_embedding(q_robot, prev_action, depth=None)
pose_t = pose_estimator(prev_pose, q_robot, prev_action, e_t, z_t)
# 2. Planner decides axis + residual
axis_logits, a_res = planner(pose_t, goal_pose, z_t, q_robot)
axis = one_hot_argmax(axis_logits) # 6 candidates (+/- x,y,z)
# 3. Low-level skill produces base action
a_skill = skill_policy(q_robot, prev_action, axis)
# 4. Combine
a_t = a_skill + alpha * a_res
# 5. Send to PD controller
send_joint_targets(a_t)
return a_t, pose_t이 의사 코드 한 장이 전체 시스템의 시간 한 스텝이다. 깊이 카메라가 시뮬레이션에서만 사용되거나, 외부 RGB-D로 초기화 단계에만 쓰이는 식으로 운용된다.
시스템 구조 한눈에 보기
flowchart TB
subgraph Inputs["Inputs (per timestep)"]
Q[q_robot]
A_prev[a_t-1]
E[error e_t = a_t-1 - q_robot]
end
subgraph PoseEst["Pose Estimator (RNN)"]
EST[g_phi]
end
subgraph Skill["Low-level Skill - FROZEN"]
TF[Transformer encoder]
H1[Action head a_skill]
H2[Property head z_t]
end
subgraph Planner["High-level Planner"]
MLP[MLP / RNN]
AXIS[axis one-hot]
RES[residual a_res]
end
Inputs --> EST
EST --> POSE[pose_t]
Q --> TF
A_prev --> TF
AXIS --> TF
TF --> H1
TF --> H2
POSE --> MLP
GOAL[goal q*] --> MLP
H2 --> MLP
Q --> MLP
MLP --> AXIS
MLP --> RES
H1 --> SUM[Sum]
RES --> SUM
SUM --> OUT[a_t]
pi_skill은 학습이 끝난 다음에는 freeze되어 그래디언트가 흐르지 않는다. pi_plan과 g_phi만 새 작업마다 학습한다. 이게 sample efficiency를 끌어올리는 핵심이다.

(A) 사전 학습된 스킬 정책 위에 플래너 정책을 얹은 계층 구조. 플래너는 축 선택과 잔차 행동을 출력하고, 스킬 피드백 z_t를 다시 받아 closed-loop을 이룬다. (B) 비교용 from-scratch baseline 정책.
실험: 무엇을 묻고, 무엇이 답인가
실험 설정
| 항목 | 값 |
|---|---|
| 하드웨어 | 4-finger 다지 핸드 (Allegro Hand) + RGB-D 카메라 |
| 시뮬레이터 | IsaacGym (HORA/RotateIt 계열과 동일) |
| 학습 알고리즘 | PPO (high-level planner), pose estimator는 supervised |
| 평가 물체 | 학습 분포 내 + 분포 외(OOD) 형상, 대칭/무텍스처 포함 |
| 비교군 | from-scratch RL, no-residual, no-feedback |
핵심 비교: 처음부터 학습 vs 계층적
논문이 정량적으로 묻는 첫 번째 질문은 단순하다. “굳이 계층 구조를 써야 하나?”
답은 명확하다. 처음부터 학습한 정책은 OOD 물체와 노이즈 조건에서 무너지지만, 계층적 정책은 학습 분포를 벗어난 형상과 마찰 조건에서도 성공률을 유지한다. 학습 곡선상으로도 계층적 정책은 훨씬 빠르게 수렴한다. 사전 학습된 스킬이 탐색 공간을 크게 줄여 주기 때문이다.
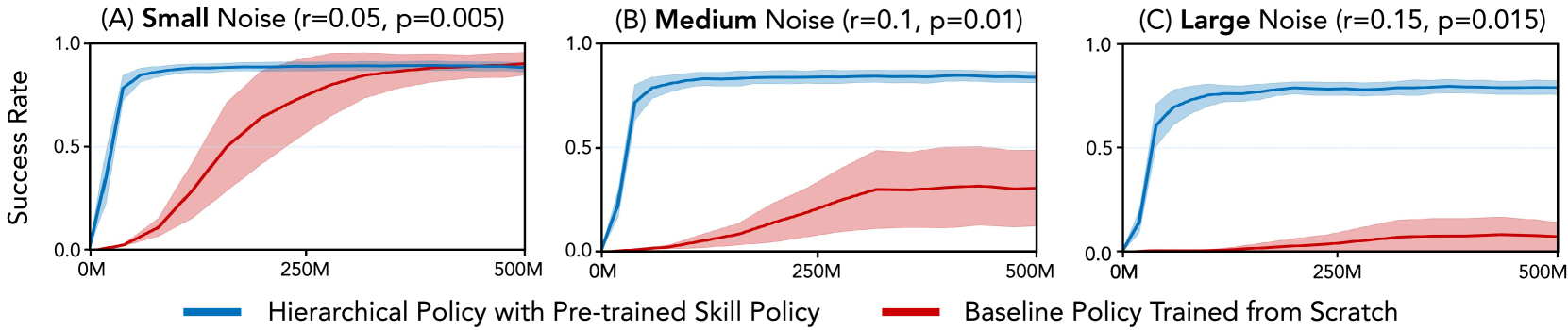
학습 곡선 비교. 관측 노이즈가 커질수록(Small → Large) from-scratch baseline(빨강)은 수렴에 실패하지만, 계층적 정책(파랑)은 빠르고 안정적으로 높은 성공률에 도달한다.
Tip통찰
“잘 학습된 저수준 스킬은 일종의 prior로 작동한다.” 위쪽 정책의 탐색이 의미 있는 행동 분포 안에서만 이뤄진다. 떨어뜨리기, 손가락이 엉키기, 무의미한 관절 떨림 같은 실패 모드를 자동으로 회피한다.
잔차 행동의 효과
residual을 제거한 ablation에서 성공률이 큰 폭으로 떨어진다. 저수준 스킬은 평균적으로 좋지만 모든 자세 전환에서 완벽하지는 않다. 잔차는 그 갭을 메운다. 특히 “거의 다 됐는데 마지막 5도가 부족한” 상황에서 결정적이다.
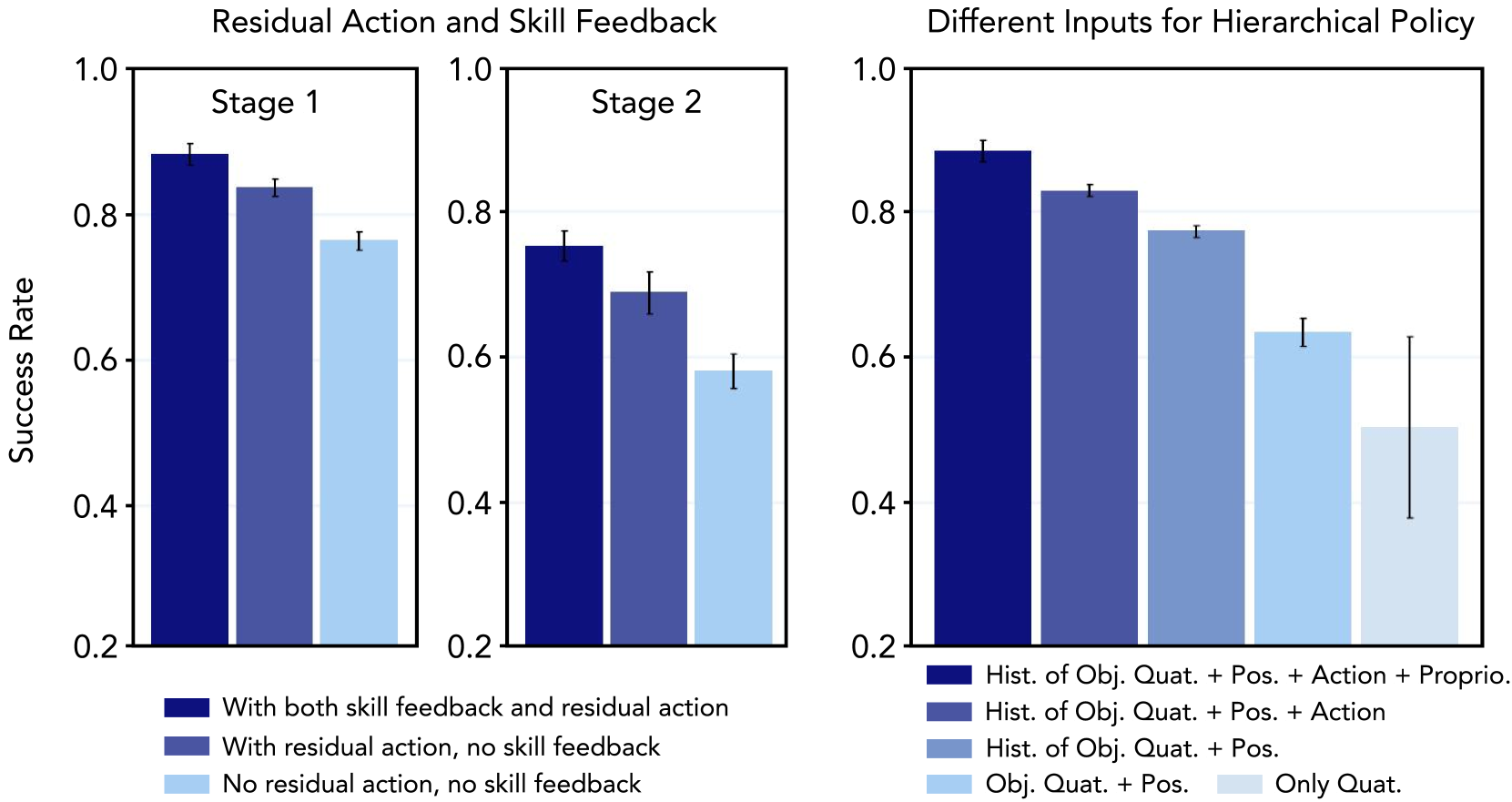
Ablation 결과. (왼쪽) 스킬 피드백과 잔차 행동을 제거할수록 성공률이 단계적으로 하락한다. (오른쪽) 플래너 입력에 객체 위치, 관측 기록, 이전 행동, 고유감각을 차례로 추가하면 성능이 점진적으로 향상된다.
자세 추정기의 일반화
추정기는 학습에 쓰지 않은 신규 물체(코끼리 인형, 단순 큐브, 돼지저금통 등)에 대해서도 사용 가능한 자세 추정을 내놓는다. 무텍스처/대칭 물체에 강하다는 점이 시각 기반 자세 추정 대비 차별점이다. 시각으로는 대칭 큐브의 6개 면을 구분할 수 없지만, 손가락의 접촉 시퀀스는 비대칭이기 때문이다.
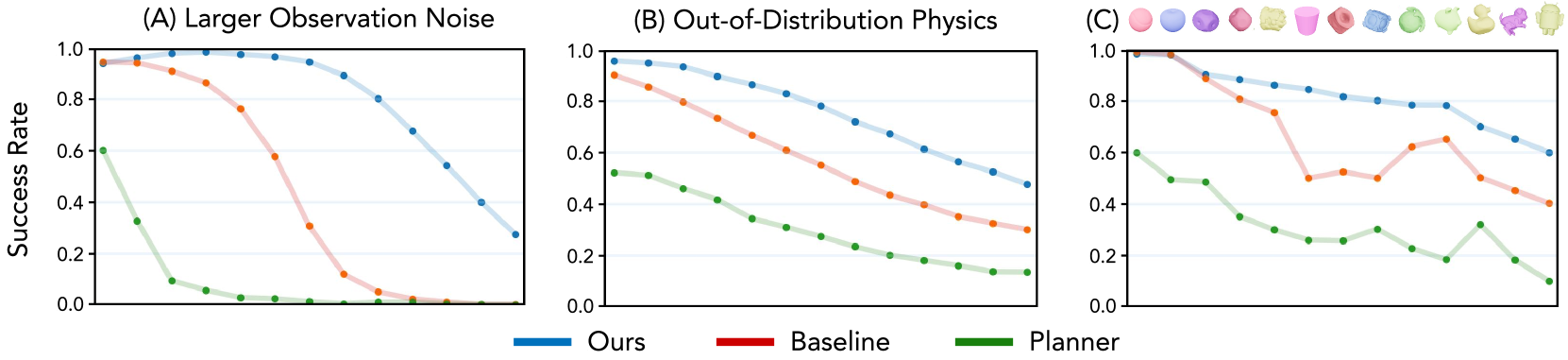
Out-of-distribution 강건성. 관측 노이즈, 분포 외 물리 파라미터, 미지의 객체 형상 모두에서 제안 방법(Ours, 파랑)이 baseline과 planner-only 대비 성공률 저하가 가장 완만하다.
실세계 전이
목표 자세에 도달하는 데 걸리는 시간이 단축되었고, 단일 축으로 도달 가능한 목표뿐 아니라 두 개의 스킬 전환이 필요한 목표(예: -90° z 후 90° y)도 성공시킨다. 영상 결과(dexhier.github.io)에서 사과, 원기둥, 테니스공, 코끼리, 큐브 등의 재배향이 확인된다.

실제 세계 평가에 사용된 분포 외(OOD) 객체들. 텍스처가 거의 없는 소프트 큐브와 작은 큐브, 부드러운 공 등 시각 기반 자세 추정이 어려운 객체에서도 일반화에 성공한다.
비판적 고찰: 무엇이 강하고 무엇이 약한가
강점
(1) 시스템적 우아함 보상을 두 항으로 줄였다. 새 작업마다 손으로 깎던 보상 엔지니어링을 없앴다. 이게 실무자 입장에서 가장 큰 가치다. 도메인 랜덤화도 저수준 학습 단계에서 끝났기 때문에, 새 목표 자세를 추가할 때 시스템 식별을 다시 할 필요가 없다.
(2) 인식과 행동의 분리 (그러나 적절한 결합) 자세 추정기는 별도로 학습되어 정책 학습과 절연된다. 그러나 추정기가 사용하는 신호(저수준 스킬의 내부 임베딩)는 정책과 공유되어 있다. 완전한 모듈화도, 완전한 end-to-end도 아닌 중간 지점을 잘 찾았다.
(3) 잔차 보정의 깔끔한 통합 계층적 RL의 영원한 약점인 “저수준 실패 시 위가 무력함” 문제를 잔차 행동으로 해결한다. 구현 비용이 낮으면서 효과는 크다.
(4) 무텍스처 / 대칭 물체 처리 시각만으로는 자세를 모호하게 만드는 경우(matte 큐브, 균질 표면 공)에도 동작한다. 산업 응용 측면에서 의미 있다. 부품 정렬, 조립 시 흔히 마주치는 조건이기 때문이다.
약점과 의문
(1) 축 후보의 이산화 플래너가 ±x, ±y, ±z 6개 축 중 하나를 고른다. 임의 축 회전이 필요한 자세(예: 대각선 축으로 60° 회전)는 두세 번의 축 전환으로 근사해야 한다. 이론적으로는 잔차가 보정한다지만, 잔차의 크기가 작으면 정밀도가 떨어지고, 크면 저수준 스킬의 prior가 깨진다. 연속 축 선택(continuous axis)으로 확장하는 것이 자연스러운 다음 단계다.
(2) 자세 추정기의 시뮬레이션 의존성 추정기는 시뮬레이션에서 GT 자세로 학습된다. sim-to-real에서 추정기 자체의 drift가 누적될 수 있고, 논문이 정량적으로 추정 오차의 시간 누적을 얼마나 깊이 분석했는지는 제한적이다. 손가락의 마찰 계수가 실세계와 시뮬레이션에서 다르면, 제어 오차의 분포가 어긋나고, 추정기가 잘못된 자세를 자신 있게 보고하는 실패 모드가 가능하다.
(3) 촉각 센서의 부재 HORA / RotateIt 계열은 의도적으로 촉각 센서 없이 고유감각만 쓴다. 깔끔하지만, AnyRotate(Yang et al., CoRL 2024)나 GelSight 통합 연구들은 명시적 촉각이 더 강건한 결과를 낸다. 이 논문도 명시적 촉각을 도입하면 추정기의 일반화가 더 좋아질 여지가 충분하다. 다만 그러면 시뮬레이션 비용이 폭증한다(TACTO, Taxim 통합 필요).
(4) 작업 일반화의 범위 저수준이 “축별 회전”으로 고정되어 있다는 점이 강점이지만 동시에 제약이다. 도구 사용, 삽입, 던지기처럼 회전 외의 다른 스킬이 필요한 작업으로 어떻게 확장될지는 미해결이다. 저수준 스킬 라이브러리를 어떻게 구성하느냐가 다음 라운드의 핵심 질문이 될 것이다.
(5) 평가의 폭 영상으로 보여준 결과는 인상적이지만, 정량적 성공률 통계가 객체 다양성과 목표 자세 다양성 양 축에서 충분히 넓게 보고되었는지는 추가 검증이 필요하다(특히 두 개 이상 스킬 전환이 필요한 케이스).
관련 연구 지도
flowchart LR
HORA["HORA (CoRL '22)<br/>z-axis only<br/>proprioception"] --> RotateIt["RotateIt (CoRL '23)<br/>multi-axis<br/>vision+touch"]
RotateIt --> FSC["From Simple to Complex (2025)<br/>reorientation<br/>hierarchical + pose est."]
VD["Visual Dexterity (Sci.Rob. '23)<br/>D'Claw, full SO(3)<br/>depth only"] -.contrast.-> FSC
AR["AnyRotate (CoRL '24)<br/>4-finger, gravity-invariant<br/>fingertip touch"] -.contrast.-> FSC
OAI["OpenAI Cube/Rubik's<br/>('18, '19)<br/>Shadow Hand, RL"] -.predecessor.-> HORA
FSC --> Future["Open directions:<br/>continuous axis,<br/>tactile fusion,<br/>tool use"]
| 논문 | 핸드 | 작업 | 인식 | 보상 복잡도 |
|---|---|---|---|---|
| HORA (2022) | Allegro | z축 연속 회전 | 고유감각 | 중간 |
| RotateIt (2023) | Allegro | 다축 연속 회전 | 비전+촉각 | 중간 |
| Visual Dexterity (2023) | D’Claw | full SO(3) 재배향 | depth | 높음 (다항) |
| AnyRotate (2024) | 4-finger | 임의 축, 임의 손 방향 | fingertip touch | 중간 |
| 본 논문 (2025) | Allegro | 목표 자세 재배향 | 고유감각 + 추정기 | 낮음 (2항) |
핵심 비교는 Visual Dexterity와의 대조다. Visual Dexterity는 단일 정책으로 full SO(3) 재배향을 끝낸다(end-to-end + 정교한 보상). 본 논문은 보상은 단순한 대신 계층 구조를 도입한다. 둘 다 같은 목적지(임의 자세 재배향)에 다른 길로 도달한다. 어느 길이 “옳다”기보다 어느 길이 새 작업으로 확장될 때 추가 비용이 적은가의 질문이다. 본 논문 쪽 답이 “low-level skill을 한 번 잘 만들어 두면 그 다음은 싸다”이고, 이 답이 산업 현장에는 더 매력적이다.
실무 관점에서 가져갈 만한 통찰
Allegro Hand 기반 연구를 하는 입장에서 이 논문의 시사점을 정리하면 다음과 같다.
- 저수준 스킬은 다시 만들지 말고 재사용한다. 이미 학습된 RotateIt 정책을 freeze해서 새 작업의 prior로 쓰는 접근은 비용 대비 효과가 매우 크다. 특히 자체 학습 인프라 비용이 큰 상황에서 결정적이다.
- 보상 복잡도와 sim-to-real 비용은 비례한다. 보상 항을 늘릴수록 시뮬레이션 튜닝 사이클이 길어지고 실세계 전이도 어려워진다. 계층 구조는 보상 단순화의 도구다.
- 자세 추정에서 고유감각 + 제어 오차 신호의 위력. 카메라가 가려지는 손안 작업에서, 명령-실제 갭 시계열은 거의 공짜로 얻는 강력한 신호다. 명시적 촉각 센서 도입 전에 이 신호를 먼저 끝까지 짜내는 것이 합리적이다.
- 잔차 행동은 hierarchical RL의 단절을 메우는 보편적 처방. 도메인을 옮겨도 거의 그대로 쓸 수 있다. locomotion, manipulation 어느 쪽이든.
- 무텍스처/대칭 물체에 강하다는 점은 산업적으로 중요하다. 실제 부품 정렬, 조립 작업의 객체는 텍스처가 거의 없고 대칭성이 높다. 시각 only 접근의 약점이 명확히 노출되는 지점이며, 여기가 본 논문이 차별화되는 영역이다.
마무리
이 논문이 보여주는 건 새로운 알고리즘이라기보다 새로운 작업 분해 방식이다. 회전 정책을 다시 학습하지 않는다. 보상을 정교하게 깎지 않는다. 촉각 센서를 추가하지 않는다. 대신 이미 가진 것을 영리하게 재배치한다. 계층, 잔차, 자세 추정기, 이 세 가지 부품의 조합이 그 결과다.
가장 인상적인 부분은 자세 추정기다. 카메라 없이, 촉각 센서 없이, 단지 손가락 관절의 명령과 실제의 차이만으로 손안 물체의 자세를 추정한다는 발상은 직관적이면서 강력하다. 로봇이 자기 몸의 한계(오차)를 외부 세계의 정보로 변환한다는 점에서, 이 추정기는 단순한 엔지니어링이 아니라 작은 인식론적 아이디어를 담고 있다.
다음 단계는 명확하다. 연속 축 선택, 더 다양한 저수준 스킬 라이브러리(쥐기, 슬라이딩, 던지기), 명시적 촉각 통합. 그리고 가장 중요하게는, “회전” 너머의 작업으로 같은 분해 패턴이 확장되는지를 보이는 일이다. 그게 가능하다면, dexterous manipulation에서 새 작업의 sim-to-real 비용이 한 자릿수로 떨어지는 시대가 오고 있는 셈이다.